One-Line Summary: The three Transformer paradigms -- encoder-only (BERT), decoder-only (GPT), and encoder-decoder (T5) -- represent fundamentally different choices about how the model processes context, with decoder-only emerging as the dominant architecture for generative AI.
Prerequisites: Understanding of the Transformer architecture (attention, FFN, residual connections), the difference between causal and bidirectional attention, and the concept of pre-training objectives.
What Are the Three Paradigms?
Think of these three architectures as different approaches to reading and writing:
 Source: The Illustrated GPT-2 -- Jay Alammar
Source: The Illustrated GPT-2 -- Jay Alammar
- Encoder-only (BERT): Like a speed reader who absorbs an entire document and then answers questions about it. Can see everything at once but does not generate new text.
- Decoder-only (GPT): Like a writer who composes text left to right, one word at a time, each word informed by everything written so far. Excels at generation.
- Encoder-decoder (T5): Like a translator who first reads the entire source text (encoding), then writes the translation word by word (decoding). Two distinct phases for understanding and generating.
Each paradigm uses the same fundamental building blocks (attention, FFN, residual connections, normalization) but arranges them differently and uses different attention masking strategies, leading to different strengths.
How They Work
 Source: The Illustrated Transformer -- Jay Alammar
Source: The Illustrated Transformer -- Jay Alammar
Encoder-Only (BERT, RoBERTa, DeBERTa)
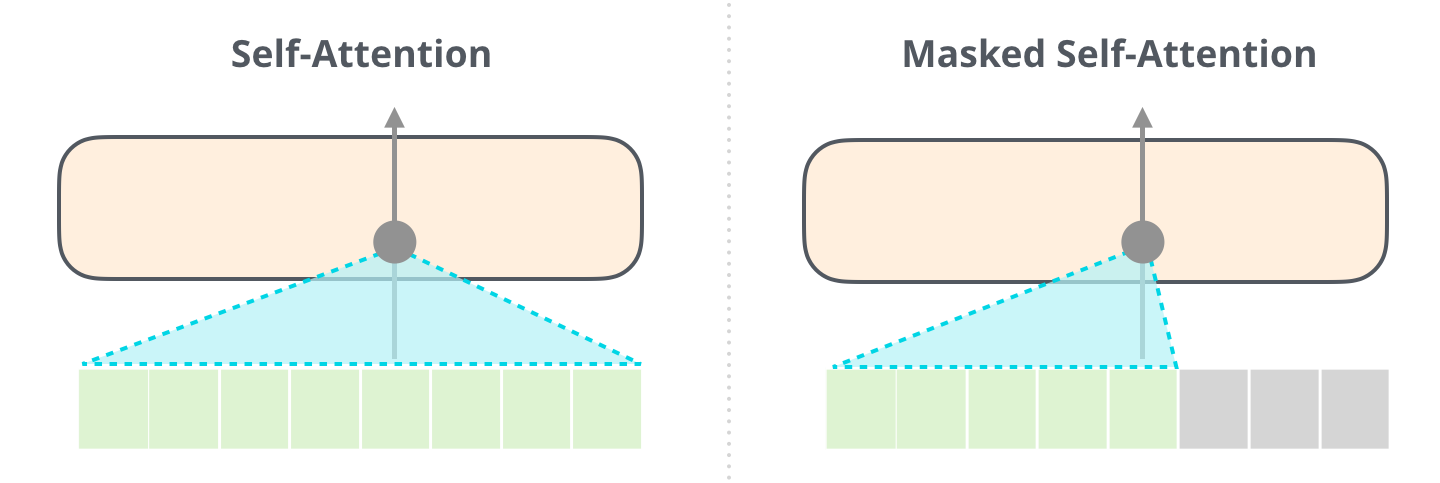
The encoder uses bidirectional attention: every token attends to every other token, including tokens that come after it. There is no causal mask.
 Source: The Illustrated GPT-2 -- Jay Alammar
Source: The Illustrated GPT-2 -- Jay Alammar
Architecture: A stack of Transformer blocks, each containing multi-head self-attention (full, bidirectional) and an FFN.
