One-Line Summary: Mixture of Experts is an architecture that replaces the dense feed-forward network with multiple parallel "expert" networks and a learned router that selects only a small subset of experts for each token, enabling models with vastly more parameters while keeping per-token computation constant.
Prerequisites: Understanding of feed-forward networks in Transformers, the concept of model parameters vs. compute (FLOPs), and why larger models generally perform better.
What Is Mixture of Experts?
Imagine a hospital where every patient sees every specialist -- cardiologist, neurologist, dermatologist, orthopedist -- regardless of their condition. That would be absurdly expensive and wasteful. Instead, a triage nurse (the router) evaluates each patient and sends them to the relevant 1-2 specialists (the experts). The hospital can employ 100 specialists but each patient only consumes the time of 2.
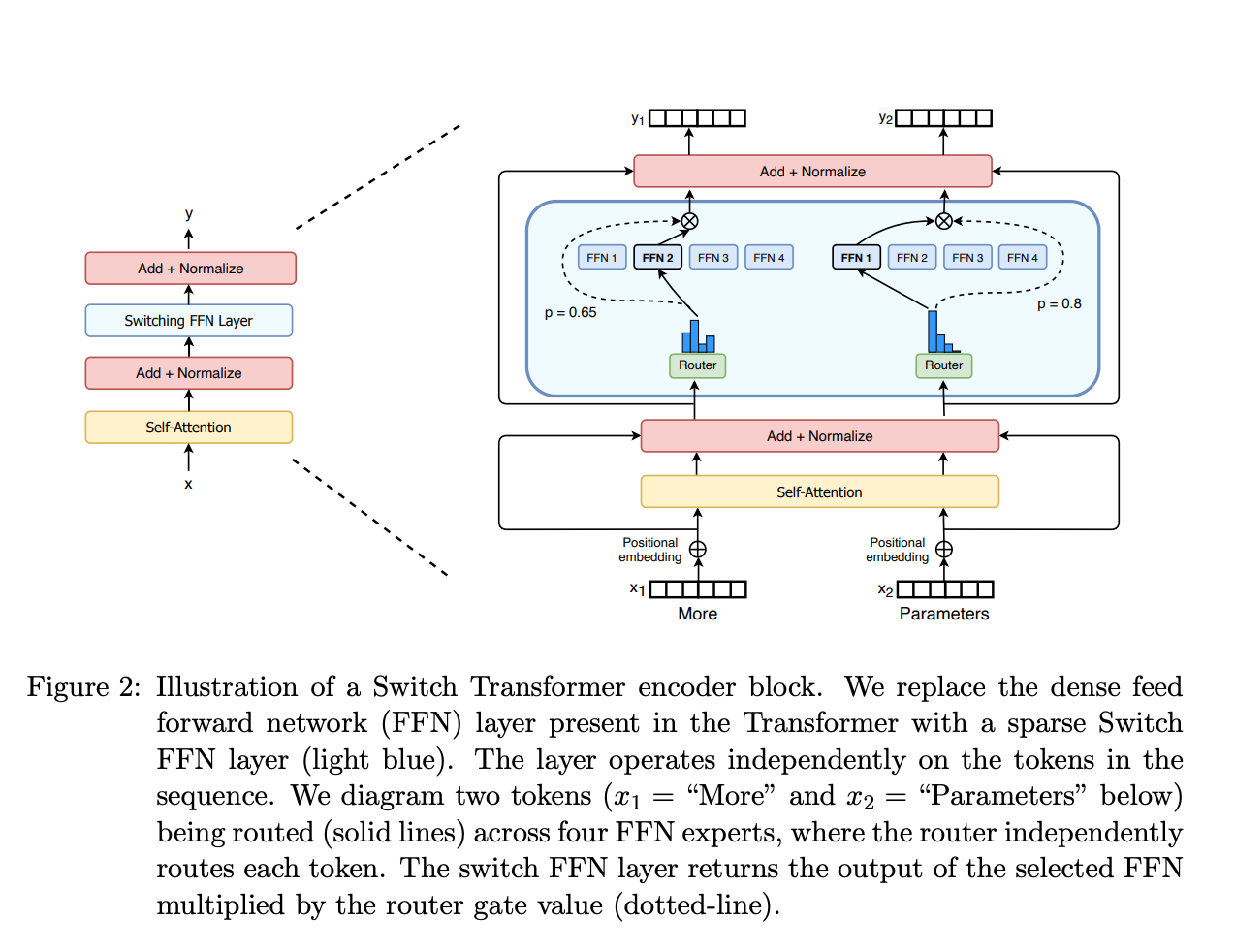 Source: Mixture of Experts Explained -- Hugging Face Blog
Source: Mixture of Experts Explained -- Hugging Face Blog
Mixture of Experts (MoE) applies this same logic to neural networks. Instead of one large feed-forward network (FFN) that processes every token, an MoE layer contains multiple FFNs (experts) and a gating network (router) that decides which experts each token should be sent to. Typically, only 1-2 experts are activated per token, so the computation cost remains similar to a dense model with a single FFN, while the total parameter count is multiplied by the number of experts.
