One-Line Summary: Context window extension encompasses the techniques that have stretched LLM context lengths from 512 tokens to over 1 million, overcoming the quadratic cost of attention through clever positional encoding manipulation, architectural modifications, and distributed computation strategies.
Prerequisites: Understanding of Transformer attention (especially its O(n^2) complexity), positional encodings (sinusoidal, learned, and rotary), the training-inference distribution gap, and basic signal processing concepts (frequencies, interpolation).
What Is Context Window Extension?
Imagine you trained a reader to process single pages. Now you hand them an entire novel and ask them to understand it all at once. The reader has never seen that much text -- their "sense of position" breaks down. They do not know where they are in the document, and the sheer volume of cross-referencing overwhelms their capacity. Context window extension is the collection of techniques that teach this reader to handle the novel without starting their education from scratch.
flowchart LR
S1["original Transformer"]
S2["Gemini"]
S1 --> S2Every Transformer-based LLM is trained with a fixed maximum sequence length. GPT-2 was trained on 1,024 tokens. Early LLaMA used 2,048. But applications demand much more: analyzing legal contracts, processing codebases, or maintaining long conversations. Extending context is hard for two reasons: (1) attention's compute and memory cost scales quadratically with sequence length, and (2) positional encodings learned at one length do not generalize to longer sequences without modification.
How It Works
 Source: Lilian Weng – The Transformer Family
Source: Lilian Weng – The Transformer Family
The Core Problem: Quadratic Attention
Self-attention computes pairwise interactions between all tokens:
Attention(Q, K, V) = softmax(Q * K^T / sqrt(d_k)) * VFor sequence length n, the Q * K^T matrix is n x n, requiring O(n^2) compute and memory. Doubling context length quadruples cost. A model trained at 4K context requires 64x more attention compute to run at 32K.
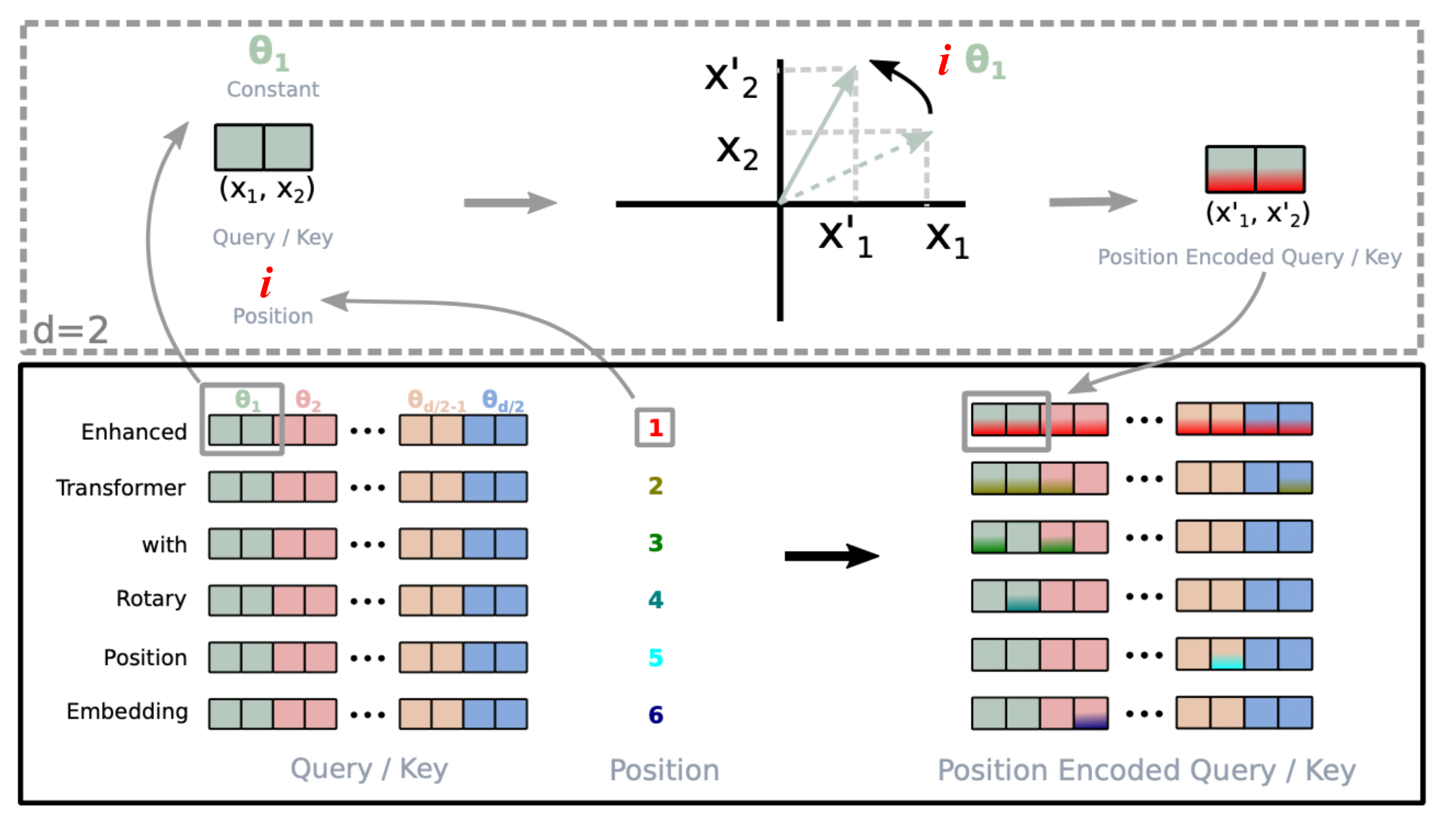
Position Interpolation (PI)
The first major breakthrough for RoPE-based models (Chen et al., 2023). Instead of extrapolating positional encodings to unseen positions (which fails badly), PI linearly compresses all positions to fit within the original trained range:
position_new = position * (L_train / L_target)Where L_train is the original context length and L_target is the desired length. A model trained at 2K context can be extended to 8K by mapping position 8000 to position 2000 in the original encoding space. This requires only a small amount of fine-tuning (a few hundred steps) to adapt.
NTK-Aware RoPE Scaling
Position interpolation compresses all frequencies equally, which degrades high-frequency components that encode local relationships. NTK-aware scaling (inspired by Neural Tangent Kernel theory) applies non-uniform scaling: it stretches low-frequency components (which encode long-range position) more than high-frequency ones (which encode local position):
theta_i_new = theta_i * scale^(2i / (d - 2))Where scale = L_target / L_train. This preserves local positional precision while extending long-range capacity. The "NTK-by-parts" refinement further avoids modifying the very highest frequencies entirely.
YaRN (Yet another RoPE extensioN)
YaRN (Peng et al., 2023) combines NTK-aware scaling with an attention temperature correction. The key insight is that interpolation changes the distribution of attention logits, and a temperature factor compensates:
temperature = 0.1 * ln(scale) + 1.0
Attention = softmax(Q * K^T / (sqrt(d_k) * temperature)) * VYaRN partitions RoPE dimensions into three groups: low-frequency dimensions get interpolated, high-frequency dimensions are left unchanged, and mid-frequency dimensions get a smooth blend. This achieves strong performance with minimal fine-tuning.
Sliding Window Attention
Instead of attending to all previous tokens, each layer attends only to a local window (e.g., 4,096 tokens). By stacking multiple layers, the effective receptive field grows -- layer L can indirectly access information L * window_size tokens away. Mistral popularized this approach, achieving strong performance with dramatically reduced memory.
Ring Attention
For sequences too long for a single GPU, Ring Attention (Liu et al., 2023) distributes the context across multiple devices arranged in a ring topology. Each GPU holds a chunk of the KV cache and computes local attention, then passes its KV block to the next GPU in the ring. This overlaps communication with computation, enabling near-linear scaling of context length with GPU count. Google used this approach for Gemini's million-token context.