Training objective: Masked Language Modeling (MLM). Randomly mask 15% of input tokens and train the model to predict them. Because the model can see context from both directions, it can use both left and right context to fill in the blanks.
Example: Input: "The [MASK] sat on the mat." The model uses both "The" and "sat on the mat" to predict "cat."
Strengths: Excellent at understanding tasks -- classification, named entity recognition, question answering, semantic similarity.
Limitation: Cannot generate text naturally. The model produces representations, not sequences. You can extract predictions for masked positions, but there is no mechanism for open-ended generation.
Decoder-Only (GPT, LLaMA, Claude, Mistral)
The decoder uses causal (masked) attention: each token can only attend to itself and previous tokens. Future tokens are masked out.
 Source: Jay Alammar – The Illustrated Transformer
Source: Jay Alammar – The Illustrated Transformer
Architecture: A stack of Transformer blocks, each containing causally-masked multi-head self-attention and an FFN.
Training objective: Next-token prediction (causal language modeling). Given tokens , predict . The causal mask ensures no information leakage from future tokens.
Example: Given "The cat sat on the", the model predicts "mat" (or other plausible continuations).
Strengths: Natural text generation, few-shot learning via prompting, strong general-purpose capabilities.
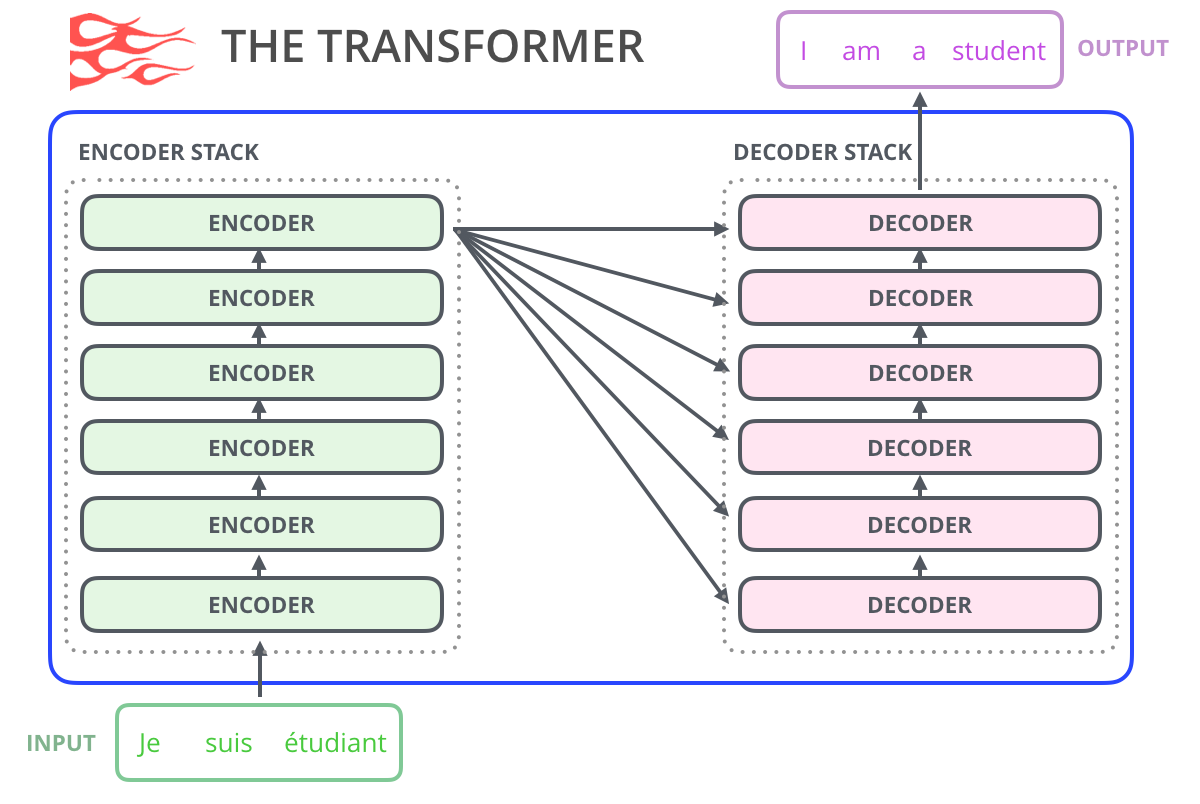
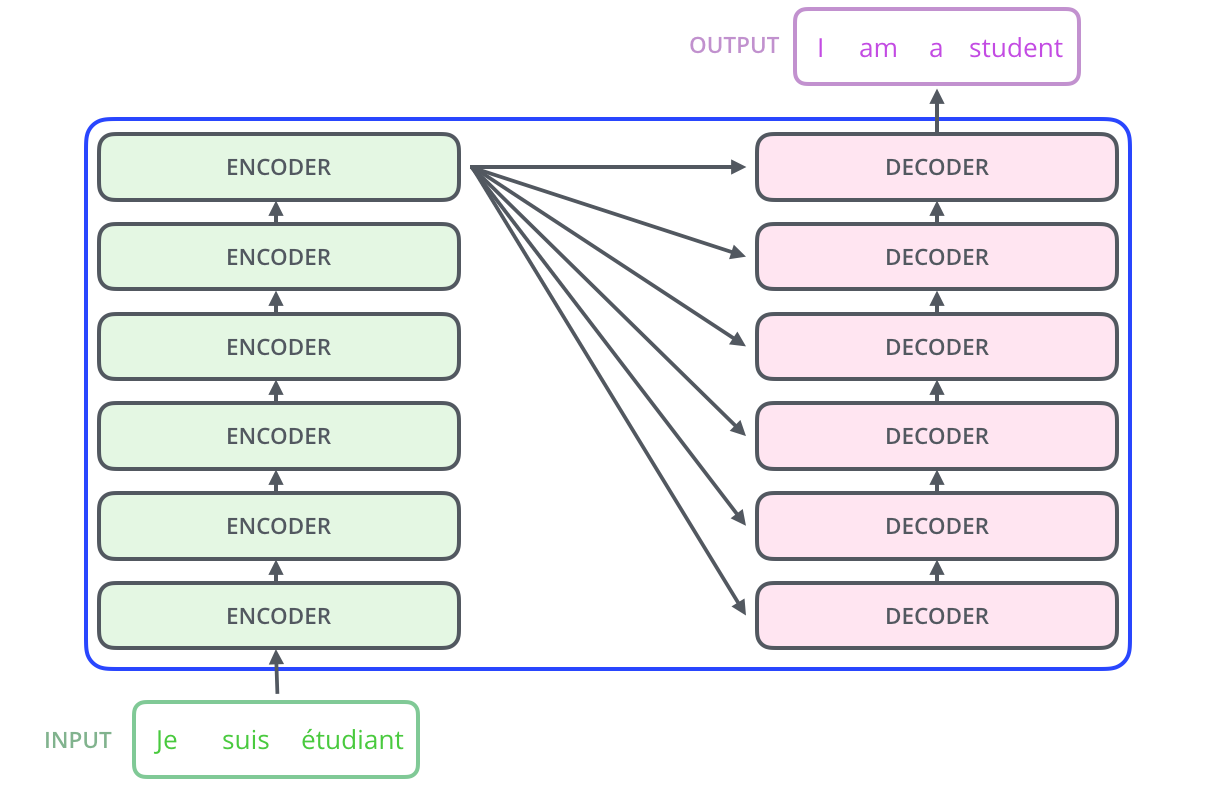
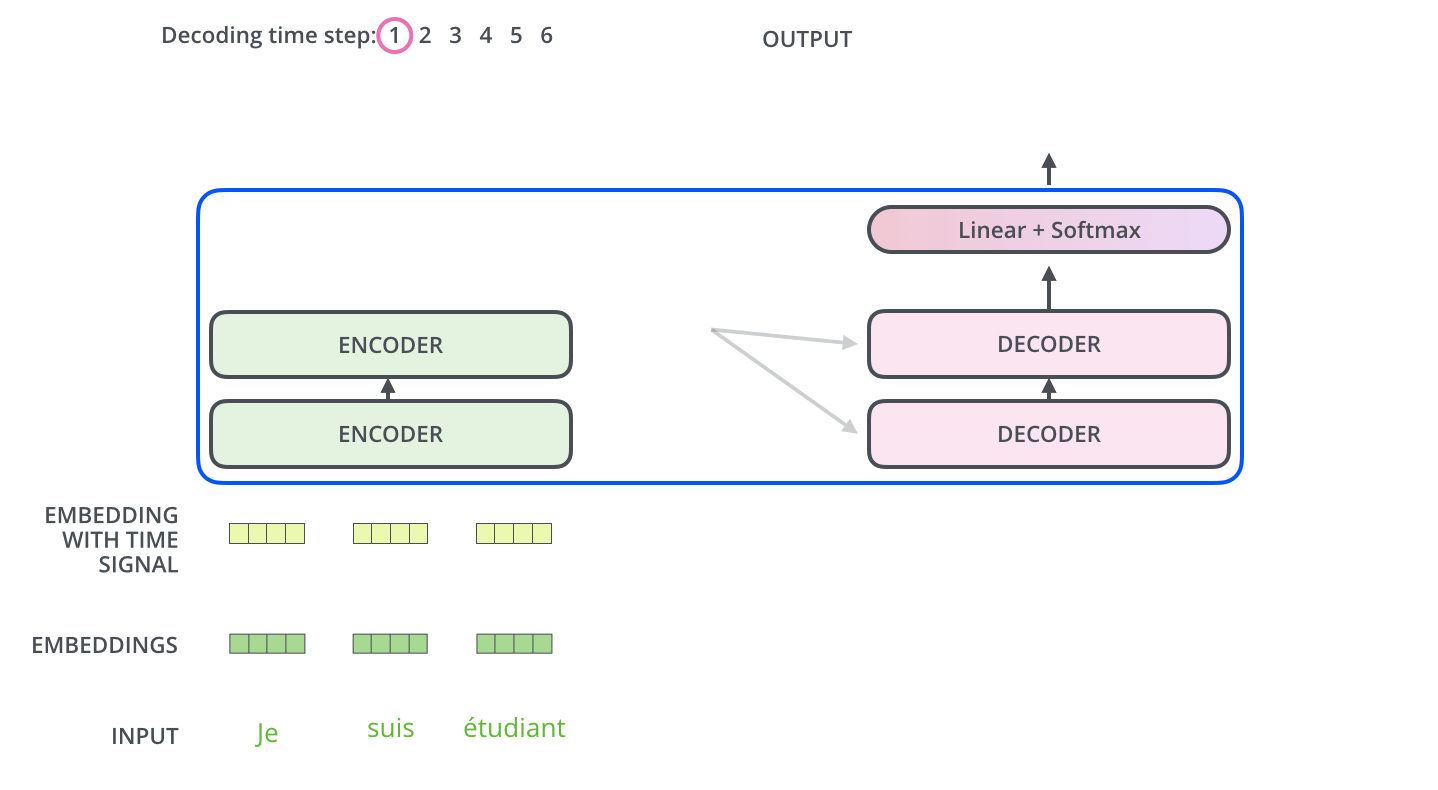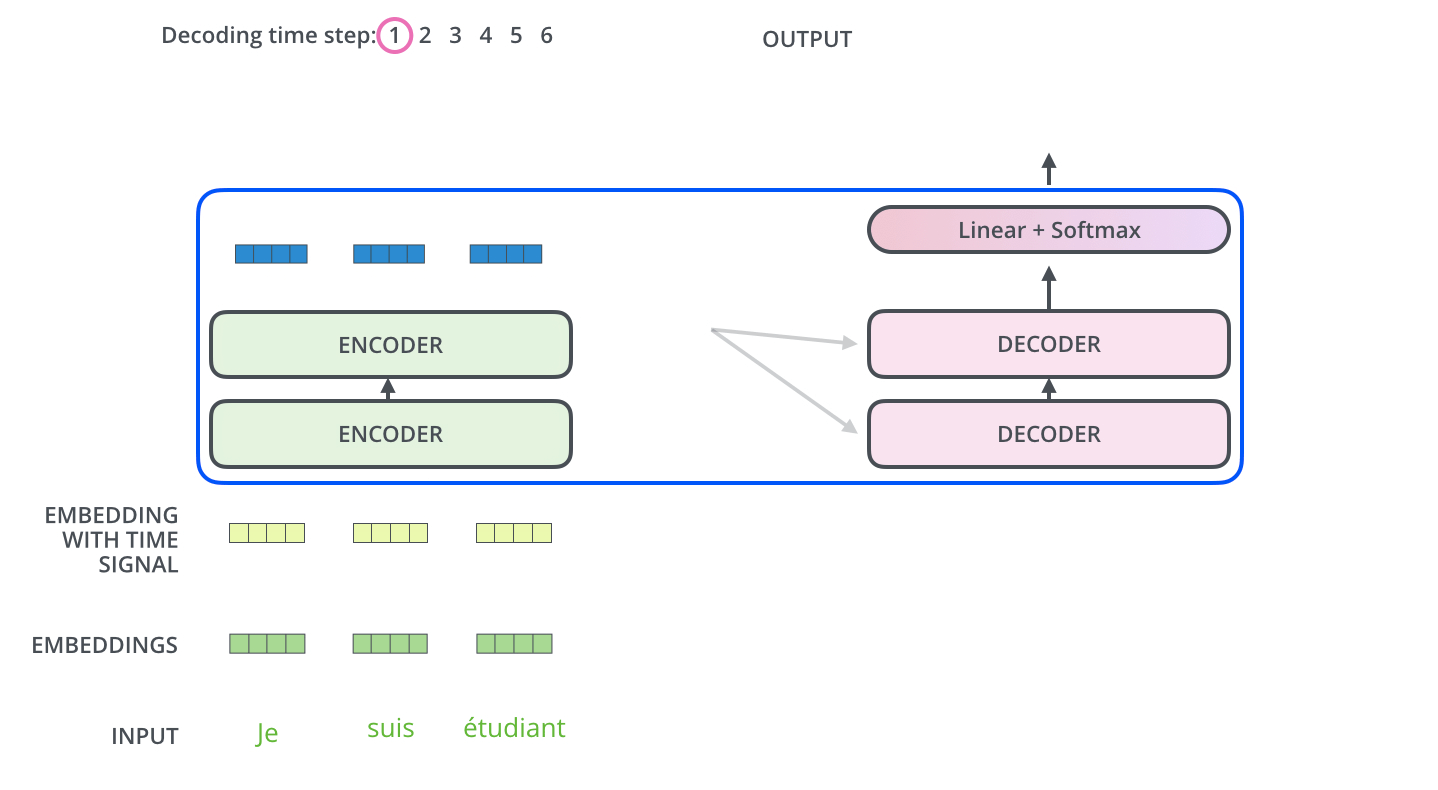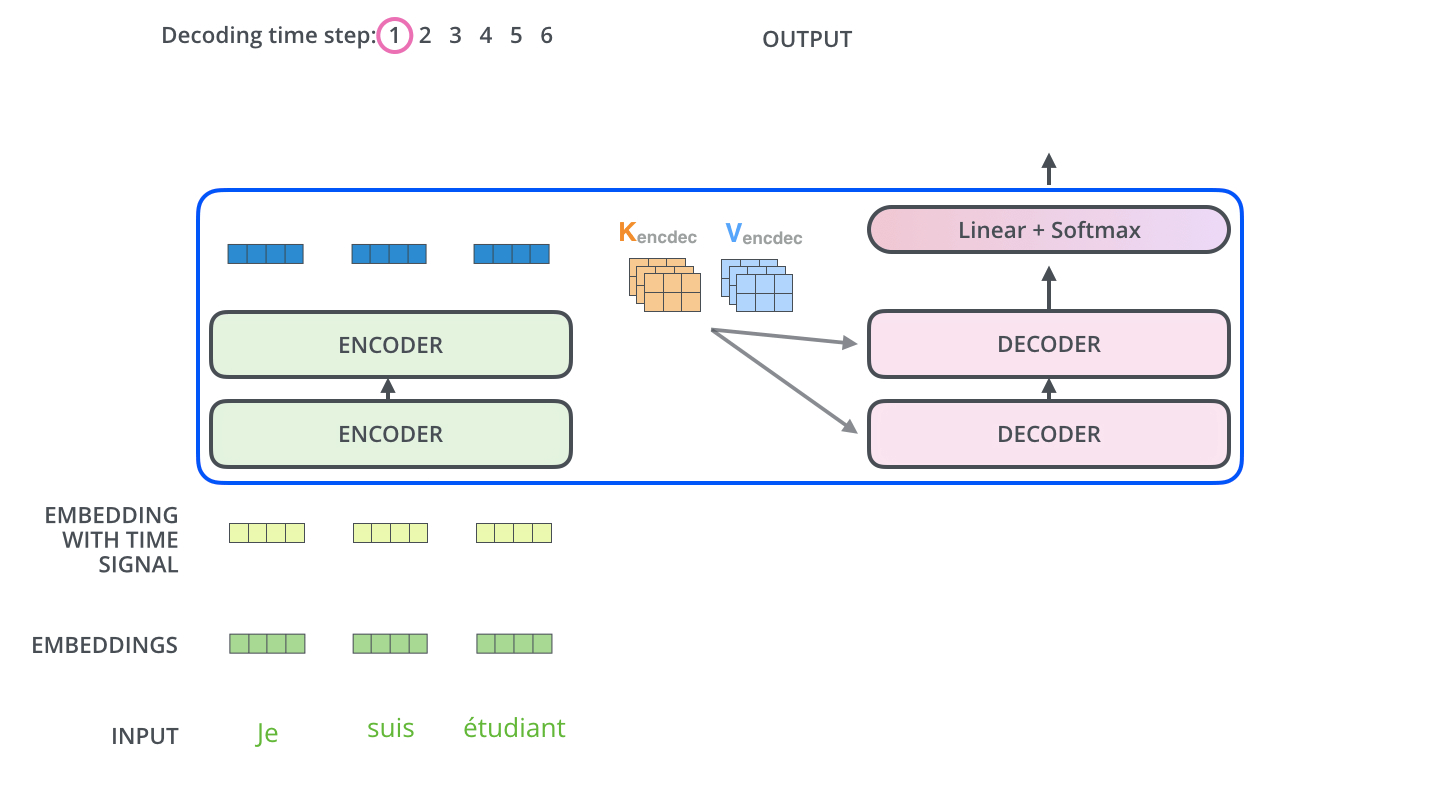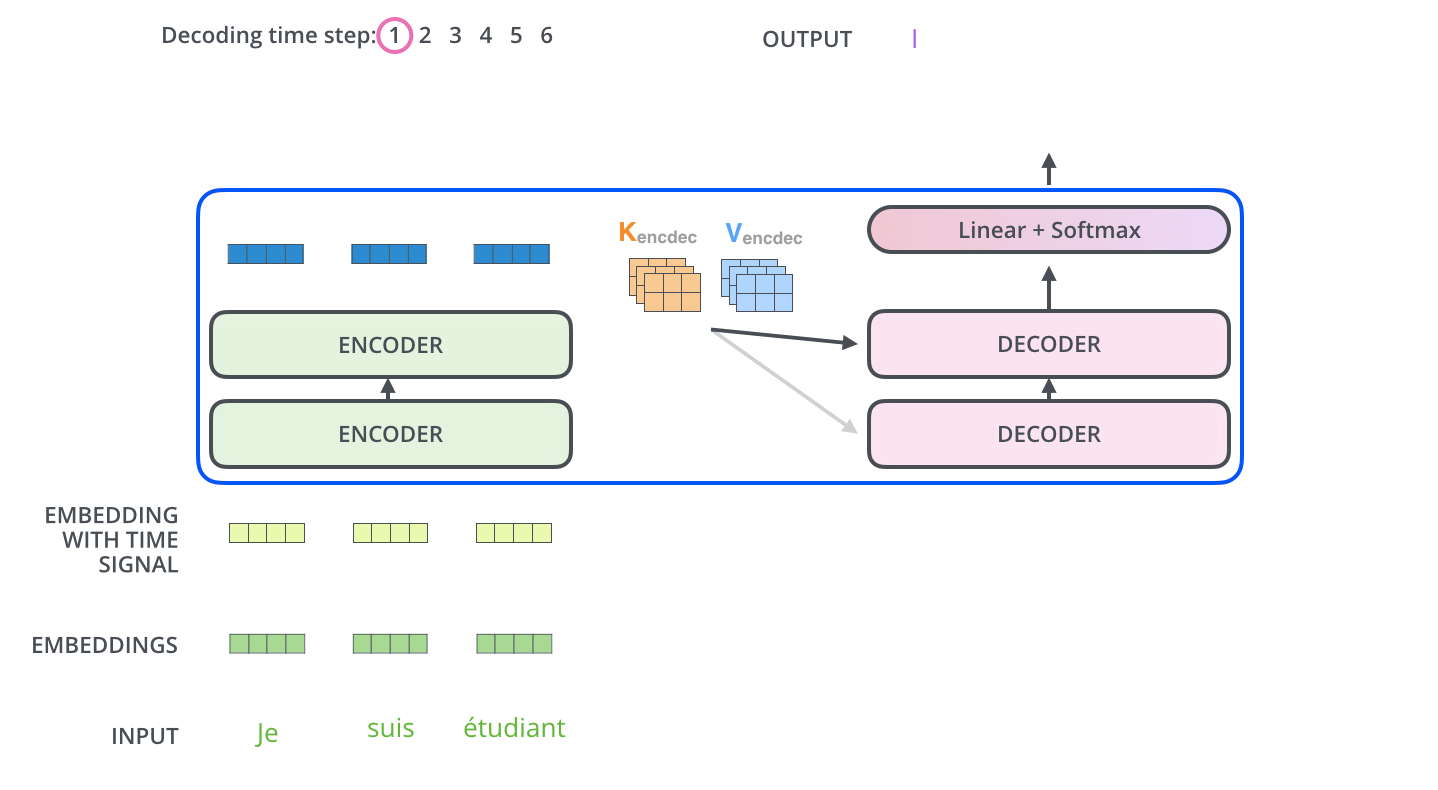
Encoder-Decoder (T5, BART, Flan-T5, mBART)
