One-Line Summary: Pre-training is the foundational, most expensive phase of LLM development where a model learns language, facts, reasoning, and code by predicting the next token across trillions of words of text.
Prerequisites: Tokenization and vocabulary, transformer architecture basics, self-supervised learning vs. supervised learning, basic understanding of neural network training loops.
What Is Pre-Training?
Imagine teaching a child to understand the world by having them read every book, website, and conversation transcript ever written -- without any teacher explicitly telling them what is right or wrong. Instead, the child simply practices predicting the next word in every sentence they encounter. Over time, through sheer volume, they internalize grammar, facts, reasoning patterns, coding conventions, and even cultural nuances.
 Source: Jay Alammar -- The Illustrated GPT-2
Source: Jay Alammar -- The Illustrated GPT-2
That is pre-training.
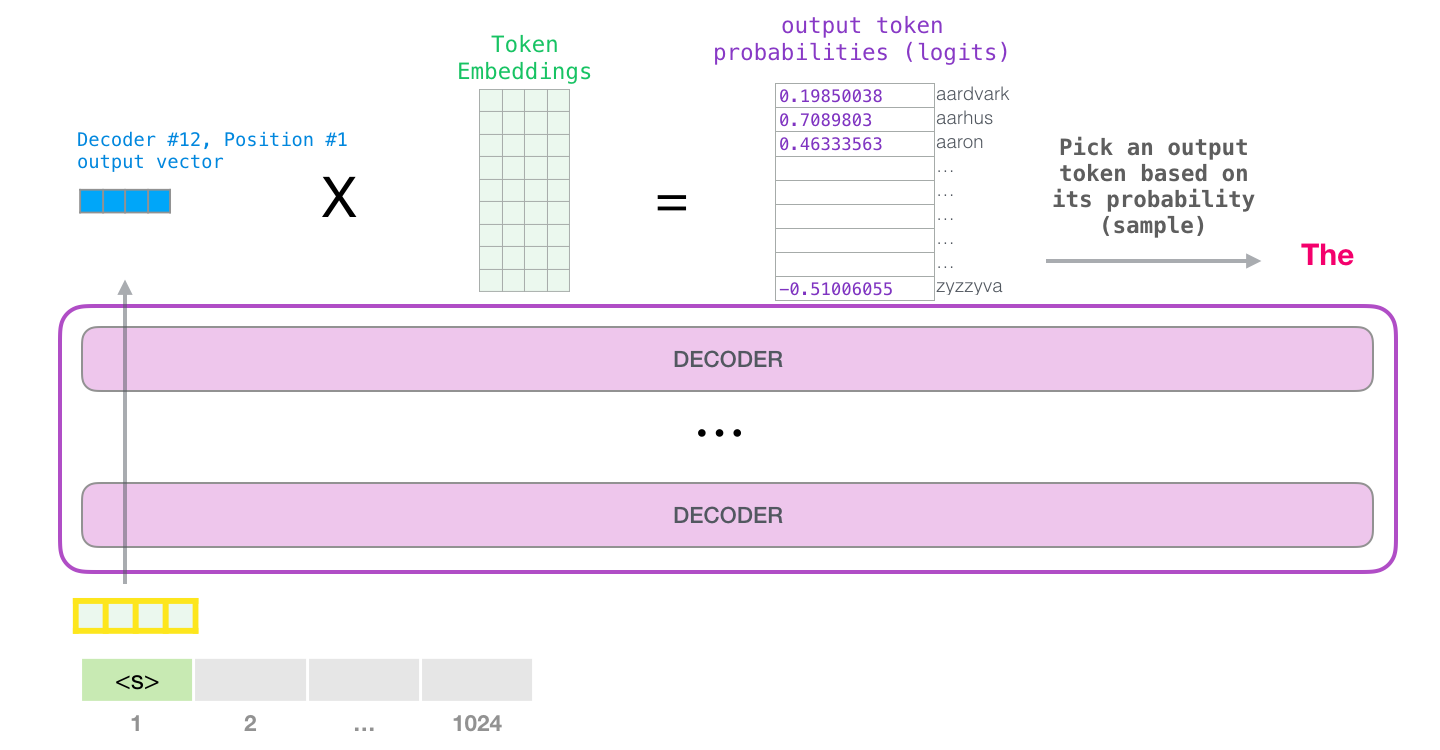
Pre-training is the first and most resource-intensive phase of building a large language model. The model starts with randomly initialized parameters -- it knows nothing. It is then exposed to a massive corpus of text (typically trillions of tokens), and its sole task is next-token prediction: given a sequence of tokens, predict what comes next. No human labels the data. No one tells the model "this sentence is about physics" or "this code is correct." The supervision signal comes entirely from the data itself, making this a self-supervised learning process.
