One-Line Summary: Multi-head attention runs several self-attention operations in parallel, each with its own learned projection, enabling the model to simultaneously attend to different types of relationships -- syntactic, semantic, positional -- and then combines the results.
Prerequisites: Understanding of self-attention (queries, keys, values, scaled dot-product attention), matrix multiplication, and the concept of learned weight parameters.
What Is Multi-Head Attention?
Imagine you are analyzing a sentence and you need to answer multiple questions at once: "What is the grammatical subject?", "What does this pronoun refer to?", "Which adjective modifies which noun?", and "What is the overall topic?" A single attention operation computes one set of weights -- one way of looking at the data. It would struggle to answer all these different questions simultaneously.
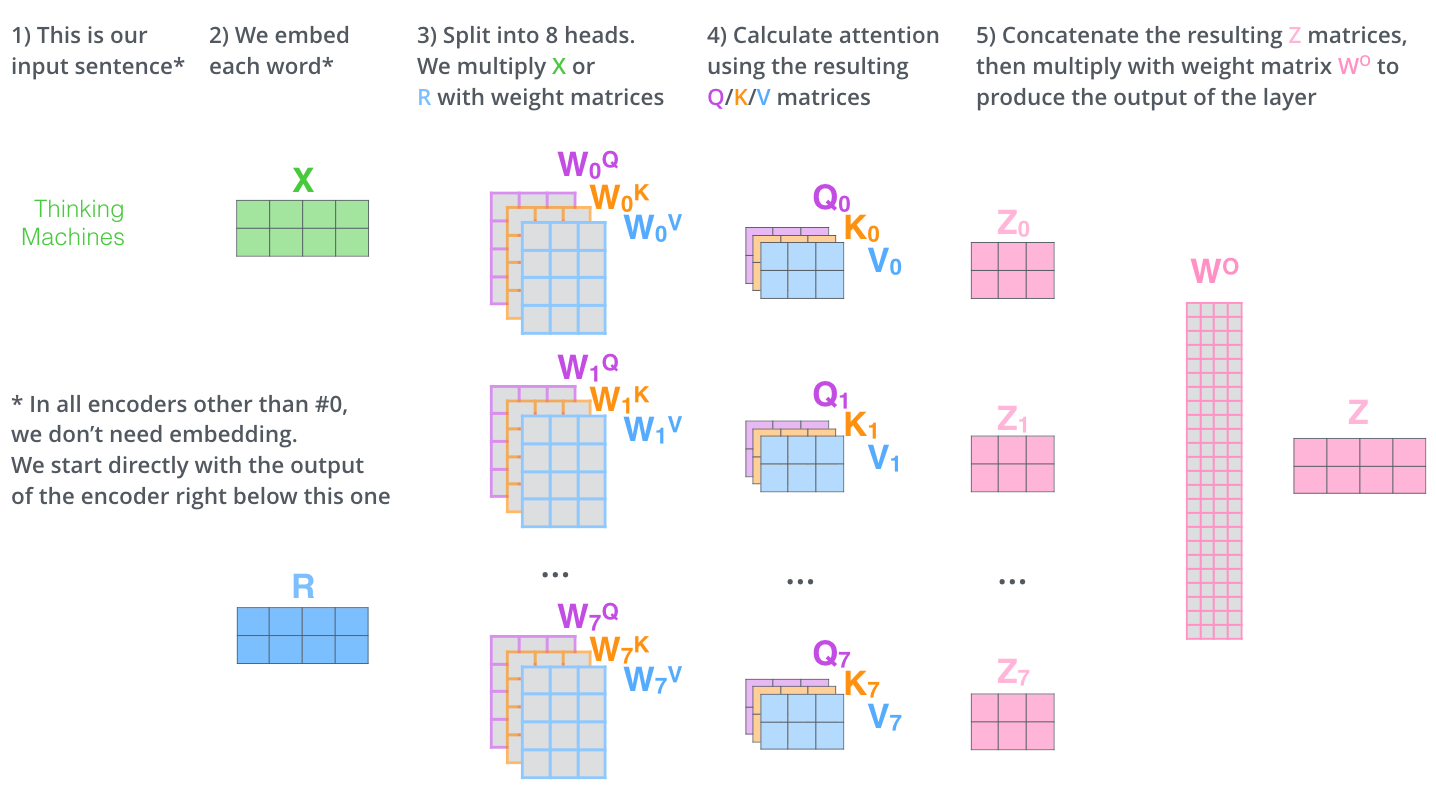 Source: The Illustrated Transformer -- Jay Alammar
Source: The Illustrated Transformer -- Jay Alammar
Multi-head attention solves this by running multiple attention operations in parallel, each with its own learned parameters. Each "head" can specialize in a different type of linguistic relationship. One head might learn to track subject-verb agreement, another might learn coreference (pronoun resolution), and another might attend to nearby tokens for local syntax. The results from all heads are concatenated and projected to form the final output.