This is the original Transformer design. The encoder processes the full input with bidirectional attention. The decoder generates output token by token with causal attention, plus cross-attention to the encoder's representations.
Architecture:
- Encoder: Stack of blocks with bidirectional self-attention + FFN.
- Decoder: Stack of blocks with causal self-attention + cross-attention to encoder + FFN.
Cross-attention is the key differentiator: in cross-attention, the decoder's queries attend to the encoder's keys and values. This allows the decoder to "read" the encoded input while generating output.
Training objective: Typically span corruption (T5) or denoising (BART). Mask spans of the input; the encoder sees the corrupted version; the decoder must reconstruct the original spans.
Strengths: Translation, summarization, question answering, and other tasks with clear input-output structure.
Why Decoder-Only Won for Generative AI
The dominance of decoder-only models is one of the most consequential outcomes in modern AI. Several factors contributed:
1. Simplicity and Scalability
Decoder-only has one stack of layers, one attention type (causal), and one training objective (next-token prediction). This simplicity makes scaling straightforward. Encoder-decoder requires managing two separate stacks and cross-attention, adding complexity without clear benefits at massive scale.
2. Flexibility as a Universal Interface
With prompting, a decoder-only model can perform any task. Translation? "Translate the following to French: ..." Summarization? "Summarize: ..." Classification? "Is this positive or negative? ..." The model does not need to be restructured for different tasks; the prompt acts as a task specifier.
