One-Line Summary: Model routing dynamically selects which LLM to use for each query based on estimated complexity and cost, achieving 40-60% cost reduction while maintaining quality by sending only hard queries to expensive frontier models.
Prerequisites: LLM inference costs, embedding models, classification, cascading systems, reward models
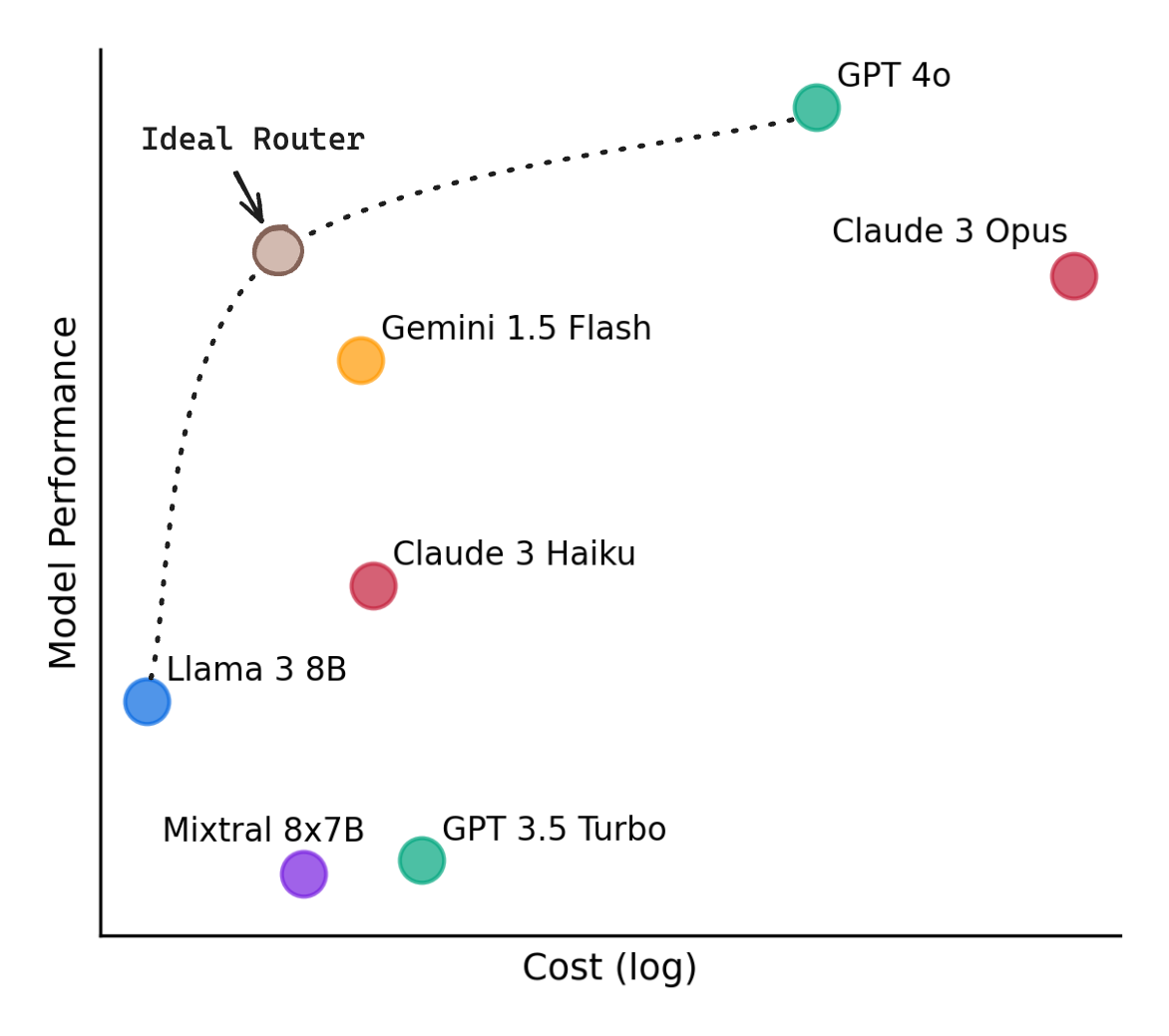
What Is Model Routing?
Imagine a hospital triage system. Not every patient needs a brain surgeon -- most can be treated by a general practitioner, and only the most complex cases get escalated to specialists. Model routing applies this same principle to LLM inference: a lightweight decision layer examines each incoming query and routes it to the cheapest model capable of producing a good answer. Simple factual questions go to a small, fast model; nuanced reasoning tasks get sent to a frontier model.
