One-Line Summary: Token embeddings convert discrete, meaningless token IDs into dense, continuous vectors in a high-dimensional space where geometric relationships encode semantic meaning.
Prerequisites: Understanding of tokenization (how text becomes token IDs), basic linear algebra concepts (vectors, matrices, dot products), and a general sense of how neural networks learn through gradient descent.
What Is Token Embedding?
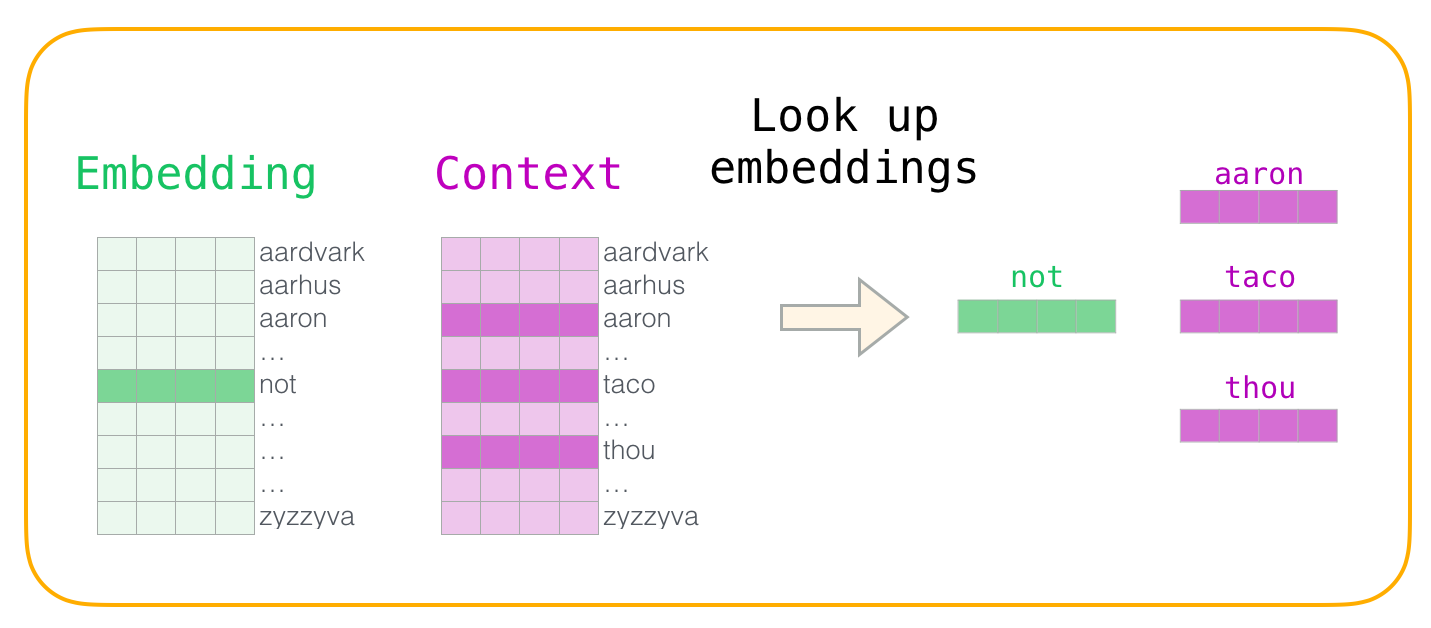
Suppose you have a dictionary of 50,000 words, and you want to represent each word as a number. You could assign "cat" = 1, "dog" = 2, "automobile" = 3, and so on. But this creates a problem: the model would conclude that "cat" is closer to "dog" than to "automobile" simply because 1 is closer to 2 than to 3. The numbering is arbitrary and encodes false relationships.
 Source: Jay Alammar – The Illustrated Word2Vec
Source: Jay Alammar – The Illustrated Word2Vec
Token embeddings solve this by representing each token not as a single number but as a vector -- a list of numbers in a high-dimensional space. "Cat" might be [0.2, -0.5, 0.8, ...] (768 numbers long), and "dog" might be [0.3, -0.4, 0.7, ...]. These vectors are close together because cats and dogs are semantically related. "Automobile" lives in a completely different region of the space.
