One-Line Summary: AdamW is the near-universal optimizer for LLM training, combining adaptive per-parameter learning rates with momentum and properly decoupled weight decay to navigate the complex, high-dimensional loss landscapes of billion-parameter models.
Prerequisites: Gradient descent basics, backpropagation, the concept of learning rate, basic understanding of training loops, why model parameters need to be updated to minimize loss.
What Is Adam?
Imagine you are hiking down a mountain in dense fog. You can feel the slope beneath your feet (the gradient), but you cannot see the terrain ahead. Vanilla gradient descent says: "take a step directly downhill, proportional to the steepness." But this is naive -- some directions are steep ravines where you oscillate back and forth, while other directions are gentle slopes where you barely make progress.
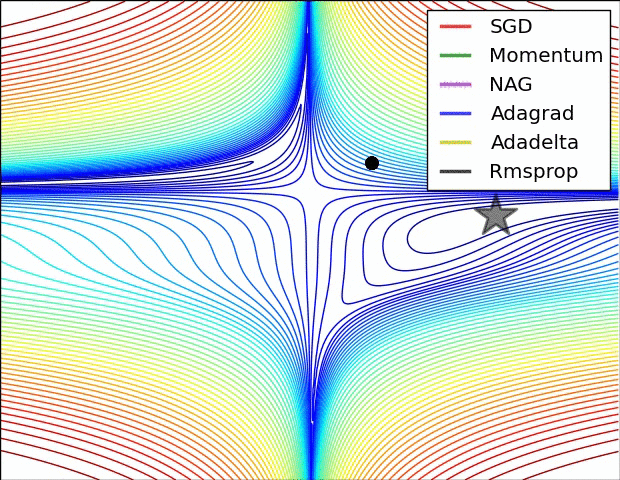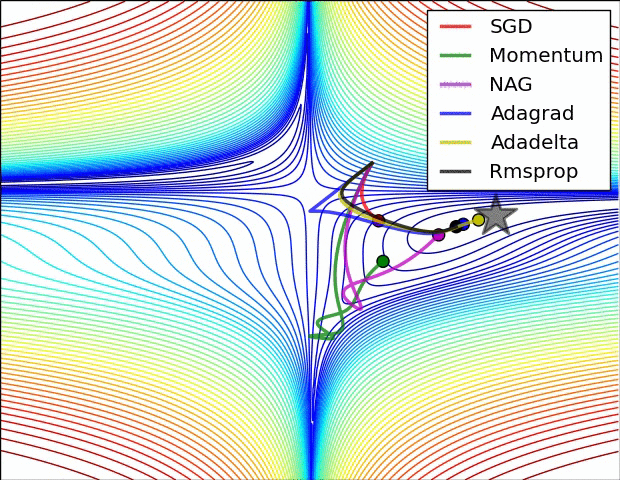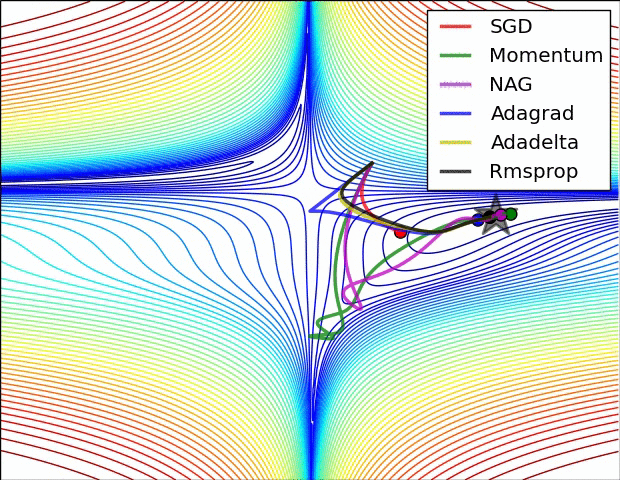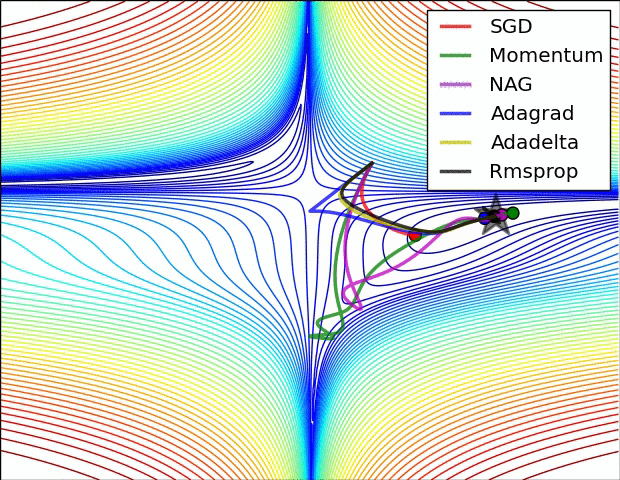 Source: Sebastian Ruder -- An Overview of Gradient Descent Optimization Algorithms
Source: Sebastian Ruder -- An Overview of Gradient Descent Optimization Algorithms
Adam is like a smarter hiker who remembers two things: (1) the average direction they have been heading recently (momentum), and (2) how variable the terrain has been in each direction (adaptive learning rate). In directions where the gradient has been consistently pointing one way, Adam takes larger, confident steps. In directions where the gradient fluctuates wildly, Adam takes smaller, cautious steps.
