One-Line Summary: Tree-of-Thought extends chain-of-thought reasoning by exploring multiple reasoning paths simultaneously in a branching tree structure, enabling backtracking from dead ends and systematic search for the best solution -- treating reasoning as a search problem rather than a linear narrative.
Prerequisites: Understanding of chain-of-thought (CoT) prompting and why step-by-step reasoning improves LLM performance, familiarity with search algorithms (breadth-first search, depth-first search, beam search), awareness of test-time compute as a scaling axis, basic understanding of how LLMs generate text autoregressively.
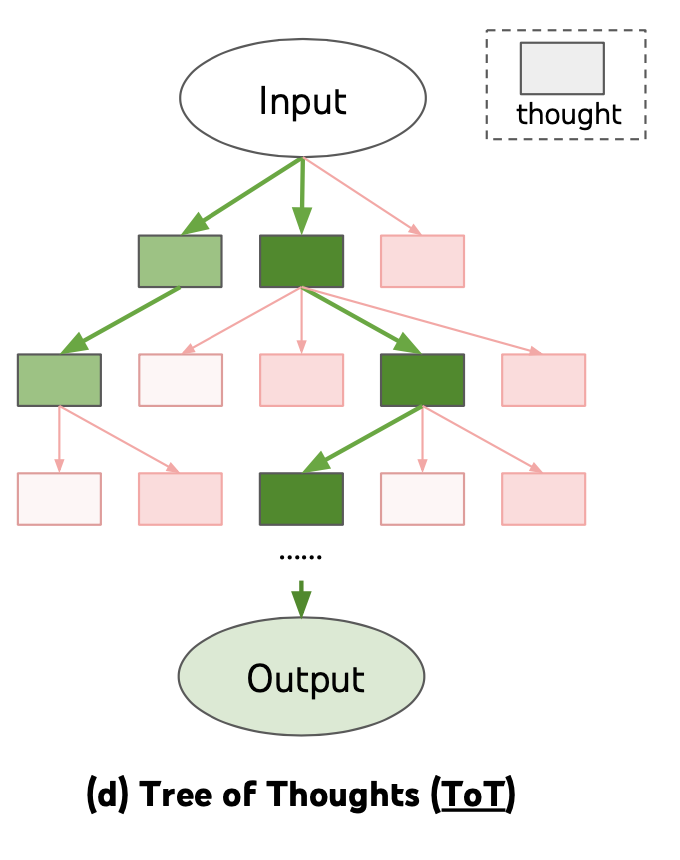
What Is Tree-of-Thought?
Imagine solving a complex puzzle. With chain-of-thought, you think step by step along a single path: "First I'll try this... then this... then this..." If you make a wrong turn three steps in, you are stuck -- you have committed to a path, and the remaining reasoning builds on a flawed foundation. You cannot go back.
 Source: Lilian Weng – Prompt Engineering
Source: Lilian Weng – Prompt Engineering
Now imagine solving the same puzzle with a pencil that has an eraser. At each step, you consider multiple options, tentatively explore each one, evaluate which looks most promising, and erase the unpromising paths. If a path leads to a dead end, you backtrack and try a different branch. This is Tree-of-Thought.
Standard CoT produces a single linear reasoning chain. ToT produces a tree of reasoning chains, where each branch represents a different choice at a decision point. The system evaluates intermediate states to prune unpromising branches and allocates more exploration to promising ones. The final answer comes from the best path through the tree, not from a single committed chain.
This transforms the reasoning problem from "generate one good chain" (which requires getting every step right on the first try) to "search for a good chain" (which tolerates mistakes as long as they are detected and corrected).