This is the principle of conditional computation: different parts of the network are activated for different inputs. Not every parameter participates in every forward pass.
How It Works
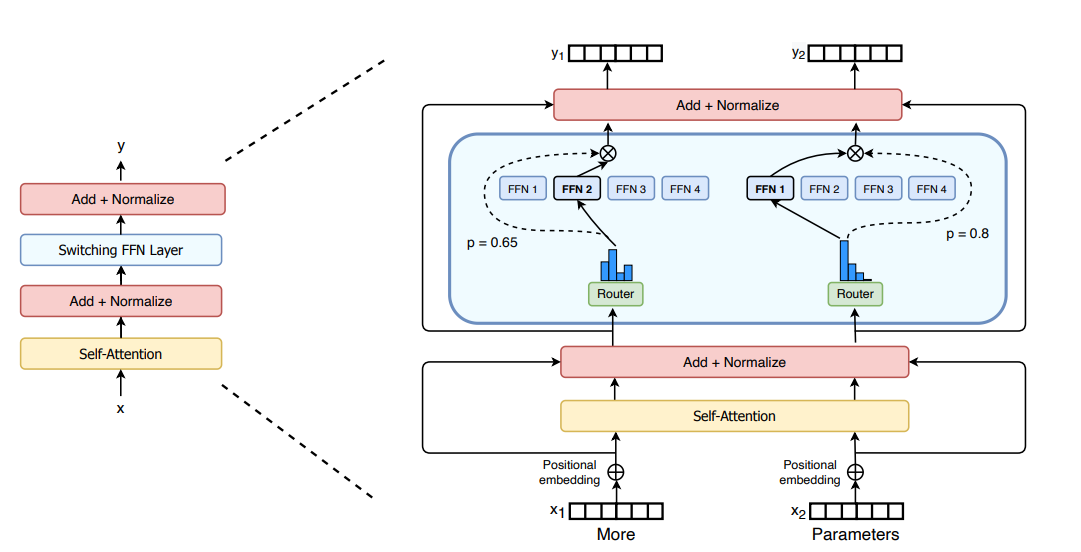 Source: Mixture of Experts Explained -- Hugging Face Blog
Source: Mixture of Experts Explained -- Hugging Face Blog
The MoE Layer (Replacing the FFN)
In a standard Transformer block:
x -> Attention -> FFN -> outputIn an MoE Transformer block:
x -> Attention -> MoE Layer (Router + N Experts) -> outputThe MoE layer replaces the single FFN with expert FFNs and a router.
Step 1: The Router (Gating Network)
Given a token representation , the router computes a score for each expert:
where is the router's weight matrix and TopK selects the highest-scoring experts (typically or ), setting all other scores to before softmax.
The router is extremely lightweight -- just a single linear layer followed by top-k selection and softmax. Its output is a sparse vector of weights over the experts, with only non-zero entries.
Step 2: Expert Computation
Each selected expert processes the token independently:
Each expert is a standard FFN (or SwiGLU FFN in modern models) with its own independent parameters.
Step 3: Weighted Combination
The MoE layer output is the weighted sum of the selected experts' outputs:
where is the router weight for expert . Only the top-k experts contribute; all others have zero weight.
