One-Line Summary: The feed-forward network in each Transformer layer is a two-layer fully connected network applied independently to each token position, acting as the model's primary knowledge store and accounting for roughly two-thirds of total parameters.
Prerequisites: Understanding of neural network layers (linear transformations), activation functions, the Transformer block structure, and the role of self-attention.
What Is the Feed-Forward Network?
If self-attention is the Transformer's communication system -- letting tokens share information with each other -- then the feed-forward network (FFN) is where each token goes off to "think privately." After attention has gathered relevant context, the FFN processes each token's representation independently, transforming it through a non-linear function.
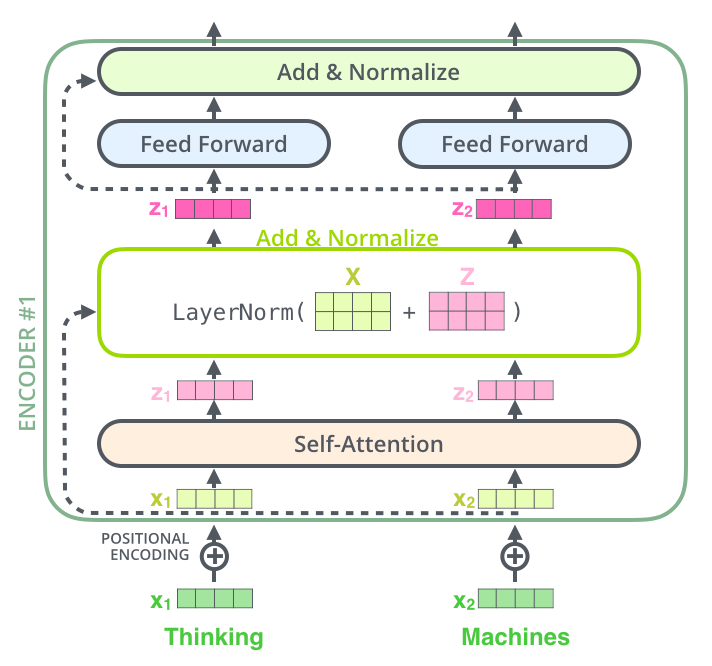 Source: Jay Alammar – The Illustrated Transformer
Source: Jay Alammar – The Illustrated Transformer
A useful analogy: imagine a team meeting (self-attention) where everyone shares their updates. After the meeting, each person goes back to their desk (FFN) to process what they heard, look things up in their personal notes, and update their understanding. The "personal notes" are the learned weights of the FFN, and this is where factual knowledge is stored.
Research has consistently shown that the FFN layers function as key-value memories -- they store factual associations like "Eiffel Tower is in Paris" or "Python is a programming language" in their weight matrices. When a token's representation activates certain neurons in the FFN, it retrieves the associated knowledge.