Think of it like a panel of analysts: each analyst examines the same data through a different lens, and then their reports are merged into a single comprehensive summary.
How It Works
flowchart LR
subgraph L1["Comparison of Multi-Head Attention (MHA)"]
LI3["and Multi-Query Attention (MQA)"]
end
subgraph R2["Grouped-Query Attention (GQA)"]
RI4["Feature 1"]
endStep 1: Project Into Multiple Subspaces
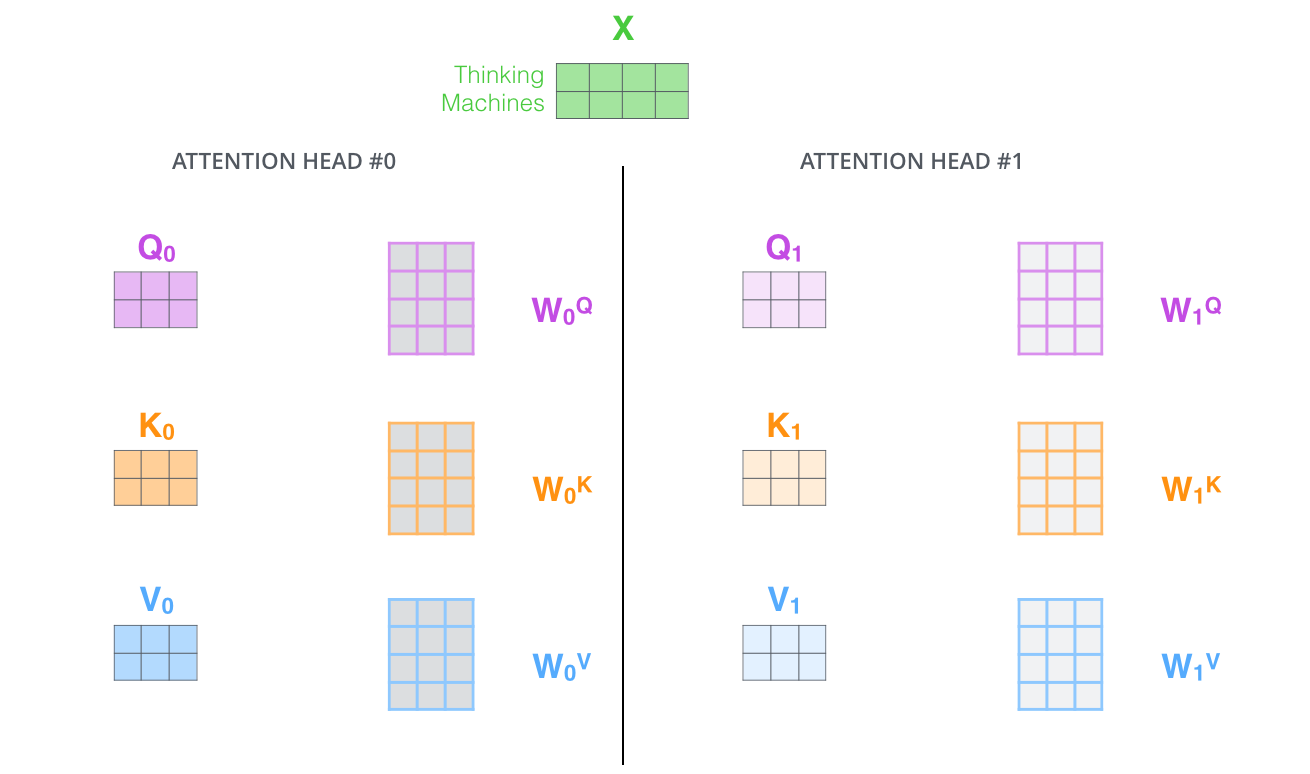
Given input , for each head (from 1 to ), we compute separate queries, keys, and values:
where and , with .
Each head operates in a lower-dimensional subspace. If and , each head works with 64-dimensional queries, keys, and values.
Step 2: Compute Attention Per Head
Each head independently computes scaled dot-product attention:
This produces separate output matrices, each of size .
Step 3: Concatenate All Heads
The outputs from all heads are concatenated along the feature dimension:
This produces a matrix of size .