The Full Picture
For a model with experts and (top-2 routing):
- The router selects 2 of 8 experts for each token.
- The model has 8x the FFN parameters of a dense model.
- Each token uses only 2x the FFN computation of a dense model (actually 2x the FFN compute, but the FFN is typically ~2/3 of total compute, so the overall increase is moderate).
- Different tokens in the same sequence can be routed to different experts.
 Source: Mixture of Experts -- Wikipedia
Source: Mixture of Experts -- Wikipedia
Why It Matters
More Parameters Without More Compute
The fundamental insight of MoE is decoupling parameter count from computation cost. Scaling laws show that larger models (more parameters) perform better. But more parameters normally means more computation per token. MoE breaks this link:
| Property | Dense 7B Model | MoE 8x7B Model (e.g., Mixtral) |
|---|---|---|
| Total parameters | 7B | ~47B (8 expert FFNs + shared attention) |
| Active parameters per token | 7B | ~13B (attention + 2 of 8 experts) |
| FLOPs per token | Proportional to 7B | Proportional to ~13B |
| Quality | Good | Significantly better |
Mixtral 8x7B achieves performance comparable to dense models 2-3x its active parameter count. This is the "free lunch" of MoE: better quality at similar (not identical) inference cost.
Inference Efficiency Challenges
MoE is not without trade-offs. While FLOPs per token are controlled, memory requirements are not:
- All expert FFNs must be stored in GPU memory, even though only are used per token.
- The total model size (and memory footprint) scales with the number of experts.
- This creates challenges for deployment, especially on consumer hardware.
Load Balancing: The Central Challenge
A critical problem: the router might learn to send all tokens to just 1-2 "favorite" experts, leaving the rest unused. This expert collapse wastes parameters and defeats the purpose of having multiple experts.
Solutions include:
Auxiliary load-balancing loss: An additional loss term that penalizes uneven expert utilization:
where is the fraction of tokens routed to expert and is the average router probability for expert . This loss encourages the router to distribute tokens evenly.
Expert capacity: Set a maximum number of tokens each expert can process per batch. Tokens that exceed capacity are either dropped or sent to a secondary expert. The Switch Transformer uses this approach.
Sinkhorn routing: Use the Sinkhorn algorithm to find an optimal assignment that balances load while respecting token preferences.
Key Technical Details
- Expert count: Typical values are 8 (Mixtral), 16, 64, or even 128 (Switch Transformer experimented with up to 2048). More experts means more total parameters but potentially harder load balancing.
- Top-k: Usually (Switch Transformer) or (Mixtral, GShard). Top-1 is more efficient; top-2 is more stable and higher quality.
- Which layers are MoE: Not all layers need to be MoE. Some architectures alternate dense and MoE layers (e.g., every other layer is MoE). Others make every layer MoE.
- Shared components: The attention layers are typically shared (not expertized) across all tokens. Only the FFN is replaced with the MoE layer. This is because attention computes interactions between tokens and benefits from being consistent.
- Expert specialization: Research shows that experts do specialize to some degree -- some may focus on certain languages, topics, or syntactic patterns -- but specialization is less clean-cut than the "each expert is a domain specialist" metaphor suggests.
- Communication overhead: In distributed training, MoE requires all-to-all communication to send tokens to their assigned experts across different GPUs. This is a significant engineering challenge at scale.
Fine-Grained Experts and Shared Experts
A major architectural trend pioneered by DeepSeek is the shift from a few large experts to many small experts combined with shared experts that process every token:
Traditional MoE: 8 large experts, top-2 routing → 2 active
Fine-grained MoE: 256 small experts + 1 shared expert, top-8 routing → 9 activeShared experts handle common, general-purpose computations that benefit every token (basic syntax, common patterns), while routed experts specialize in narrower skills. This separation improves both quality and routing stability.
Auxiliary-Loss-Free Load Balancing
The traditional load-balancing auxiliary loss creates an optimization conflict: the main training objective wants to send tokens to the best expert, while the auxiliary loss wants to distribute them evenly. DeepSeek-V3 resolved this with a bias-based approach:
- Each expert maintains a bias term added to its router score.
