One-Line Summary: KV cache stores previously computed key and value tensors from the attention mechanism so the model never re-computes them, turning autoregressive generation from an O(n^2) nightmare into an O(n) operation -- at the cost of memory that grows linearly with sequence length.
Prerequisites: Transformer architecture basics, self-attention mechanism (queries, keys, values), matrix multiplication costs, autoregressive (left-to-right) text generation.
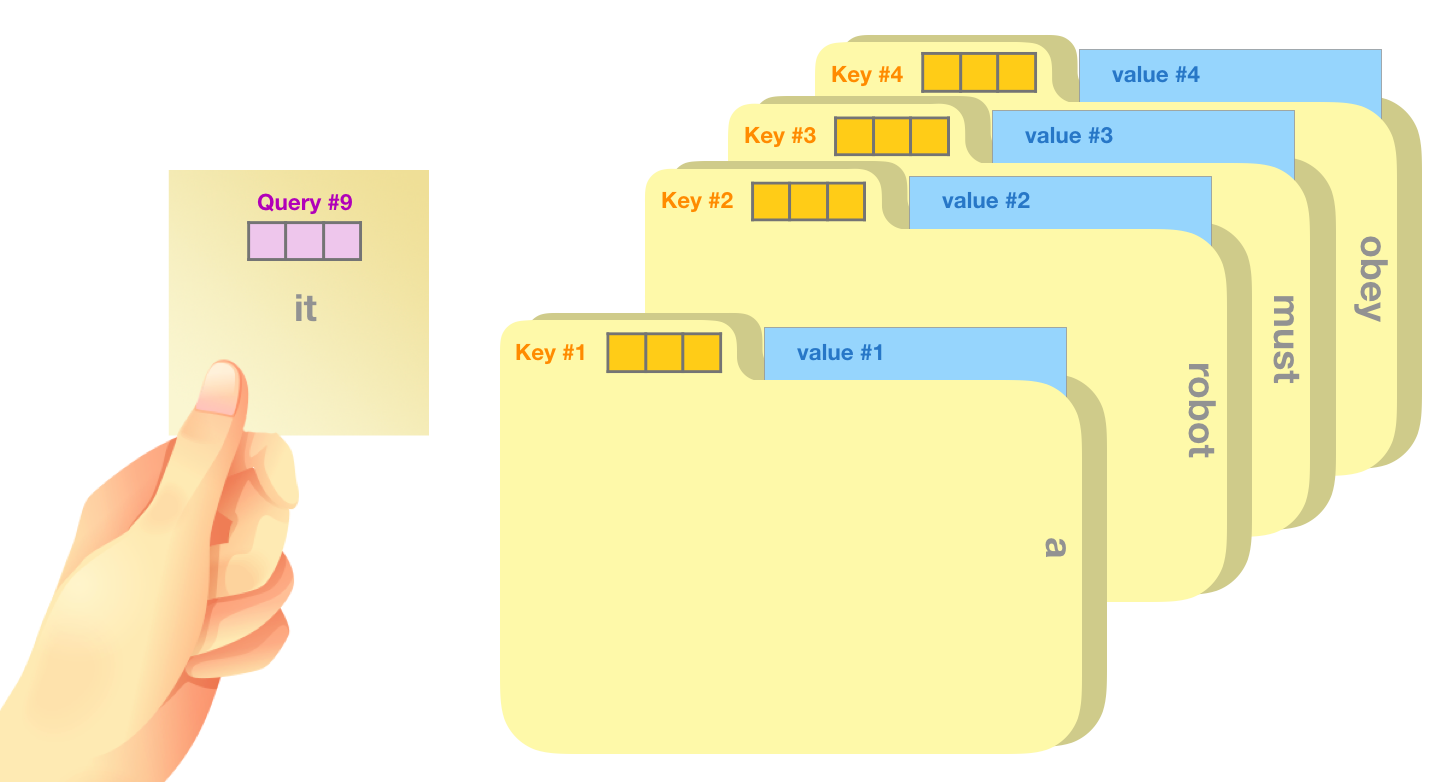
What Is KV Cache?
Imagine you are writing a long essay by hand, and every time you add a new sentence you must re-read the entire essay from the beginning before deciding what comes next. That is what a vanilla transformer does during autoregressive generation: for every new token, it re-computes the attention keys and values for all preceding tokens, even though those tokens have not changed.
 Source: Jay Alammar - The Illustrated GPT-2
Source: Jay Alammar - The Illustrated GPT-2
KV cache is the simple but powerful optimization of saving -- caching -- the key (K) and value (V) projection outputs for every token that has already been processed. When the model generates token number 501, it only needs to compute the Q, K, and V for that single new token, then look up the cached K and V for tokens 1 through 500. The query for the new token attends over the full cached history without any redundant computation.
How It Works
flowchart LR
S1["how KV cache grows during autoregressive g"]
S2["with new K"]
S3["V appended at each step"]
S1 --> S2
S2 --> S3The Problem: Redundant Computation
In standard self-attention during generation, producing token t requires:
- Computing Q, K, V for all tokens 1..t.
- Calculating attention scores:
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k)) V
Since each new token triggers a full recomputation, generating a sequence of length n requires roughly:
where d is the model dimension. This quadratic scaling is devastating for long sequences.