The beauty of this approach is that next-token prediction, despite its apparent simplicity, forces the model to learn an extraordinary range of capabilities. To predict the next word in a medical textbook, the model must learn medicine. To predict the next token in Python code, it must learn programming. To predict the next word in a logical argument, it must learn reasoning.
How It Works
 Source: Hugging Face Blog -- RLHF: Reinforcement Learning from Human Feedback
Source: Hugging Face Blog -- RLHF: Reinforcement Learning from Human Feedback
The Training Loop
Pre-training follows a conceptually simple but computationally enormous loop:
- Sample a batch of text sequences from the training corpus (e.g., 2048 or 4096 tokens each).
- Forward pass: Feed each sequence through the transformer. At every position , the model produces a probability distribution over the entire vocabulary.
- Compute the loss: Use cross-entropy loss to measure how far the model's predictions deviate from the actual next tokens.
- Backward pass: Compute gradients of the loss with respect to all model parameters via backpropagation.
- Update parameters: Apply an optimizer (typically AdamW) to adjust the model's billions of parameters.
- Repeat -- for hundreds of thousands or millions of steps.
The Objective Function
The pre-training objective is to minimize the negative log-likelihood of the training data:
where is the sequence length, is the actual token at position , and represents the model's parameters. This is equivalent to minimizing cross-entropy loss averaged over all positions.
What the Model Learns
Through next-token prediction at scale, the model implicitly learns:
- Syntax and grammar: How languages are structured at every level.
- World knowledge: Facts, dates, relationships, geography, science -- anything present in the training data.
- Reasoning patterns: Logical inference, mathematical reasoning, causal thinking -- because predicting the conclusion of an argument requires understanding the argument.
- Code: Programming syntax, algorithms, debugging patterns, API usage.
- Multilingual capabilities: Translation patterns, language-specific structures.
- Style and tone: Formal writing, casual conversation, technical prose, poetry.
The Data Mix
The training corpus is never just one kind of text. Teams carefully curate a data mix that typically includes:
flowchart LR
S1["massive text corpus being processed"]
S2["the transformer"]
S3["predict next tokens"]
S1 --> S2
S2 --> S3| Source | Typical Proportion | Purpose |
|---|---|---|
| Web crawl (Common Crawl, filtered) | 50-70% | Broad language coverage |
| Books | 5-15% | Long-form reasoning, narrative |
| Code (GitHub) | 5-20% | Programming, logical structure |
| Academic papers | 5-10% | Scientific reasoning, technical language |
| Wikipedia | 3-5% | Factual density |
| Curated/synthetic data | Variable | Targeted capability improvement |
These ratios are among the most consequential decisions in pre-training. Getting the mix wrong can produce a model that is excellent at code but poor at conversation, or rich in knowledge but unable to reason.
Infrastructure and Cost
Pre-training a frontier LLM is one of the most expensive computational endeavors in history:
See also the training loss curves and scaling behavior at: Brown et al., "Language Models are Few-Shot Learners" (GPT-3, arXiv:2005.14165), Figure 1, which shows smooth cross-entropy loss reduction over training steps for models of different sizes, demonstrating predictable scaling behavior during pre-training.