Think of it like a cosmic map where every word has coordinates, and the distances between coordinates reflect meaning. Words used in similar contexts drift toward each other during training, while unrelated words drift apart. The embedding layer is the model's first translation step: from a flat list of token IDs to a rich geometric landscape of meaning.
How It Works
 Source: Jay Alammar – The Illustrated Word2Vec
Source: Jay Alammar – The Illustrated Word2Vec
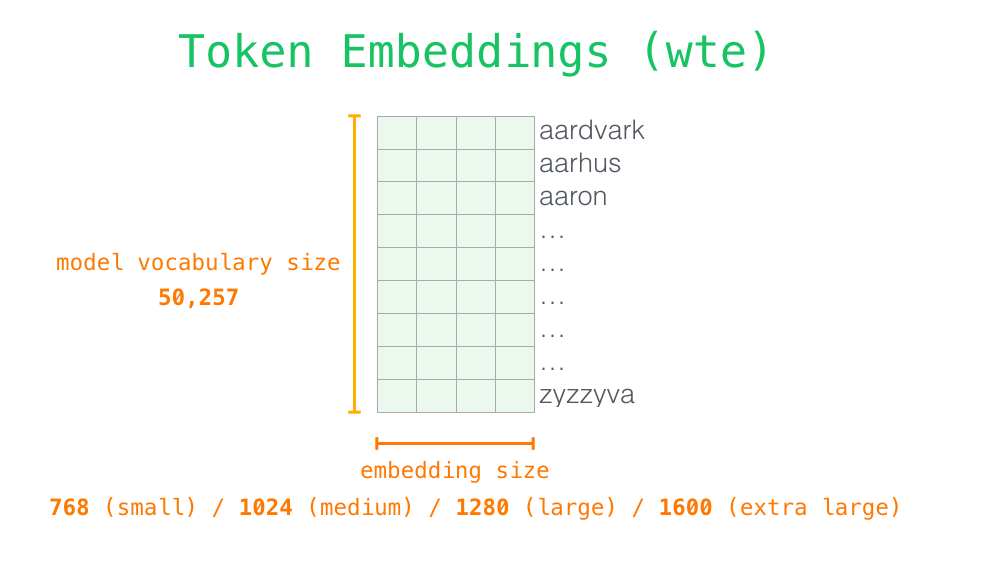
The Embedding Matrix
At the core of token embeddings is a single large matrix , where is the vocabulary size and is the embedding dimension.
- Each row of this matrix is the embedding vector for token .
- To embed token ID 4217, you simply look up row 4217 of the matrix.
Mathematically, this lookup is equivalent to multiplying a one-hot vector by the embedding matrix:
where is a one-hot vector (all zeros except a 1 at position ). In practice, implementations use an index lookup rather than a full matrix multiplication for efficiency.
Embedding Dimensions
The dimension of the embedding vectors is a critical hyperparameter:
| Model | Vocabulary Size | Embedding Dimension |
|---|---|---|
| BERT-base | 30,522 | 768 |
| GPT-2 | 50,257 | 768 |
| GPT-3 (175B) | 50,257 | 12,288 |
| LLaMA-7B | 32,000 | 4,096 |
| LLaMA-70B | 32,000 | 8,192 |
Larger dimensions can encode more nuanced relationships but require more parameters. The embedding matrix for LLaMA-70B contains million parameters -- and this is just the input layer.
How Embeddings Learn Meaning
Embeddings are initialized randomly and learned during training through backpropagation. The key insight comes from the distributional hypothesis: words that appear in similar contexts have similar meanings.
During training, when the model processes "The cat sat on the mat" and "The dog sat on the rug," the gradients push the embeddings for "cat" and "dog" closer together because they appear in similar syntactic and semantic positions. Over billions of training examples, a rich geometric structure emerges.
The King-Queen Analogy
The most famous demonstration of embedding structure is the word analogy:
 Source: Jay Alammar – The Illustrated Word2Vec
Source: Jay Alammar – The Illustrated Word2Vec
This works because the embedding space encodes a "gender" direction. Subtracting from removes the male component, leaving "royalty." Adding reintroduces gender in the female direction, landing near .
This is measured using cosine similarity:
In practice, modern LLM embeddings are more complex than Word2Vec-era embeddings. The analogies still hold approximately but are less clean because each token's representation is contextually modulated by the transformer layers above.
