One-Line Summary: Supervised fine-tuning transforms a raw language model that merely predicts the next token into an assistant that can follow instructions, by training it on curated (instruction, response) pairs.
Prerequisites: Understanding of pre-training and language modeling objectives, the transformer architecture, and basic concepts of transfer learning and gradient descent.
What Is Supervised Fine-Tuning?
Imagine you've hired someone with encyclopedic knowledge -- they've read every book, every website, every forum post. They know an astonishing amount. But if you ask them "Can you summarize this document for me?", they might just... keep writing more document-like text. They know about everything, but they don't know how to help you.
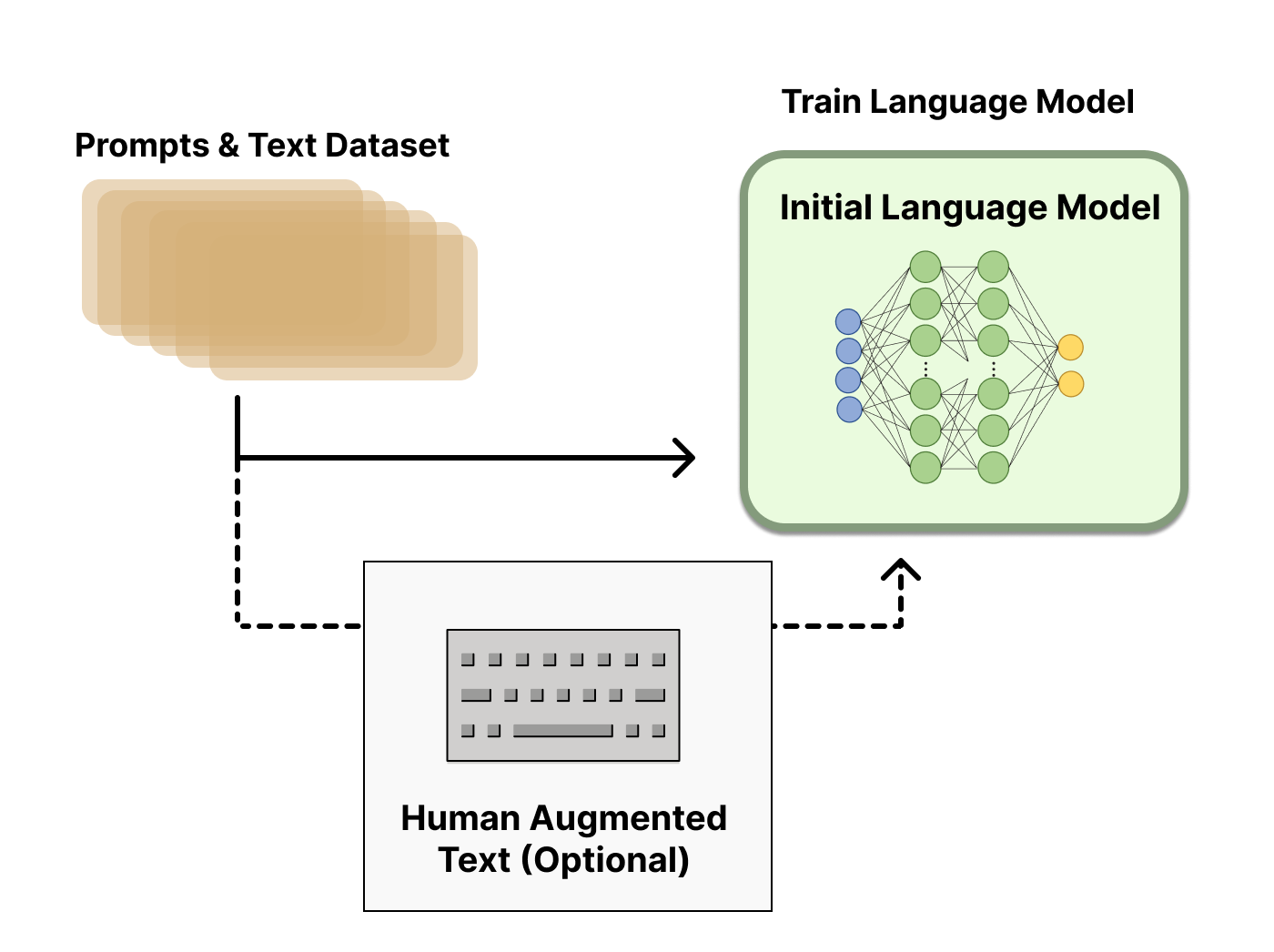 Source: Hugging Face – Illustrating RLHF
Source: Hugging Face – Illustrating RLHF
Supervised fine-tuning (SFT) is the process of teaching that knowledgeable entity how to be helpful. It takes a pre-trained base model -- one that has absorbed vast amounts of text and learned the statistical structure of language -- and trains it further on carefully curated examples of desired behavior. These examples typically take the form of (instruction, response) pairs: "When a user asks X, a good response looks like Y."
Instruction tuning is a specific and hugely influential form of SFT where the training data is explicitly structured around instructions. Rather than fine-tuning for a single downstream task (like sentiment classification), instruction tuning trains the model across hundreds or thousands of task types simultaneously, teaching it the meta-skill of instruction following itself.
How It Works
flowchart LR
S1["SFT training on instruction-response pairs"]
S2["how a base model becomes an instruction-fo"]
S1 --> S2The Basic Pipeline
-
Start with a pre-trained base model: A model like LLaMA or GPT that has been trained on trillions of tokens of text using a next-token prediction objective.
-
Curate an instruction dataset: Collect or generate a dataset of (instruction, response) pairs. Examples might include:
- ("Translate this sentence to French: 'Hello, how are you?'", "Bonjour, comment allez-vous ?")