- Hardware: Thousands of high-end GPUs (e.g., 8,000-16,000 NVIDIA H100s) or equivalent TPU pods, connected with high-bandwidth interconnects (InfiniBand, NVLink).
- Duration: Weeks to months of continuous training. GPT-4-class models may train for 3-6 months.
- Cost: Estimates for frontier models range from 100 million in compute alone. This does not include data curation, engineering salaries, or failed runs.
- Energy: A single training run can consume gigawatt-hours of electricity, raising significant environmental and infrastructure concerns.
- Failure risk: Hardware failures, numerical instabilities (loss spikes), and bugs can force costly restarts. Teams maintain frequent checkpoints to recover from failures.
A typical training run processes 1-15 trillion tokens. At a throughput of, say, 3,000 tokens per GPU per second across 8,000 GPUs, processing 10 trillion tokens takes roughly 50 days of continuous operation -- assuming zero downtime.
Why It Matters
Pre-training is where the vast majority of an LLM's knowledge and capability is formed. Every subsequent phase -- fine-tuning, RLHF, prompt engineering -- is built on the foundation laid during pre-training. A model that was poorly pre-trained cannot be salvaged by better fine-tuning. Conversely, a well-pre-trained model is remarkably adaptable, requiring relatively little additional training to specialize.
The enormous cost of pre-training also creates a significant barrier to entry. Only a handful of organizations worldwide can afford to pre-train frontier models from scratch, which has profound implications for competition, access, and the concentration of AI capabilities.
Key Technical Details
- Self-supervised: No human labels needed; the text itself provides the supervision signal.
- Causal language modeling: The model only sees tokens to the left (autoregressive). This is enforced by causal masking in the attention mechanism.
- Token count matters enormously: Scaling laws show that the number of training tokens is as important as model size for final performance.
- Learning rate warmup: Training typically starts with a low learning rate that ramps up over the first few thousand steps, then decays via a cosine schedule.
- Checkpointing: Models are saved periodically (e.g., every 1,000 steps) to allow recovery from hardware failures or training instabilities.
- Loss spikes: Sudden increases in training loss are common and can require intervention -- rolling back to a previous checkpoint and adjusting hyperparameters.
- Evaluation during training: Teams continuously monitor validation loss on held-out data and run benchmark evaluations to track capability acquisition.
Common Misconceptions
- "Pre-training teaches the model to follow instructions." It does not. Pre-training teaches the model to predict text. Instruction-following requires additional fine-tuning (SFT) and alignment (RLHF/DPO).
- "More data is always better." Not if the data is low quality. Duplicate, noisy, or toxic data can degrade performance. Data curation is critical.
- "The model memorizes the training data." While some memorization occurs (especially for repeated sequences), the model primarily learns statistical patterns and generalizable representations.
- "Pre-training is just about scale." Architecture decisions, data quality, hyperparameter tuning, and training stability all matter enormously. Simply scaling up a poorly configured run wastes resources.
Connections to Other Concepts
cross-entropy-loss.md: The objective function that drives pre-training.tokenization.md: Determines the vocabulary and granularity of prediction.scaling-laws.md: Govern how much compute, data, and parameters are needed.training-data-curation.md: The quality and composition of the pre-training corpus directly determines what the model can learn.mixed-precision-training.md: Essential for making pre-training computationally feasible.supervised-fine-tuning.md: The stages that follow pre-training to specialize and align the model.05-distributed-training-infrastructure.md: Parallelism strategies (data, tensor, pipeline) that make training across thousands of GPUs possible.
Further Reading
- Radford, A., et al. (2018). "Improving Language Understanding by Generative Pre-Training" -- The GPT-1 paper that established the pre-training + fine-tuning paradigm.
- Brown, T., et al. (2020). "Language Models are Few-Shot Learners" (GPT-3) -- Demonstrated the remarkable capabilities that emerge from scaling pre-training.
- Hoffmann, J., et al. (2022). "Training Compute-Optimal Large Language Models" (Chinchilla) -- Showed that many models were undertrained and that data scaling matters as much as parameter scaling.