Weight Tying
A powerful technique used in many models (GPT-2, LLaMA, T5, and others) is weight tying (also called weight sharing): using the same matrix for both the input embeddings and the output projection layer.
 Source: Jay Alammar – The Illustrated GPT-2
Source: Jay Alammar – The Illustrated GPT-2
The output layer computes logits for next-token prediction:
where is the final hidden state. The logit for token is the dot product -- essentially measuring how similar the model's prediction vector is to each token's embedding.
Weight tying has two benefits:
- Parameter reduction: For a vocabulary of 50K and dimension 12,288, this saves ~600 million parameters.
- Improved coherence: It enforces that the space used to understand input tokens is the same space used to predict output tokens, creating a consistent semantic geometry.
Why It Matters
Token embeddings are the foundation upon which all subsequent transformer processing is built. Every attention computation, every feedforward transformation, every residual connection operates on these vectors. If the embeddings poorly represent meaning, no amount of subsequent processing can fully compensate.
Embeddings also matter practically:
- Retrieval-Augmented Generation (RAG) systems use embeddings (often from the model's encoder or specialized embedding models) to find relevant documents by comparing vector similarity.
- Semantic search relies entirely on embedding quality to match queries to results beyond keyword overlap.
- Transfer learning works because pretrained embeddings carry rich semantic knowledge to downstream tasks.
- Model merging and fine-tuning techniques manipulate embedding spaces, and understanding their geometry is essential for these advanced techniques.
Key Technical Details
- The embedding matrix is typically the single largest parameter block in smaller models. For a 125M parameter model with a 50K vocabulary and 768 dimensions, the embedding matrix alone is ~38M parameters (30% of the model).
- Embeddings are added to positional encodings element-wise before being fed into the transformer: .
- In modern LLMs, the raw token embedding is just the starting point. The contextual representation after passing through transformer layers is far more expressive -- the same token "bank" will have different representations in "river bank" vs. "bank account" after the first few layers.
- Scaling laws research suggests embedding dimension should grow roughly as where is total model parameters, though practical choices vary.
- Embedding vectors are typically normalized (or the model learns to keep them in a reasonable range) to prevent numerical instability.
Common Misconceptions
- "Each dimension of an embedding has a specific meaning." Individual dimensions are not interpretable in isolation. Meaning is encoded in the relationships between dimensions, much like how individual pixels don't convey the meaning of an image.
- "Embeddings are fixed after pretraining." During fine-tuning, embeddings continue to update. In full fine-tuning, the entire embedding matrix is modified. Even in LoRA, embedding layers can optionally be adapted.
- "Token embeddings and word embeddings (Word2Vec) are the same thing." Word2Vec produces static embeddings -- one vector per word regardless of context. Token embeddings in transformers are an input layer; the transformer layers above create context-dependent representations. The initial embedding is static per token, but the representation after even one attention layer is contextualized.
- "Bigger embedding dimensions are always better." Beyond a certain point, larger dimensions lead to overfitting, wasted computation, and diminishing returns. The right dimension depends on model size and training data volume.
Connections to Other Concepts
tokenization.md: Produces the token IDs that index into the embedding matrix. The vocabulary defined by the tokenizer determines the number of rows in .positional-encoding.md: Added to token embeddings to inject sequence order information before the transformer layers process the input.vocabulary-design.md: The size and composition of the vocabulary directly determine the shape and efficiency of the embedding matrix.attention-mechanism.md: Operates on the embedded (and positionally encoded) vectors. Attention queries, keys, and values are all linear projections of these representations.context-window.md: Each position in the context window corresponds to one embedding vector; the total input to the transformer is a sequence of these vectors.
Further Reading
- Mikolov, T., et al. (2013). "Efficient Estimation of Word Representations in Vector Space." arXiv:1301.3781. -- The Word2Vec paper that popularized word embeddings and demonstrated the king-queen analogy.
- Press, O. & Wolf, L. (2017). "Using the Output Embedding to Improve Language Models." EACL 2017. -- Introduced weight tying between input and output embeddings with rigorous analysis of why it works.
- Ethayarajh, K. (2019). "How Contextual are Contextualized Word Representations?" EMNLP 2019. -- Analyzes how embeddings in different layers of transformers become increasingly context-specific.