How It Works
flowchart LR
subgraph L1["Comparison of Chain-of-Thought (linear)"]
LI3["and Tree-of-Thought (branching)"]
end
subgraph R2["Self-Consistency (parallel)"]
RI4["Feature 1"]
endThe Framework
ToT operates in four stages:
1. Thought Decomposition
The problem is broken into intermediate "thought steps," where each step is a coherent chunk of reasoning. The granularity of these steps is task-dependent:
- For a math problem: each thought might be one equation or transformation
- For creative writing: each thought might be a paragraph plan or plot development
- For code generation: each thought might be a function design or algorithmic choice
2. Thought Generation
At each step, the LLM generates multiple candidate thoughts (branches). Two strategies:
- Sample: Generate k independent samples from the LLM for the next step. Better for tasks with diverse possibilities.
- Propose: Prompt the LLM to generate a list of distinct candidate steps in a single call. Better when candidates should be explicitly different from each other.
Example at step 2 of a math problem:
Branch A: "Substitute x = 3y into equation 2..."
Branch B: "Rearrange equation 1 to isolate y..."
Branch C: "Add equation 1 and equation 2 to eliminate x..."3. State Evaluation
Each intermediate state (the reasoning so far along a branch) is evaluated to estimate how promising it is. Two approaches:
- Value: The LLM is prompted to rate the state on a scale (e.g., "sure / likely / impossible") or assign a numerical score. Acts as a heuristic function for the search.
- Vote: The LLM is shown multiple states and asked to vote on which is most promising. Useful for comparative evaluation.
Evaluation prompt: "Given the problem [X] and the reasoning so far [Y],
assess whether this reasoning path is:
(a) sure to lead to a correct solution
(b) likely to lead to a correct solution
(c) unlikely to lead to a correct solution"4. Search Algorithm
A search algorithm explores the tree, using the evaluations to guide exploration:
-
Breadth-First Search (BFS): At each depth level, generate all candidate thoughts for all current states, evaluate them, and keep only the top-b states (beam search). Good for problems where early mistakes are fatal and you need to explore broadly at each level.
-
Depth-First Search (DFS): Explore one branch deeply, evaluate, and backtrack if the evaluation drops below a threshold. Good for problems where you want to reach a solution quickly and can reliably detect dead ends.
BFS with beam width 3 on a 3-step problem:
Step 0: [Root]
Step 1: Generate 5 candidates → evaluate → keep top 3: [A, B, C]
Step 2: Generate 5 candidates for each → evaluate → keep top 3: [A2, B1, C3]
Step 3: Generate 5 candidates for each → evaluate → select best: [B1-4]Concrete Example: "Game of 24"
The Game of 24 benchmark (use four numbers and basic arithmetic to make 24) illustrates ToT's power:
Problem: Use 4, 9, 10, 13 to make 24.
CoT approach (single chain): "13 - 9 = 4. 4 + 4 = 8. 10 - 8 = 2. That gives 2, not 24. Hmm..." (Gets stuck, no way to recover)
ToT approach (multiple branches):
Branch 1: "13 - 9 = 4" → evaluate → promising
Branch 2: "10 - 4 = 6" → evaluate → promising
Branch 3: "13 + 9 = 22" → evaluate → promising
Branch 2 continues: "6 * (13 - 9) = 24" → evaluate → correct!ToT achieved 74% success on Game of 24, compared to 4% for standard CoT.
Self-Consistency as a Simpler Alternative
Self-consistency (Wang et al., 2023) can be viewed as a simplified ToT: generate multiple independent CoT chains and take the majority vote on the final answer. It does not use intermediate evaluation or backtracking but captures some of the benefit of exploring multiple paths. Self-consistency is much simpler to implement but less powerful for problems requiring strategic exploration.
Why It Matters
ToT represents a paradigm shift in how we think about LLM problem-solving:
-
Recoverable reasoning: Standard CoT commits to each reasoning step as it generates it. ToT can explore, evaluate, and backtrack, making it robust to the occasional bad reasoning step that would derail a linear chain.
-
Strategic exploration: For problems with a large space of possible approaches (puzzles, planning, creative tasks), ToT can systematically explore alternatives rather than hoping the first approach works.
-
Test-time compute: ToT is a concrete mechanism for investing more computation at inference time to improve accuracy. More branches, deeper search, and more evaluations all trade compute for quality -- a different scaling axis than model size.
