One-Line Summary: LoRA freezes the pretrained model weights and injects small, trainable low-rank matrices into each layer, achieving fine-tuning quality with a fraction of the trainable parameters.
Prerequisites: Understanding of matrix multiplication, transformer architecture (particularly attention layers with Q/K/V projections), the concept of fine-tuning a pretrained model, and basic linear algebra (matrix rank and decomposition).
What Is LoRA?
Imagine you have a massive, expertly painted mural on a wall. You want to adapt it to a new theme, but repainting the entire mural is expensive and time-consuming. Instead, you place thin transparent overlays on top of the mural, each with small adjustments. The original mural stays untouched, and the overlays are lightweight enough to swap in and out.
 Source: Hugging Face – LoRA
Source: Hugging Face – LoRA
LoRA (Low-Rank Adaptation) works on exactly this principle. Instead of modifying all the billions of parameters in a pretrained language model during fine-tuning, LoRA freezes the original weight matrices and introduces small, trainable "overlay" matrices alongside them. These overlay matrices are deliberately structured to be low-rank, meaning they are compact decompositions that capture the essential adaptation needed without requiring a full-sized update matrix.
The method was introduced by Hu et al. (2021) at Microsoft Research and has since become the dominant approach to parameter-efficient fine-tuning, used everywhere from Hugging Face's PEFT library to Apple's on-device model personalization.
How It Works
flowchart LR
S1["how a d×d weight update is factored"]
S2["d×r and r×d matrices"]
S1 --> S2The Core Decomposition
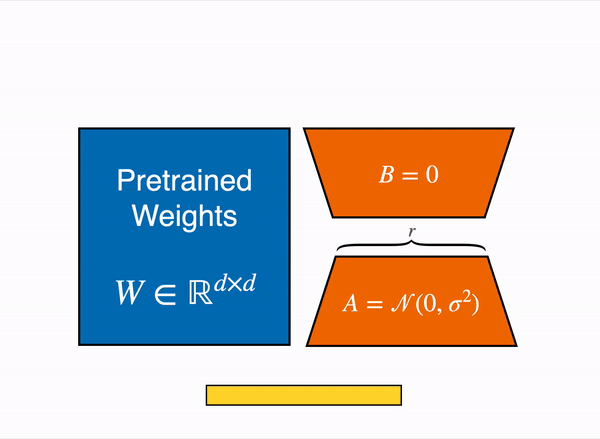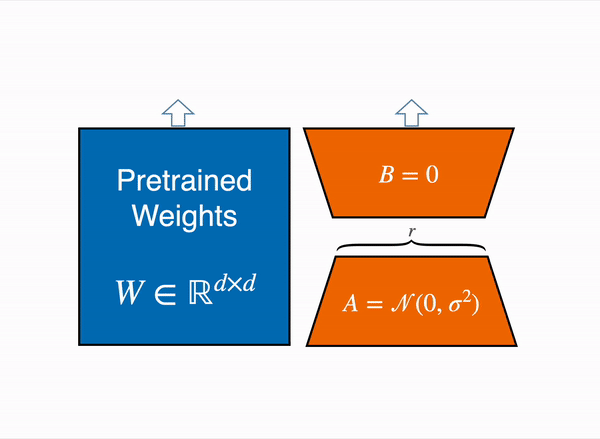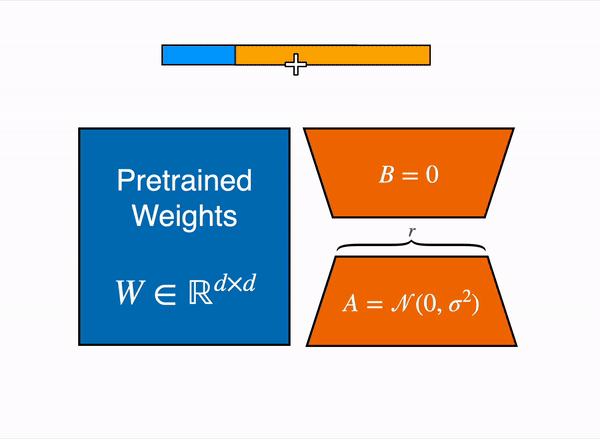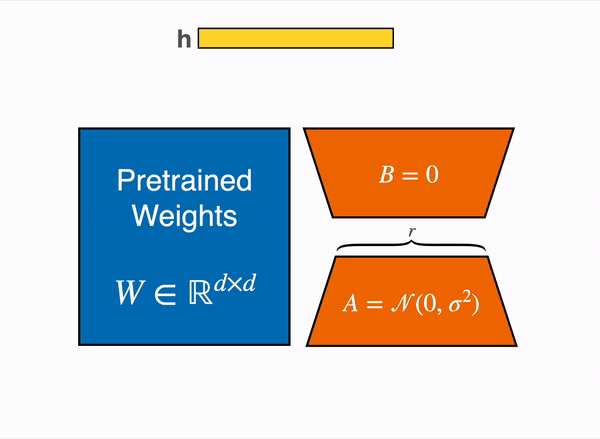
In standard fine-tuning, you update a pretrained weight matrix W_0 (of dimension d x d) to produce a new weight matrix:
W = W_0 + Delta_Wwhere Delta_W is a full d x d update matrix. For a large model, d might be 4096 or larger, meaning Delta_W contains millions of parameters per layer.
LoRA constrains Delta_W to be a low-rank matrix by decomposing it into two smaller matrices:
Delta_W = B * Awhere:
- A is of dimension r x d (the "down-projection")
- B is of dimension d x r (the "up-projection")
- r is the rank, a small number (typically 4, 8, 16, or 64)