The Solution: Cache and Append
With KV cache, generation proceeds as follows:
- Prefill phase: Process the entire prompt in one forward pass. Store K and V tensors for every layer and every attention head. This is a single parallel computation.
- Decode phase: For each new token:
- Compute Q, K, V for only the single new token.
- Append the new K and V to the cache.
- Compute attention: the new query (1 x d_k) attends over the full cached K (t x d_k) and V (t x d_v).
- Output the next token logits.
The per-step cost is now O(t * d) instead of O(t^2 * d), and the total cost across n steps is:
This is a dramatic reduction -- from quadratic to linear in sequence length.
Calculating KV Cache Size
The memory footprint of a KV cache is:
The factor of 2 accounts for both keys and values. For a concrete example with a 70B-parameter model (80 layers, 64 heads, d_head = 128) at FP16 precision with a sequence length of 4096 and batch size 1:
That is a staggering amount of memory for a single request. For a batch of 32 concurrent users, you would need over 340 GB just for KV caches -- far exceeding most GPU memory.
The Memory Growth Problem
KV cache grows linearly with sequence length per request and linearly with batch size across requests. This makes it the dominant memory consumer during inference, often exceeding the model weights themselves for long-context scenarios. A 128K context window multiplies the figures above by 32x.
flowchart LR
S1["KV cache growth during autoregressive gene"]
S2["previously computed keys and values being "]
S1 --> S2PagedAttention: An OS-Inspired Solution
Traditional KV cache implementations pre-allocate contiguous memory blocks for the maximum possible sequence length per request. This causes severe internal fragmentation -- most requests do not use the full context window, so memory is wasted.
See PagedAttention block table diagram at: vLLM Paper - Efficient Memory Management for LLM Serving with PagedAttention (arXiv:2309.06180)
PagedAttention (introduced by the vLLM project) borrows the concept of virtual memory paging from operating systems:
- KV cache is divided into fixed-size blocks (pages), e.g., 16 tokens per block.
- Blocks are allocated on demand as sequences grow, stored non-contiguously in GPU memory.
- A block table maps logical token positions to physical memory locations.
- When a sequence finishes, its blocks are immediately freed for reuse.
This approach reduces memory waste from 60-80% down to under 4%, enabling 2-4x higher throughput by fitting more concurrent requests into the same GPU memory.
Why It Matters
KV cache is not optional -- it is a hard requirement for practical LLM serving. Without it, generating a 1000-token response from a large model would take minutes instead of seconds. Every production serving framework (vLLM, TGI, TensorRT-LLM) implements KV caching as a foundational optimization. Understanding it is essential for:
- Capacity planning: Knowing how much GPU memory you actually need.
- Latency budgeting: Understanding why long-context requests are expensive.
- Architecture decisions: Choosing between models with different numbers of KV heads (e.g., multi-query attention vs. multi-head attention).
Key Technical Details
- Multi-Query Attention (MQA) and Grouped-Query Attention (GQA) reduce KV cache size by sharing K and V heads. GQA with 8 groups instead of 64 heads reduces KV cache by 8x.
- KV cache can be quantized to INT8 or even INT4 with minimal quality loss, halving or quartering memory usage.
- The prefill phase is compute-bound (processing many tokens in parallel); the decode phase is memory-bandwidth-bound (reading large KV caches for one token at a time).
- Token eviction strategies (like H2O -- Heavy Hitter Oracle) selectively discard less important cached entries to bound memory usage for very long sequences.
- Ring buffers and sliding window attention (as in Mistral) limit KV cache to a fixed window, trading full context for bounded memory.
Common Misconceptions
- "KV cache is an approximation." It is not. KV caching produces mathematically identical results to recomputing everything from scratch. It is purely an efficiency optimization.
- "The model weights are the main memory cost during inference." For long sequences and large batches, KV cache frequently dominates. A 7B model's weights in FP16 are about 14 GB, but its KV cache for a 128K context can exceed 20 GB per request.
- "Increasing batch size always helps throughput." Only up to the point where KV cache memory is exhausted. After that, you either run out of GPU memory or must start offloading, which destroys latency.
- "All attention heads need separate K and V." GQA and MQA show that substantial sharing is possible with minimal quality degradation, and this is now standard practice in modern architectures (Llama 2/3, Mistral).
Connections to Other Concepts
flash-attention.md: Optimizes the compute side of attention; KV cache optimizes the redundancy side. They are complementary.quantization.md: Quantizing KV cache values (KV cache quantization) is a growing area that directly addresses the memory bottleneck.throughput-vs-latency.md: KV cache size directly determines how many requests can be batched, linking it to the fundamental throughput-latency trade-off.model-serving.md: vLLM's PagedAttention, TensorRT-LLM's inflight batching, and TGI's memory management all revolve around efficient KV cache handling.speculative-decoding.md: The draft model maintains its own (smaller) KV cache, and verification re-uses the target model's cache efficiently.
Further Reading
- "Efficient Memory Management for Large Language Model Serving with PagedAttention" (Kwon et al., 2023) -- The vLLM paper that introduced PagedAttention and demonstrated its dramatic throughput improvements.
- "GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints" (Ainslie et al., 2023) -- Describes Grouped-Query Attention, the now-standard approach to reducing KV cache size.
- "H2O: Heavy-Hitter Oracle: Efficient Generative Inference of Large Language Models with Heavy Hitters" (Zhang et al., 2023) -- A KV cache eviction policy based on attention score patterns.