- After each training step, if an expert received more tokens than average, its bias decreases; if fewer, its bias increases.
- This purely dynamic adjustment achieves balanced routing without any auxiliary loss term competing with the main objective.
The result: better model quality and more stable routing compared to auxiliary-loss approaches, confirmed across multiple model scales.
Notable MoE Models
- Switch Transformer (Fedus et al., 2021): Demonstrated top-1 routing, scaling to over 1 trillion parameters. Showed that expert count can be scaled aggressively.
- Mixtral 8x7B (Mistral AI, 2023): The model that brought MoE to mainstream attention. 8 experts, top-2 routing, outperforming LLaMA 2 70B at lower inference cost.
- Mixtral 8x22B (Mistral AI, 2024): Scaled up to 22B per expert (176B total), maintaining the efficiency advantage with top-2 routing among 8 experts.
- DeepSeek-V2 (DeepSeek, 2024): Introduced fine-grained experts (160 routed + 2 shared experts) and Multi-head Latent Attention (MLA), reducing KV cache by 93.3%.
- DeepSeek-V3 (DeepSeek, 2024): 671B total / 37B active parameters. 256 routed experts with top-8 routing, auxiliary-loss-free balancing, FP8 training. Trained on 14.8T tokens for only $5.6M in compute -- a fraction of comparable models. Matched or exceeded GPT-4o and Claude 3.5 Sonnet on many benchmarks.
- Qwen2-MoE (Alibaba, 2024): 57B total / 14B active with 64 experts and top-8 routing, demonstrating the fine-grained expert trend in the open-source ecosystem.
- Grok (xAI): Large-scale MoE model used in production.
Common Misconceptions
- "MoE models are 8x faster than dense models of the same total parameter count." MoE is faster than a dense model with the same total parameters, but not 8x faster. Active parameters are more than of total because attention layers are shared and fully dense. The speedup is typically 2-4x, not 8x.
- "Each expert becomes a specialist in a clear domain." Expert specialization exists but is fuzzy. An expert might process more tokens from certain languages or topics, but it also handles plenty of other tokens. The router's decisions are based on representation geometry, not clean semantic categories.
- "MoE is always better than dense." MoE models require more total memory, are harder to train (load balancing, communication), and can have higher inference latency per token (due to memory access patterns). Dense models are simpler, easier to deploy, and may be preferable when memory is constrained.
- "Token dropping is fine." When expert capacity is exceeded and tokens are dropped, those tokens receive degraded representations. This is a real quality concern, and modern architectures work hard to minimize or eliminate token dropping.
- "The router has learned the optimal routing strategy." Routing is still an active research area. Current routers are simple linear classifiers, and there is evidence that more sophisticated routing could improve quality significantly. Hash-based routing (no learned router) has also shown competitive results.
Connections to Other Concepts
feed-forward-networks.md: Each expert is a standard FFN; MoE replaces the single FFN with multiple experts (seefeed-forward-networks.md).activation-functions.md: Each expert uses the same activation function (typically SwiGLU) as a dense FFN would (seeactivation-functions.md).residual-connections.md: The MoE layer's output is added to the residual stream, just like a dense FFN's output (seeresidual-connections.md).transformer-architecture.md: MoE is a modification of the standard Transformer block, replacing one component (seetransformer-architecture.md).next-token-prediction.md: MoE models are trained with the same next-token prediction objective as dense models (seenext-token-prediction.md).logits-and-softmax.md: The router uses softmax to produce expert weights, similar in form to the output layer (seelogits-and-softmax.md).
Further Reading
- "Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer" -- Shazeer et al., 2017 (the foundational MoE paper for modern deep learning)
- "Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity" -- Fedus et al., 2021 (simplified routing, massive scale)
- "Mixtral of Experts" -- Jiang et al., Mistral AI, 2023 (the model that popularized MoE for open-weight LLMs)
- "DeepSeek-V3 Technical Report" -- DeepSeek-AI, 2024 (introduced auxiliary-loss-free balancing, fine-grained experts at scale, and FP8 training for MoE)
- "DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model" -- DeepSeek-AI, 2024 (pioneered fine-grained experts and Multi-head Latent Attention for MoE efficiency)