The forward pass then becomes:
h = W_0 * x + B * A * xwhere x is the input. At initialization, A is set using a random Gaussian initialization and B is initialized to zero, so that Delta_W = B * A = 0 at the start of training. This ensures the model begins from the exact pretrained behavior and gradually learns the adaptation.
A scaling factor alpha/r is typically applied to the LoRA output, where alpha is a hyperparameter (often set equal to r or to a fixed value like 16). This controls the magnitude of the adaptation relative to the pretrained weights.
Where Adapters Are Inserted
In practice, LoRA adapters are most commonly inserted into the attention layers of the transformer. Specifically, they are applied to the query (W_q) and value (W_v) projection matrices. Some implementations also apply LoRA to the key projection (W_k) and the output projection (W_o), and even to the feed-forward network (FFN) layers (W_up, W_down, W_gate).
The original paper found that adapting W_q and W_v provided the best trade-off between quality and parameter count for many tasks, but subsequent work (and practical experience) has shown that applying LoRA to all linear layers often yields better results, especially at very low ranks.
Step-by-Step Training
- Freeze all pretrained model parameters W_0.
- Inject LoRA matrices (A, B) alongside chosen weight matrices.
- Train only the A and B matrices using standard backpropagation and your task-specific dataset.
- Merge (optionally) after training: compute W = W_0 + B * A and replace the original weight. This adds zero inference latency since the merged weight has the same dimensions as the original.
Why Low Rank Works
The key insight behind LoRA comes from research by Aghajanyan et al. (2020), which demonstrated that pretrained language models have a low intrinsic dimensionality. When you fine-tune a model for a specific task, the weight updates Delta_W, despite being full-rank matrices in theory, tend to occupy a very low-dimensional subspace. In other words, the "direction" of useful adaptation is far simpler than the full parameter space would suggest.
Empirically, ranks as low as r = 4 or r = 8 capture most of the adaptation signal for many tasks. This means a weight matrix with 4096 x 4096 = 16.7 million parameters can be adapted with only 2 x 4096 x 8 = 65,536 parameters -- a 256x reduction for that single matrix.