-
Toward deliberative reasoning: ToT moves LLM reasoning closer to how humans approach difficult problems: consider alternatives, evaluate options, and change course when things are not working. This connects to broader research on System 2 thinking in AI.
Key Technical Details
- LLM calls per problem: ToT requires many more LLM calls than standard CoT. For a tree with branching factor b, depth d, and evaluation at each node, the number of calls is approximately O(b^d). This makes ToT expensive and motivates careful trade-offs between search depth/breadth and cost.
- Evaluation quality is critical: The search is only as good as the evaluation heuristic. If the LLM cannot reliably distinguish promising from unpromising intermediate states, the search degenerates into random exploration. Tasks where intermediate progress is easy to assess (math, puzzles) benefit most from ToT.
- Prompt engineering overhead: ToT requires designing thought decomposition, generation prompts, and evaluation prompts for each task. This is more complex than standard CoT prompting.
- Parallelizability: Unlike sequential CoT, ToT branches can be evaluated in parallel across multiple LLM calls, reducing wall-clock time if API rate limits permit.
- Integration with external verifiers: For domains with formal verification (math, code), external tools can replace or supplement LLM-based evaluation, providing more reliable branch pruning.
Common Misconceptions
- "ToT is just generating multiple answers and picking the best one." That is self-consistency, not ToT. ToT evaluates and prunes at intermediate steps, not just at the end. This allows it to avoid wasting computation on paths that are clearly wrong early on.
- "ToT works well for all tasks." ToT provides the most benefit for tasks with clear intermediate states, meaningful evaluation criteria, and large solution spaces. For simple factual questions or tasks where the first CoT attempt is usually correct, ToT adds cost without proportional benefit.
- "ToT replaces chain-of-thought." ToT builds on CoT -- each branch is itself a chain of thought. ToT adds the search structure around CoT, not instead of it.
- "ToT requires a separate evaluation model." The same LLM that generates thoughts also evaluates them, using different prompts. No additional model is needed, though specialized verifiers can improve evaluation quality.
- "More branches and deeper search always help." There are diminishing returns, and poorly calibrated evaluation can make wider search counterproductive (exploring more bad paths). The optimal search configuration depends on the task and the model's evaluation reliability.
Connections to Other Concepts
chain-of-thought-in-agents.md: ToT is a direct extension of CoT, adding search and evaluation around the linear reasoning process. Understanding CoT is prerequisite to understanding ToT.test-time-compute.md: ToT is one of the primary mechanisms for spending more compute at inference time to improve accuracy. It instantiates the test-time compute paradigm for reasoning tasks.process-reward-models.md: PRMs evaluate intermediate reasoning steps, which is exactly the evaluation function ToT needs. PRMs can replace or supplement the LLM's self-evaluation for more reliable branch pruning.reasoning-models.md: OpenAI's reasoning models likely use ToT-like internal search processes (the details are proprietary). The reasoning traces that o1/o3 produce suggest exploration of multiple paths with evaluation and selection.self-consistency.md: A simplified version of ToT that generates multiple independent chains and votes on the final answer, without intermediate evaluation or backtracking.compound-ai-systems.md: ToT is a compound system pattern -- multiple LLM calls coordinated by a search algorithm to achieve better results than a single call.
Further Reading
- Yao et al., "Tree of Thoughts: Deliberate Problem Solving with Large Language Models" (2023) -- the original ToT paper, demonstrating the framework on Game of 24, creative writing, and crossword puzzles.
- Wang et al., "Self-Consistency Improves Chain of Thought Reasoning in Language Models" (2023) -- the self-consistency paper that established the simpler "sample multiple chains and vote" approach.
- Long, "Large Language Model Guided Tree-of-Thought" (2023) -- an alternative ToT formulation using a single LLM prompt to manage the tree, rather than external search algorithms.
- Besta et al., "Graph of Thoughts: Solving Elaborate Problems with Large Language Models" (2023) -- extends ToT from trees to general graphs, allowing merging of reasoning paths and more flexible exploration structures.