How It Works
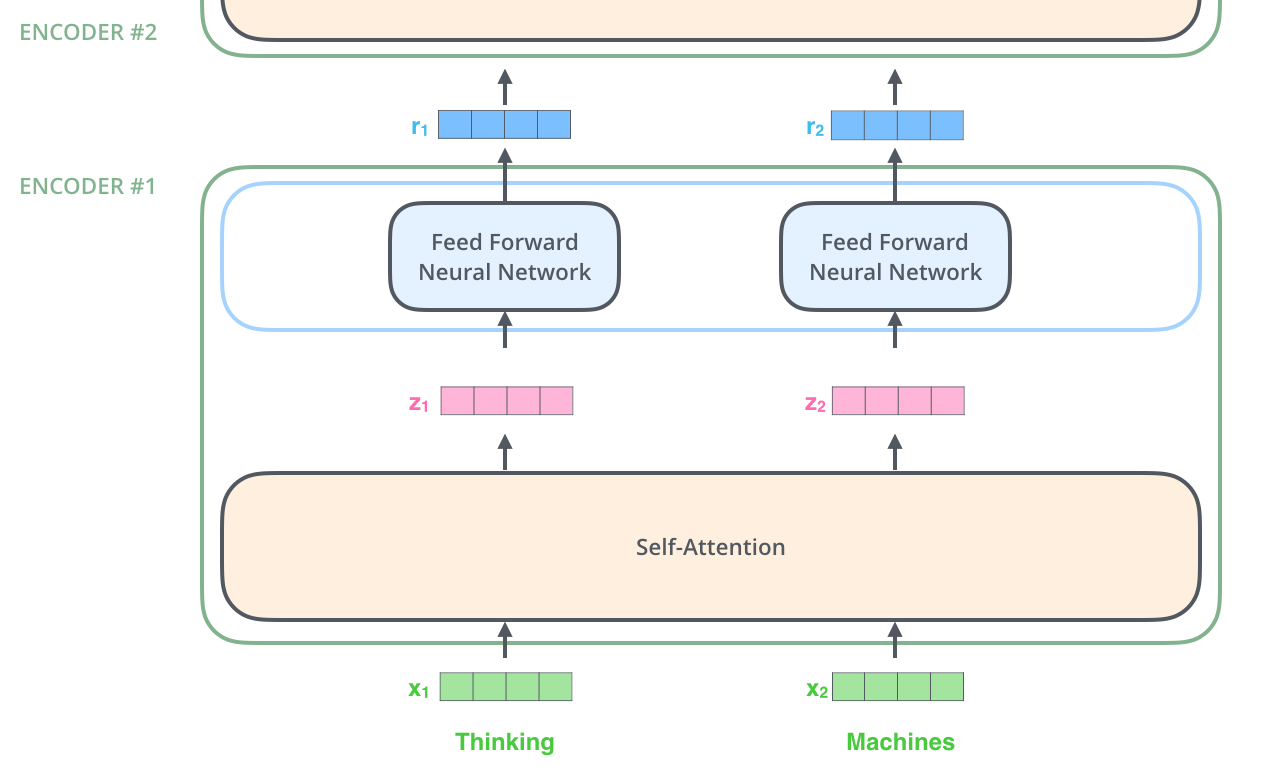 Source: Jay Alammar – The Illustrated Transformer
Source: Jay Alammar – The Illustrated Transformer
The Standard Two-Layer Structure
The classic FFN in a Transformer block consists of two linear transformations with a non-linear activation in between:
where:
- is the input for a single token position
- projects up to a larger intermediate dimension
- is a non-linear activation function (ReLU, GELU, SiLU, or SwiGLU)
- projects back down to the model dimension
- are bias terms (often omitted in modern models)
The Expand-Contract Pattern
The intermediate dimension is typically 4 times . For example:
- GPT-3: , (4x)
- LLaMA: , (2.7x, due to SwiGLU having a third weight matrix)
The "expand then contract" structure is crucial. The upward projection expands the representation into a high-dimensional space where the activation function can selectively activate different neurons. The downward projection compresses this back to the model dimension. This bottleneck-expansion-bottleneck pattern allows the model to compute complex, non-linear functions of the input.
The SwiGLU Variant (Modern Standard)
Most modern LLMs (LLaMA, Mistral, Gemma) use SwiGLU instead of a simple activation:
where is element-wise multiplication and is an additional "gate" projection. SiLU (Sigmoid Linear Unit, also called Swish) is defined as . The gating mechanism (from GLU -- Gated Linear Units) allows one projection to control the information flow of the other, leading to better training dynamics.
Because SwiGLU has three weight matrices (, , ) instead of two, the intermediate dimension is typically reduced from to (approximately 2.67x) to keep the parameter count equivalent.
Position-Wise Operation
A crucial property: the FFN is applied independently and identically to each token position. Token at position 1 and token at position 500 go through the exact same FFN with the exact same weights. There is no cross-position interaction in the FFN; all cross-position communication happens in the attention layer. The FFN is purely a per-token transformation.