Why It Matters
LoRA has fundamentally changed the economics of model customization:
- Democratized fine-tuning: A 7B parameter model that would require 28 GB just for parameters (in fp32) can be fine-tuned with LoRA on a single consumer GPU, since only the small adapter matrices need gradient computation and optimizer states.
- Multi-tenant serving: A single base model can serve hundreds of different LoRA adapters. Each adapter might be just 10-50 MB, compared to the full model's tens of gigabytes. Services like Predibase and others have built entire platforms around dynamically loading LoRA adapters per request.
- Rapid experimentation: Training a LoRA adapter takes a fraction of the time and compute of full fine-tuning, enabling fast iteration on task-specific customization.
- Typical parameter reduction: For a 7B model, full fine-tuning involves 7 billion trainable parameters. A typical LoRA configuration (rank 16, applied to all attention projections) might involve only 10-20 million trainable parameters -- roughly a 500x to 1,000x reduction. At lower ranks or on larger models, reductions of 10,000x or more are achievable.
Key Technical Details
- Rank (r): The most important hyperparameter. Lower ranks (4-8) are more parameter-efficient but may underfit complex tasks. Higher ranks (32-128) approach full fine-tuning quality but with diminishing returns. Typical starting point: r = 16.
- Alpha (alpha): A scaling hyperparameter. The LoRA output is scaled by alpha/r. A common practice is to set alpha = 2 * r or keep alpha fixed at 16-32 and vary r.
- Target modules: Which layers receive LoRA adapters. More target modules = more trainable parameters = potentially better quality.
- Initialization: B is initialized to zero, A to random Gaussian. This zero-initialization is critical -- it ensures training starts from the pretrained model's exact behavior.
- Merging: After training, B * A can be added directly to W_0. The merged model has identical architecture and inference cost to the original. No adapter overhead at inference time.
- Composability: Multiple LoRA adapters can be combined (added, interpolated) to blend capabilities, though this is an active area of research with mixed results.
Common Misconceptions
- "LoRA always matches full fine-tuning quality." At very low ranks and for complex domain shifts, LoRA can underperform full fine-tuning. The gap narrows as model scale increases and as rank increases, but it is not universally zero.
- "Rank r = 1 is fine for everything." While remarkably low ranks work for simple tasks, instruction tuning or complex reasoning often benefits from r = 16 or higher.
- "LoRA adds inference latency." Only during training or when the adapter is kept separate (for hot-swapping). Once merged, the inference cost is identical to the base model.
- "LoRA only works for NLP." LoRA has been successfully applied to diffusion models (Stable Diffusion LoRA adapters are extremely popular), vision transformers, and multi-modal models.
- "You only train the LoRA matrices." In practice, it is common to also train layer norms, embedding layers, or the LM head alongside the LoRA matrices for improved quality.
Connections to Other Concepts
qlora.md: Combines LoRA with 4-bit quantization of the base model, dramatically reducing memory requirements further.- Full fine-tuning: LoRA can be understood as full fine-tuning with a structural constraint (low-rank) on the update matrices.
adapters-and-prompt-tuning.md: Alternative PEFT methods that add trainable parameters in different locations (between layers or as input prefixes) rather than as parallel low-rank decompositions.quantization.md: LoRA is complementary to quantization -- the frozen base model can be quantized while the LoRA matrices remain in higher precision.model-merging.md: LoRA adapters can be merged with the base model or with each other, connecting to the broader topic of model merging and task arithmetic.- Serving infrastructure: LoRA's small adapter size enables architectures like S-LoRA that batch requests across many different adapters efficiently.
Further Reading
- "LoRA: Low-Rank Adaptation of Large Language Models" -- Hu et al. (2021). The original paper introducing the method. arXiv:2106.09685
- "Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning" -- Aghajanyan et al. (2020). The theoretical foundation for why low-rank adaptation works. arXiv:2012.13255
- "Practical Tips for Finetuning LLMs Using LoRA" -- Sebastian Raschka (2023). An excellent practical guide covering hyperparameter selection and best practices. Magazine article and blog post