 See diagram at: RouteLLM GitHub Repository (LMSys)
See diagram at: RouteLLM GitHub Repository (LMSys)
This matters because frontier models like GPT-4 and Claude Opus can be 10-100x more expensive per token than smaller models like GPT-4o-mini or Claude Haiku. Yet empirical studies consistently show that 40-60% of real-world queries do not require frontier-level capability. A customer asking "What are your store hours?" does not need the same model as one asking "Analyze the tax implications of this corporate restructuring across three jurisdictions." Routing exploits this variance in query difficulty to dramatically cut costs without sacrificing quality on the queries that actually need it.
The challenge is building a routing mechanism that is fast (sub-millisecond to low-millisecond overhead), accurate (correctly identifying which queries need which tier), and adaptive (learning from feedback to improve over time). Several approaches have emerged, from simple classifiers to sophisticated cascading systems with learned stopping criteria. The field has matured rapidly, with production-ready frameworks now available from both research labs and commercial providers.
How It Works
See FrugalGPT cascading architecture diagram showing learned stopping criteria across model tiers at: FrugalGPT Paper (arXiv:2305.05176)
Classifier-Based Routing
The most straightforward approach trains a binary or multi-class classifier to predict which model should handle a query. The classifier takes the query text (or its embedding) as input and outputs a routing decision:
query -> Classifier -> "easy" -> Route to GPT-4o-mini ($0.15/1M tokens)
-> "medium" -> Route to Claude Sonnet ($3/1M tokens)
-> "hard" -> Route to GPT-4/Claude Opus ($15/1M tokens)RouteLLM (from LMSys) trains such classifiers on preference data from Chatbot Arena, where human judges have compared model outputs head-to-head on thousands of queries. The classifier learns to predict when the cheaper model's response would be rated equally to the expensive model's response. RouteLLM supports multiple classifier architectures:
- BERT-based classifier: Fine-tuned BERT predicts routing decision from query text
- Matrix factorization: Learns latent representations of queries and models, routing based on predicted preference scores
- Causal LLM classifier: A small causal LM fine-tuned on preference data
RouteLLM achieves 2x cost reduction while maintaining 95% of the quality of always using the frontier model.
Semantic / Embedding-Based Routing
Semantic Router (from Aurelio AI) uses embedding similarity for ultra-fast routing. Predefined route categories are represented as clusters of embedding vectors. At inference time, the query is embedded and routed to the nearest cluster via cosine similarity. This approach achieves sub-millisecond routing latency and requires no LLM calls for the routing decision itself.
# Pseudocode for semantic routing
routes = {
"simple_qa": [embed("What is X?"), embed("Define Y"), ...],
"complex_reasoning": [embed("Compare and contrast..."), embed("Analyze the implications...")],
}
query_embedding = embed(user_query)
selected_route = argmax(cosine_similarity(query_embedding, route_centroids))
model = route_to_model_mapping[selected_route]The key advantage is latency: embedding computation takes <1ms with optimized inference, making the routing decision effectively free compared to the LLM generation time. The limitation is expressiveness -- predefined clusters may not capture nuanced difficulty distinctions.
Cascading / Escalation Routing
Rather than making a single routing decision upfront, cascading approaches start with the cheapest model and escalate only if the response quality is deemed insufficient:
FrugalGPT implements learned cascading with a stopping criterion. Each query first goes to the cheapest model. A learned scoring function (a small DistilBERT model) evaluates the response; if the score exceeds a threshold, the response is returned. Otherwise, the query escalates to the next-tier model. FrugalGPT achieves up to 98% cost reduction on queries where the cheapest model suffices, with overall cost savings of 40-70% at matched quality.
AutoMix uses a few-shot self-verification approach: after a smaller model generates a response, the system prompts the same or a slightly larger model to verify whether the answer is likely correct. The verifier uses 3-5 few-shot examples of correct and incorrect responses to calibrate its confidence. Escalation happens only on low-confidence verifications.
LLM-Based and Reward-Model Routing
More sophisticated approaches use an LLM or reward model to assess query difficulty:
- LLM-based: A small LLM examines the query and predicts its difficulty or the required capability level. This is more expressive than embedding similarity but adds 100-500ms of latency for the routing decision itself.
- Reward-model-based: A reward model scores candidate responses from the cheaper model. If the score is below a threshold, the query is re-routed to a more capable model. This is the most accurate but also the most expensive routing mechanism, as it requires actually generating a response before making the routing decision.
These approaches are best suited for high-value queries where the additional routing latency is justified by significant quality improvements.
Hybrid and Production Architectures
In practice, production routing systems often combine multiple approaches in a layered architecture:
See Semantic Router embedding-based routing diagram at: Semantic Router GitHub Repository (Aurelio AI)
- First layer (semantic): Sub-millisecond embedding-based routing handles obvious cases -- clearly simple queries go directly to the cheapest model, clearly complex queries go directly to the frontier model.
- Second layer (classifier): Ambiguous queries that fall near the decision boundary get evaluated by a more accurate classifier-based router.
- Third layer (cascade): For the most uncertain cases, a cascading approach generates a response from the cheaper model and evaluates quality before potentially escalating.