This per-parameter adaptivity is why Adam dramatically outperforms vanilla stochastic gradient descent (SGD) for training transformers.
How It Works
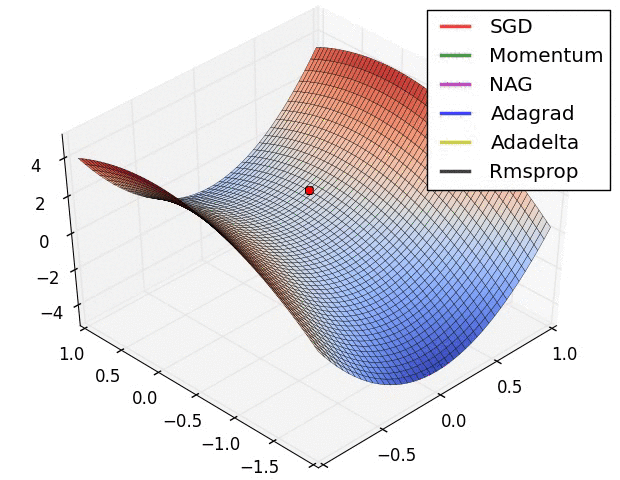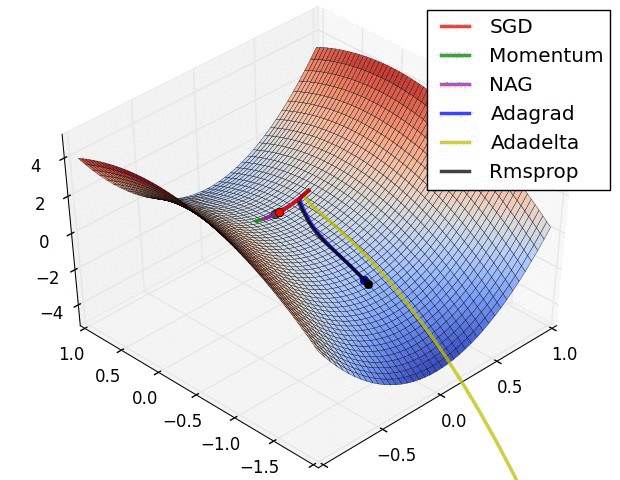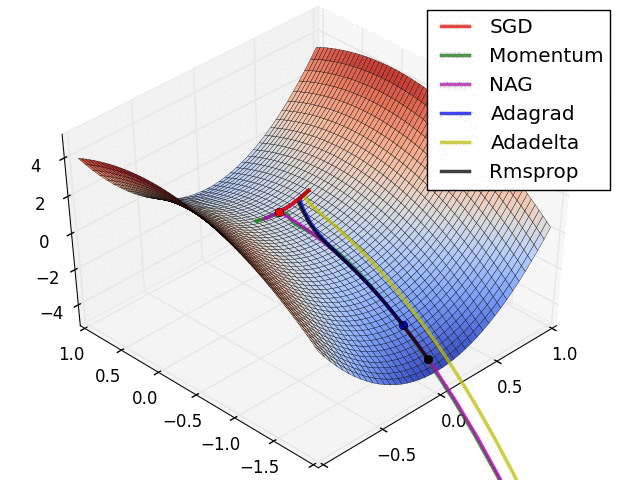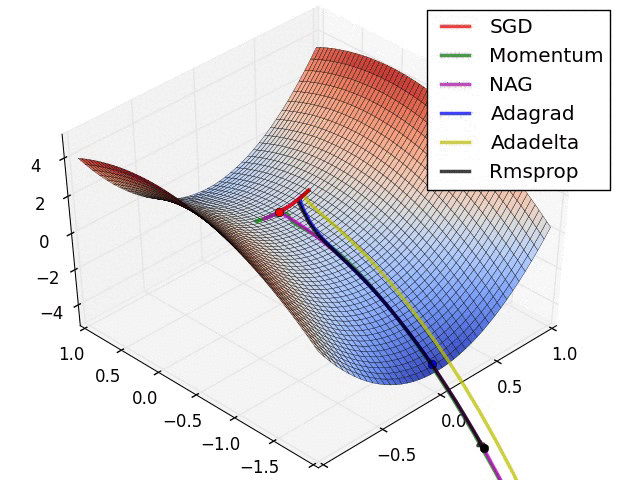 Source: Sebastian Ruder -- An Overview of Gradient Descent Optimization Algorithms
Source: Sebastian Ruder -- An Overview of Gradient Descent Optimization Algorithms
Why Vanilla SGD Is Not Enough
Stochastic Gradient Descent (SGD) uses a single learning rate for all parameters:
where is the gradient at step . This has several problems for LLM training:
- No momentum: Each step is based only on the current gradient, ignoring the history of previous gradients. This leads to noisy, oscillatory updates.
- Same learning rate for all parameters: Some parameters (e.g., in early layers) may need smaller updates, while others (e.g., in later layers) need larger ones.
- Sensitive to gradient scale: Parameters receiving large gradients get large updates, which can cause instability; parameters receiving small gradients barely move.
The Adam Algorithm
Adam (Adaptive Moment Estimation) maintains two exponential moving averages for each parameter:
First moment estimate (momentum): The running average of gradients:
Second moment estimate (adaptive learning rate): The running average of squared gradients:
Bias correction: Because and , the estimates are biased toward zero in early steps. Correct for this:
Parameter update:
The key insight is the division by : parameters that have experienced large gradient magnitudes get a smaller effective learning rate (cautious updates), while parameters with consistently small gradients get a larger effective learning rate (more aggressive updates).