- ("Write a Python function to reverse a string.", "
python\ndef reverse_string(s): return s[::-1]\n") - ("Summarize the key themes of Hamlet.", "The key themes of Hamlet include...")
-
Format the data: Structure inputs using a chat template or prompt format that the model will learn to recognize. A common format:
<|system|>You are a helpful assistant.<|end|> <|user|>{instruction}<|end|> <|assistant|>{response}<|end|> -
Fine-tune with standard cross-entropy loss: The training objective is identical to pre-training -- next-token prediction -- but only the response tokens contribute to the loss. The instruction tokens are included in the context but masked from the loss computation.
The Loss Function
The SFT objective is the standard language modeling loss applied selectively:
Where includes both the instruction and all preceding response tokens. By masking the instruction tokens from the loss, we tell the model: "Don't learn to generate instructions -- learn to generate good responses given instructions."
Multi-Task Instruction Tuning
The breakthrough insight behind models like FLAN (Fine-tuned LAnguage Net) was that training on a mixture of many tasks simultaneously produces a model that generalizes to unseen tasks. FLAN-T5 and FLAN-PaLM were fine-tuned on over 1,800 tasks grouped into categories (translation, summarization, reasoning, QA, etc.). The model learns not just individual task solutions but the abstract concept of "follow whatever instruction is given."
This is often formalized as:
Where is the number of task types and controls the mixing weight for each task category.
Domain-Adaptive Fine-Tuning
A variant of SFT focuses not on instruction-following broadly but on adapting a model to a specific domain. For example, fine-tuning a general model on medical literature and clinical Q&A pairs to create a medical assistant. This often happens in two stages: (1) continued pre-training on domain-specific text (domain-adaptive pre-training), followed by (2) instruction fine-tuning on domain-specific instruction pairs.
Why It Matters
SFT is the single most important step in turning a base model into a useful product. Without it, even the most capable base model is essentially a sophisticated autocomplete engine. The entire chatbot revolution -- from ChatGPT to Claude to Gemini -- depends on this step.
The FLAN papers demonstrated something remarkable: instruction tuning on a sufficiently diverse set of tasks could produce a model that follows instructions it has never seen before. This is the "instruction-following as a meta-skill" insight that unlocked the modern era of AI assistants. Before FLAN, the dominant paradigm was to fine-tune a separate model for each task. After FLAN, a single fine-tuned model could handle an open-ended range of requests.
SFT is also the bridge to further alignment. RLHF and DPO build on top of an SFT model -- you need a model that already understands the basic format of instruction-following before you can refine its outputs using preference data.
Key Technical Details
- Data quality dominates data quantity. The LIMA paper ("Less Is More for Alignment") showed that fine-tuning on just 1,000 carefully curated examples could rival models trained on tens of thousands of lower-quality examples. A small number of high-quality, diverse examples is far more valuable than a large noisy dataset.
- SFT can be done with remarkably little data. While pre-training requires trillions of tokens, effective SFT can happen with as few as 1,000-100,000 examples, because it is adjusting behavior, not teaching knowledge.
- Loss masking is critical. Only computing loss on response tokens (not instruction tokens) ensures the model learns to respond rather than to parrot instructions.
- Formatting consistency matters. The model learns the chat template as part of its behavior. Inconsistent formatting in training data leads to inconsistent behavior at inference time.
- Catastrophic forgetting is a real risk. Aggressive fine-tuning can cause the model to lose pre-trained knowledge. This is managed through low learning rates (typically 1e-5 to 5e-5), short training schedules (1-5 epochs), and sometimes mixing in pre-training data.
- Common SFT datasets include OpenAssistant Conversations, ShareGPT (real user-ChatGPT conversations), Dolly, and various synthetic instruction datasets.
Common Misconceptions
- "SFT teaches the model new knowledge." Mostly false. SFT primarily teaches the model a new behavior pattern -- how to format and present knowledge it already has. The knowledge comes from pre-training. SFT can introduce some new factual content, but its primary function is behavioral.
- "More SFT data is always better." Quality consistently beats quantity. Redundant or low-quality data can actually degrade performance through overfitting to artifacts.
- "SFT and RLHF are alternatives." They are sequential steps. Nearly all modern alignment pipelines apply SFT first, then RLHF or DPO on top. SFT gets the model into the right ballpark; preference optimization refines it.
- "Instruction tuning is the same as prompt engineering." Instruction tuning permanently changes the model's weights. Prompt engineering changes the input at inference time without modifying the model. Instruction tuning makes the model inherently responsive to instructions.
Connections to Other Concepts
pre-training.md: provides the foundation of knowledge and language understanding that SFT reshapes into useful behavior.rlhf.md: build on SFT to further refine model outputs based on human preferences, handling the subtleties that (instruction, response) pairs alone cannot capture.lora.md: make SFT practical for smaller organizations by reducing the computational cost of fine-tuning.synthetic-data.md: is increasingly used to create SFT datasets, with stronger models generating training data for weaker ones (distillation).trajectory-evaluation.md: (like MT-Bench and AlpacaEval) specifically measure the quality of instruction-following that SFT enables.
Further Reading
- "Scaling Instruction-Finetuned Language Models" (Chung et al., 2022) -- The FLAN-T5/FLAN-PaLM paper that demonstrated the power of multi-task instruction tuning at scale.
- "LIMA: Less Is More for Alignment" (Zhou et al., 2023) -- The landmark paper showing that 1,000 carefully curated examples can produce a remarkably capable instruction-following model.
- "Training Language Models to Follow Instructions with Human Feedback" (Ouyang et al., 2022) -- The InstructGPT paper that describes the full SFT-then-RLHF pipeline that became the industry standard.