3. Compute Efficiency
In encoder-decoder models, the encoder and decoder each do separate work. The total parameter count is split between them, and the cross-attention adds overhead. A decoder-only model puts all parameters into a single stack, and every parameter contributes to both understanding and generation.
4. Emergent Capabilities at Scale
The "scaling laws" research (Kaplan et al., 2020; Chinchilla, 2022) was conducted primarily on decoder-only models. The emergent abilities -- few-shot learning, chain-of-thought reasoning, instruction following -- appeared naturally from scaling next-token prediction. There was less evidence that encoder-decoder models exhibited the same scaling behavior.
5. In-Context Learning
Decoder-only models naturally support in-context learning: provide examples in the prompt, and the model learns the pattern on the fly. This is a natural consequence of the autoregressive left-to-right processing. Encoder-decoder models can do this too, but less naturally (the examples would need to be in the encoder input).
Key Technical Details
| Feature | Encoder-Only | Decoder-Only | Encoder-Decoder |
|---|---|---|---|
| Attention type | Bidirectional | Causal | Bi (encoder) + Causal (decoder) + Cross |
| Generation | Not natural | Native | Native (decoder) |
| Key models | BERT, RoBERTa | GPT-3/4, LLaMA, Claude | T5, BART, mBART |
| Pre-training | MLM | Next-token prediction | Span corruption / denoising |
| Typical use | Classification, NER, QA | General-purpose generation | Translation, summarization |
| Cross-attention | No | No | Yes |
| Parameter efficiency for generation | N/A | All params serve generation | Split between encoder and decoder |
- BERT (2018): 110M (base) / 340M (large) parameters, encoder-only. Revolutionized NLP benchmarks.
- GPT-3 (2020): 175B parameters, decoder-only. Demonstrated few-shot learning.
- T5 (2019): 11B parameters (largest variant), encoder-decoder. Framed every NLP task as text-to-text.
- Modern trend: Almost all frontier models (GPT-4, Claude, Gemini, LLaMA, Mistral) are decoder-only.
Common Misconceptions
- "Decoder-only models cannot understand text, only generate it." Decoder-only models understand text extremely well; they just do it through the lens of next-token prediction. GPT-4 scores high on reading comprehension, reasoning, and analysis benchmarks -- tasks that require deep understanding.
- "Encoder-decoder is better for translation." While encoder-decoder architectures were designed with translation in mind, large decoder-only models match or exceed their translation quality. The architectural advantage for translation has been overwhelmed by scale.
- "BERT is outdated and no longer useful." BERT and its descendants (RoBERTa, DeBERTa) remain highly efficient for classification and retrieval tasks, especially when compute is limited. Not every application needs a 70B-parameter generative model.
- "You need an encoder to understand the input." The decoder processes the input (prompt) with all its layers before generating. By the time generation starts, the model has built rich representations of the input through the causal attention over the prompt tokens. The "prefix" portion of the sequence functions similarly to an encoder.
- "Encoder-decoder models use twice the parameters." In practice, encoder-decoder models are described by their total parameter count. A "T5-11B" model has 11B total, split between encoder and decoder, not 11B in each.
Connections to Other Concepts
causal-attention.md: The mechanism that distinguishes decoders from encoders (seecausal-attention.md).self-attention.md: Both encoders and decoders use self-attention; the difference is masking (seeself-attention.md).autoregressive-generation.md: The generation mechanism used by decoders and decoder-only models (seeautoregressive-generation.md).next-token-prediction.md: The training objective that powers decoder-only models (seenext-token-prediction.md).transformer-architecture.md: All three paradigms are variations of the Transformer (seetransformer-architecture.md).
Further Reading
- "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" -- Devlin et al., 2018 (the definitive encoder-only model)
- "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer" -- Raffel et al., 2019 (the T5 paper, comparing all three paradigms extensively)
- "Language Models are Few-Shot Learners" -- Brown et al., 2020 (GPT-3, demonstrating the power of decoder-only at scale)