The Problem with L2 Regularization in Adam
In vanilla SGD, L2 regularization (adding to the loss) is equivalent to weight decay (directly shrinking weights by a factor at each step). In Adam, this equivalence breaks down. When L2 regularization is used with Adam, the adaptive scaling of gradients also scales the regularization term, which weakens the regularization effect for parameters with large gradient variance.
AdamW: Decoupled Weight Decay
AdamW (proposed by Loshchilov and Hutter, 2019) fixes this by decoupling weight decay from the gradient-based update:
The weight decay term is applied directly to the parameters, independent of the adaptive gradient scaling. This ensures consistent regularization regardless of gradient history.
This seemingly small change has a significant impact: AdamW consistently outperforms Adam with L2 regularization for transformer training, and it has become the de facto standard optimizer for all large language models.
Typical Hyperparameters for LLM Training
| Hyperparameter | Symbol | Typical Value | Purpose |
|---|---|---|---|
| Learning rate | 1e-4 to 6e-4 | Global step size (varies with model size) | |
| Beta1 | 0.9 | Momentum decay rate | |
| Beta2 | 0.95 | Second moment decay rate | |
| Epsilon | 1e-8 | Numerical stability term | |
| Weight decay | 0.1 | Regularization strength |
Notable deviations from the original Adam defaults:
- instead of the original 0.999. The lower value gives less memory to old squared gradients, making the optimizer more responsive to recent gradient magnitudes. This has been found empirically to work better for transformers.
- Weight decay of 0.1 is larger than typical values for other architectures, providing meaningful regularization for overparameterized models.