Why It Matters
The Knowledge Store
The FFN layers contain the vast majority of the model's parameters and, by extension, its factual knowledge. Research by Geva et al. (2021) demonstrated that the first linear layer () acts as a pattern detector (keys) and the second linear layer () stores associated information (values), making the FFN function as a soft, differentiable key-value memory.
When you ask an LLM "What is the capital of France?" and it answers "Paris," that fact is retrieved from FFN weights, not from the attention mechanism. Attention figures out which knowledge to retrieve based on context; the FFN stores and provides that knowledge.
Parameter Budget
In a standard Transformer block, the parameter distribution is approximately:
- Attention layers (Q, K, V, O projections): parameters (approximately one-third)
- FFN layers: parameters (approximately two-thirds)
This means that when we say a model has 70 billion parameters, roughly 45-47 billion of those are in FFN layers. The FFN is where most of the model's "capacity" lives.
Non-Linearity
Without the FFN (and its activation function), the Transformer would be a stack of linear operations (attention is fundamentally a weighted sum, which is linear). The FFN introduces the non-linearity that allows the model to compute complex functions and represent intricate patterns.
Key Technical Details
- Activation functions used historically: ReLU (original Transformer), GELU (BERT, GPT-2, GPT-3), SiLU/Swish (PaLM, LLaMA 1), SwiGLU (LLaMA 2/3, Mistral, Gemma, most modern models).
- Bias terms: The original Transformer included biases. Most modern LLMs (LLaMA, PaLM, Mistral) omit biases entirely, finding they add parameters without meaningfully improving quality.
- Sparsity in activations: In ReLU-based FFNs, a large fraction (often 90%+) of intermediate neurons are zero for any given input. This observation motivated Mixture of Experts (MoE) architectures.
- Knowledge editing: Because specific facts are localized in FFN neurons, researchers have developed techniques to edit model knowledge by directly modifying FFN weights (e.g., ROME and MEMIT).
- Parallel attention and FFN: Some architectures (e.g., PaLM, GPT-J) compute attention and FFN in parallel rather than sequentially, adding both results to the residual stream. This improves training throughput with minimal quality impact.
Common Misconceptions
- "The FFN is just a boring linear layer." The FFN is where most of the model's knowledge lives and where non-linear computation happens. It is arguably as important as attention, just less architecturally novel.
- "Attention is where the model stores facts." Attention routes information; the FFN stores and retrieves it. This is well-established empirically: editing attention weights has less effect on factual recall than editing FFN weights.
- "Position-wise means it does not use context." The FFN receives the output of attention, which already contains contextual information. It processes each position independently, but each position's representation is already context-enriched.
- "The 4x expansion ratio is optimal." The 4x ratio was a somewhat arbitrary choice in the original Transformer. Modern models use different ratios (especially with SwiGLU), and the optimal ratio depends on the overall model configuration and compute budget.
Connections to Other Concepts
self-attention.md: The FFN is the second sub-layer in each Transformer block, applied after attention (seeself-attention.md,multi-head-attention.md).activation-functions.md: The choice of activation in the FFN significantly impacts training (seeactivation-functions.md).residual-connections.md: The FFN output is added to the residual stream via a skip connection (seeresidual-connections.md).layer-normalization.md: Applied before (Pre-LN) or after (Post-LN) the FFN (seelayer-normalization.md).mixture-of-experts.md: MoE replaces the single FFN with multiple expert FFNs, routing each token to a subset (seemixture-of-experts.md).
Further Reading
- "Transformer Feed-Forward Layers Are Key-Value Memories" -- Geva et al., 2021 (demonstrates that FFNs act as knowledge stores)
- "GLU Variants Improve Transformer" -- Noam Shazeer, 2020 (introduces SwiGLU and other gated variants)
- "Locating and Editing Factual Associations in GPT" -- Meng et al., 2022 (the ROME paper, showing how to edit facts in FFN weights)