Step 4: Final Linear Projection
A final weight matrix projects the concatenated output:
 Source: Jay Alammar – The Illustrated Transformer
Source: Jay Alammar – The Illustrated Transformer
This final projection allows the model to learn how to best combine the information from different heads. It also allows cross-head information mixing.
Computational Equivalence
A critical insight: multi-head attention with heads of dimension has roughly the same computational cost as single-head attention with full dimension . You are not paying times the cost. You are splitting the representation into subspaces and running cheaper attention in each.
 Source: The Illustrated Transformer -- Jay Alammar
Source: The Illustrated Transformer -- Jay Alammar
Why It Matters
Multi-head attention is essential because language has multiple simultaneous structures:
- Syntactic structure: Subject-verb agreement, modifier attachment, clause boundaries.
- Semantic relationships: Synonym/antonym detection, topical relevance.
- Coreference: Pronoun resolution, entity tracking across sentences.
- Positional patterns: Attending to adjacent tokens, fixed-distance relationships.
Research has shown that different heads in trained models empirically specialize. Voita et al. (2019) identified specific head roles in Transformer models, including positional heads (attending to adjacent positions), syntactic heads (tracking dependency relations), and rare-word heads (attending to less frequent tokens).
Without multiple heads, a single attention pattern would need to compromise between all these different functions, likely doing none of them well.
Key Technical Details
- Typical head counts: GPT-2 uses 12 heads, GPT-3 uses 96 heads, LLaMA-70B uses 64 heads. The trend is roughly .
- Head dimension: Almost always in modern models, regardless of model size. More heads are added as models get larger, while individual head dimension stays fixed.
- Parameter count: The Q, K, V, and O projection matrices for multi-head attention contain parameters (approximately).
- Not all heads are equally important: Research shows that many heads can be pruned after training with minimal performance loss, suggesting significant redundancy.
Variants: MQA and GQA
The standard multi-head attention (MHA) has separate K and V projections for each head. This creates a problem at inference time: the KV cache (stored keys and values from previous tokens) grows linearly with the number of heads, consuming enormous GPU memory.
Multi-Query Attention (MQA) -- introduced by Shazeer (2019): All heads share a single set of keys and values, while each head still has its own query projection. This dramatically reduces KV cache size (by a factor of ) and speeds up inference, with only a small quality degradation.
Grouped-Query Attention (GQA) -- introduced by Ainslie et al. (2023): A compromise between MHA and MQA. Heads are divided into groups, and heads within each group share K and V projections. If , it is MQA; if , it is standard MHA.
GQA has become the standard in modern models (LLaMA 2 70B, LLaMA 3, Mistral) because it achieves nearly the quality of MHA with most of the efficiency benefits of MQA.
| Variant | Query Projections | KV Projections | KV Cache Size |
|---|---|---|---|
| MHA | separate | separate | |
| GQA | separate | groups () | |
| MQA | separate | 1 shared |
Common Misconceptions
- "Each head attends to different words." Heads do not attend to different words per se; they attend to different relationship types. Two heads might both attend to the same word but for different reasons and with different effects on the output.
- "More heads always means better performance." Beyond a certain point, adding heads provides diminishing returns. Many heads learn redundant patterns. The optimal number of heads is an architectural hyperparameter, not a "more is better" situation.
- "Multi-head attention is times more expensive than single-head." Because each head operates in a -dimensional subspace, the total computation is approximately the same as a single full-dimensional attention. The cost is redistributed, not multiplied.
- "The final linear projection is just reshaping." The output projection is a learned transformation that actively combines information across heads. It is doing meaningful computation, not merely reshaping.
Connections to Other Concepts
self-attention.md: Multi-head attention applies the self-attention mechanism multiple times in parallel (seeself-attention.md).causal-attention.md: Each head in a decoder model applies its own causal mask (seecausal-attention.md).kv-cache.md: MQA and GQA were specifically designed to reduce the memory cost of the KV cache during generation (seeautoregressive-generation.md).transformer-architecture.md: Multi-head attention is the first sub-layer in each Transformer block (seetransformer-architecture.md).- Residual Stream: Each head's output contributes additively to the residual stream (see
residual-connections.md).
Further Reading
- "Attention Is All You Need" -- Vaswani et al., 2017 (original multi-head attention formulation)
- "Fast Transformer Decoding: One Write-Head is All You Need" -- Noam Shazeer, 2019 (introduces Multi-Query Attention)
- "GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints" -- Ainslie et al., 2023 (introduces Grouped-Query Attention)