Memory Requirements
Adam/AdamW stores three values per parameter: the parameter itself, the first moment , and the second moment . In FP32, this means:
See also the AdamW weight decay decoupling diagram in: Loshchilov & Hutter, "Decoupled Weight Decay Regularization" (arXiv:1711.05101), Figure 1, which illustrates the difference between L2 regularization in Adam vs. decoupled weight decay in AdamW.
- Parameters: 4 bytes each
- First moments: 4 bytes each
- Second moments: 4 bytes each
- Total: 12 bytes per parameter
For a 70B parameter model: GB just for the optimizer. This is a major reason why distributed training is necessary. Some implementations store moments in lower precision to reduce memory, though this must be done carefully to avoid instability.
Why It Matters
The choice of optimizer can make or break an LLM training run costing millions of dollars. AdamW's combination of momentum (for smooth convergence), adaptive learning rates (for handling the diverse gradient scales across layers), and proper weight decay (for regularization) makes it uniquely suited to transformer training.
Attempts to replace AdamW with alternatives have been a persistent research direction. Optimizers like Adafactor (which uses factored second moments to save memory), LAMB (for very large batch training), Lion (discovered by program search), and Sophia (which uses Hessian information) have been proposed. While some show promise in specific settings, none has yet displaced AdamW as the default for frontier model training. AdamW's reliability, well-understood behavior, and extensive empirical validation make it the safe choice when spending millions on a single training run.
Key Technical Details
- AdamW is applied after gradient clipping: The typical order is compute gradients, clip gradients, then apply optimizer step.
- Learning rate schedule is separate: The learning rate in the AdamW formula is not constant -- it follows a schedule (typically warmup + cosine decay). The schedule modulates the global step size while Adam handles the per-parameter adaptivity.
- Bias correction matters early in training: Without bias correction, the first few hundred steps would use severely underestimated moments, potentially causing instability.
- prevents division by zero: While seemingly minor, the epsilon value can matter for parameters with very small gradients. Some implementations use for additional stability.
- Gradient accumulation is compatible: When using gradient accumulation (multiple forward-backward passes before one optimizer step), the accumulated gradients are passed to Adam as if they came from a single large batch.
- No weight decay on certain parameters: Bias terms, layer normalization parameters, and embedding layers are typically excluded from weight decay, as regularizing them can hurt performance.
Common Misconceptions
- "Adam is just SGD with momentum." SGD with momentum uses a single momentum term. Adam adds a second moment (squared gradient tracking) for adaptive learning rates, which is a fundamentally different mechanism.
- "Adam always converges faster than SGD." For some problems (notably image classification with CNNs), well-tuned SGD with momentum can match or outperform Adam in final accuracy. However, for transformers, Adam/AdamW is consistently superior.
- "The default Adam hyperparameters work well for LLMs." The original defaults () are actually suboptimal for transformers. The LLM community has converged on through extensive experimentation.
- "AdamW and Adam with L2 regularization are the same thing." They are not. The decoupling in AdamW produces meaningfully different training dynamics and better generalization.
Connections to Other Concepts
backpropagation.md: Computes the gradients that Adam uses to update parameters.learning-rate-scheduling.md: Modulates the base learning rate that Adam applies at each step.gradient-clipping.md: Applied to gradients before they are passed to the optimizer.mixed-precision-training.md: Affects how optimizer states are stored (master weights in FP32).05-distributed-training-infrastructure.md: Optimizer states must be partitioned across GPUs (e.g., via ZeRO).scaling-laws.md: The optimal learning rate and other hyperparameters shift predictably with model size.
Further Reading
- Kingma, D.P. & Ba, J. (2015). "Adam: A Method for Stochastic Optimization" -- The original Adam paper, one of the most cited papers in deep learning.
- Loshchilov, I. & Hutter, F. (2019). "Decoupled Weight Decay Regularization" -- Introduced AdamW and demonstrated the critical importance of decoupling weight decay from the adaptive gradient mechanism.
- Zhang, J., et al. (2020). "Why Are Adaptive Methods Good for Attention Models?" -- Provides theoretical and empirical analysis of why Adam-style optimizers are particularly well-suited for transformer architectures.