This layered design ensures that the majority of queries are routed quickly while difficult edge cases get the most careful treatment. Monitoring and logging at each layer provide feedback data for continuous improvement of routing accuracy.
Why It Matters
- Dramatic cost reduction: 40-60% of queries can be handled by models that cost 10-100x less than frontier models, translating to 50-70% cost savings at matched quality levels.
- Latency optimization: Smaller models respond faster, so routing easy queries to them reduces median latency even as frontier-model latency for hard queries remains unchanged.
- Quality preservation: Unlike uniformly downgrading to a cheaper model, routing maintains frontier-level quality on the queries that actually need it.
- Graceful scaling: As cheaper models improve over time, the router automatically sends more traffic to them, capturing cost savings without manual threshold adjustment.
- Provider diversification: Routing across multiple providers (OpenAI, Anthropic, open-source) reduces vendor lock-in and improves resilience to outages.
Key Technical Details
- RouteLLM: trained on ~200K Chatbot Arena comparisons, supports multiple classifier architectures (BERT, matrix factorization, causal LLM), achieves 2x cost reduction at 95% quality
- FrugalGPT: cascading through up to 3 model tiers with learned stopping, up to 98% cost savings on easy queries, ~50% average savings
- Semantic Router: sub-millisecond routing via precomputed embedding centroids, no LLM calls for routing decisions
- AutoMix: few-shot verifier with 3-5 verification examples, ~80% accuracy on escalation decisions
- Typical routing overhead: <5ms for classifier-based, <1ms for embedding-based, 100-500ms for LLM-based
- Routing accuracy improves with domain-specific training data; general-purpose routers work but domain-specific ones can achieve 10-15% better cost/quality tradeoffs
- Cost modeling must account for both input and output tokens, as some queries generate much longer responses than others
- Cascading adds latency on escalated queries (sum of all attempted models), so it works best when escalation rates are low (<20%)
- The cost-quality Pareto frontier is application-specific: safety-critical applications tolerate less aggressive routing than general chatbots
- Routing decisions can incorporate metadata beyond the query text: user tier, session history, task type labels
Common Misconceptions
- "Routing always adds significant latency." Embedding-based and classifier-based routers add sub-millisecond to single-digit millisecond overhead -- negligible compared to LLM generation latency of hundreds of milliseconds to seconds.
- "You need labeled difficulty data to train a router." RouteLLM demonstrates that preference comparison data (which model produced the better response) is sufficient. You do not need explicit difficulty labels.
- "A single quality threshold works for all use cases." Optimal routing thresholds are highly application-dependent. A customer support chatbot may tolerate more aggressive routing to cheap models than a medical diagnosis assistant. Thresholds should be tuned on domain-specific evaluation sets.
- "Routing is only about cost." Routing also optimizes for latency, rate limits, and provider reliability. Some routers factor in current API response times and error rates alongside cost and quality.
- "Simple heuristic rules work just as well." While keyword-based rules (e.g., "if query contains 'code', use GPT-4") work in narrow cases, learned routers consistently outperform heuristics because query difficulty depends on subtle semantic features, not surface patterns.
Connections to Other Concepts
multi-lora-serving.md: Routing can select among LoRA adapters on a shared base model, combining model-level routing with adapter-level specialization.prompt-compression.md: Compression reduces cost per query; routing reduces cost by selecting cheaper models. The two techniques compose multiplicatively.process-reward-models.md: Reward-model-based routing repurposes RLHF reward models as quality estimators for routing decisions.mixture-of-experts.md: Model routing is conceptually similar to MoE gating, but operates at the system level (choosing between separate models) rather than the layer level (choosing between expert FFN blocks).inference-time-scaling-laws.md: Routing can allocate more inference compute (better model, more samples, longer CoT) to harder queries, implementing a form of adaptive compute allocation.speculative-decoding.md: Both routing and speculative decoding optimize inference cost by using cheaper computation where possible, escalating to expensive computation only when needed.
Further Reading
- Ong, I., Almahairi, A., Wu, V., Chiang, W.-L., Wu, T., Gonzalez, J. E., Kadous, M. W., & Stoica, I. (2024). "RouteLLM: Learning to Route LLMs with Preference Data." arXiv:2406.18665.
- Chen, L., Zaharia, M., & Zou, J. (2023). "FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance." arXiv:2305.05176.
- Aurelio AI. (2024). "Semantic Router: Superfast Decision-Making Layer for LLMs." https://github.com/aurelio-labs/semantic-router.
- Madaan, A., Aggarwal, P., Anand, A., Potdar, S., Zhou, S., & Yang, D. (2024). "AutoMix: Automatically Mixing Language Models." arXiv:2310.12963.
- Shnitzer, T., Ou, A., Silva, M., Soule, K., Sun, Y., Solomon, J., Thompson, N., & Yurochkin, M. (2023). "Large Language Model Routing with Benchmark Datasets." arXiv:2309.15789.