Continued Pre-Training
All positional encoding tricks require some fine-tuning to work well. For production models, the standard approach is continued pre-training: train the model for additional steps on data packed to the target context length. LLaMA-2 was trained at 4K then extended to 32K through continued pre-training. The cost is typically 1-5% of original pre-training compute.
Why It Matters
Context length determines what problems an LLM can tackle in a single pass. Short context forces chunking strategies, retrieval systems, and lossy summarization. Long context enables:
- Entire codebase analysis without RAG complexity
- Book-length document understanding for legal, medical, and research applications
- Extended conversations without memory tricks
- Many-shot prompting with dozens or hundreds of examples
The progression from 512 tokens (BERT) to 10M+ tokens (Gemini 1.5) represents a qualitative shift in capability.
Key Technical Details
- Attention sinks: The first few tokens in a sequence receive disproportionately high attention regardless of content. StreamingLLM (Xiao et al., 2023) showed that keeping a small window of initial "sink" tokens plus recent tokens enables infinite streaming inference.
- Lost in the middle: Liu et al. (2023) demonstrated that LLMs struggle to retrieve information placed in the middle of long contexts. Performance is highest for information at the beginning or end, forming a U-shaped curve. This is an active area of improvement.
- Memory scaling: Even with FlashAttention, KV cache memory grows linearly with context length. A 70B model at 128K context can require 40+ GB just for KV cache.
- Effective context vs. maximum context: A model may accept 1M tokens but not effectively utilize information from all positions. Needle-in-a-haystack tests measure this gap.
- Perplexity vs. downstream performance: A model may have good perplexity at extended lengths but still fail at retrieval tasks -- these metrics measure different capabilities.
Common Misconceptions
- "Longer context means the model uses all of it equally": Models exhibit strong recency bias and positional preferences. The "lost in the middle" phenomenon means information placement significantly affects retrieval accuracy.
- "Context extension is free after the initial trick": Every extension method requires some fine-tuning, and longer contexts always cost more compute and memory at inference. There is no free lunch.
- "RAG is obsolete with long context": Long context and RAG are complementary. Long context eliminates chunking artifacts but does not replace the precision of targeted retrieval for truly massive knowledge bases. Cost also matters: processing 1M tokens per query is expensive.
- "Position interpolation works for any multiplier": Extreme compression ratios (e.g., 64x) significantly degrade quality even with fine-tuning. Practical extensions are typically 4-16x the training length.
- "Sliding window attention loses information": While each layer has a limited window, the stacking of layers creates an exponentially growing receptive field. Information propagates through layers, though very long-range dependencies may be attenuated.
Connections to Other Concepts
rotary-position-embedding.md: Almost all modern context extension techniques build on RoPE, making understanding of its frequency-based encoding essential.flash-attention.md: Hardware-efficient attention is a prerequisite for practical long-context models. Without FlashAttention, even 8K context is memory-prohibitive for large models.state-space-models.md: SSMs bypass the context extension problem entirely with their O(n) complexity and fixed-size state, offering an architectural alternative.rag.md: Long context and RAG represent complementary solutions to the knowledge access problem -- one extends the input window, the other fetches relevant information.kv-cache.md: Context extension directly increases KV cache requirements, making techniques like GQA, MQA, and KV cache quantization critical companions.05-distributed-training-infrastructure.md: Ring Attention and context parallelism connect context extension to distributed systems design.
Further Reading
- "Extending Context Window of Large Language Models via Positional Interpolation" (Chen et al., 2023): The foundational position interpolation paper that showed simple scaling works surprisingly well.
- "YaRN: Efficient Context Window Extension of Large Language Models" (Peng et al., 2023): The most complete treatment of frequency-aware RoPE extension with attention temperature correction.
- "Ring Attention with Blockwise Transformers for Near-Infinite Context" (Liu et al., 2023): The distributed approach enabling million-token contexts by partitioning across GPUs.