One-Line Summary: Causal attention restricts each token to attend only to itself and preceding tokens by applying a triangular mask to the attention matrix, enforcing the left-to-right autoregressive property required for text generation.
Prerequisites: Understanding of self-attention (the Q, K, V mechanism and softmax), the concept of autoregressive generation, and why language models predict the next token.
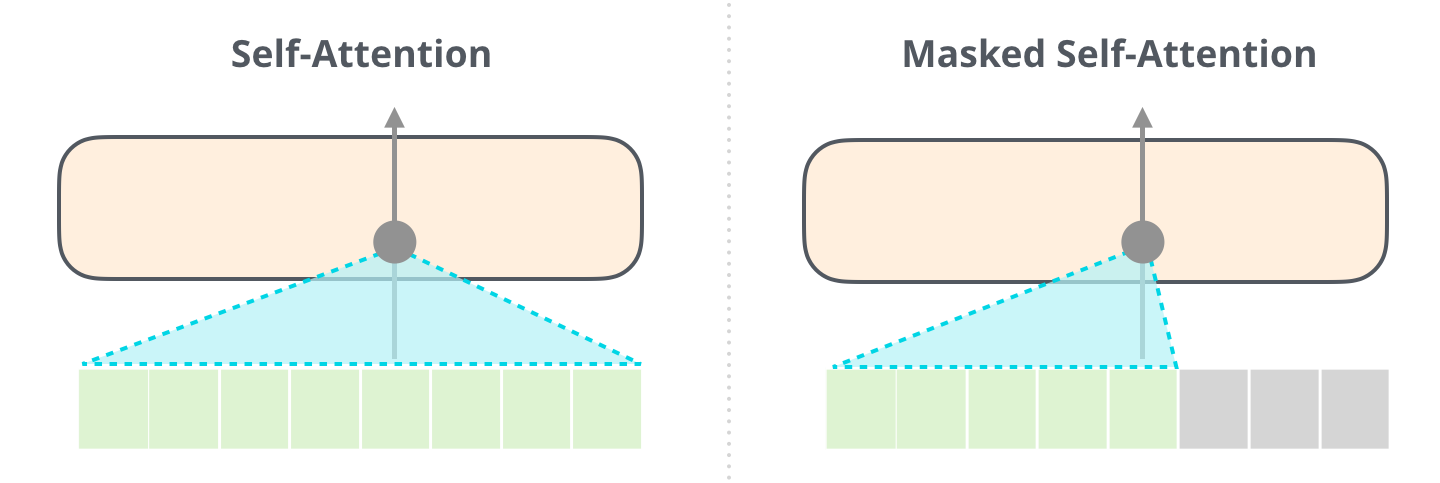
What Is Causal Attention?
Imagine you are taking an exam where each question builds on the previous one. You are allowed to look back at your earlier answers, but you absolutely cannot peek ahead at questions you have not reached yet. Causal attention enforces exactly this rule for language models: when computing the representation for token at position , the model can only "see" tokens at positions . It is blind to positions .
 Source: Jay Alammar – The Illustrated GPT-2
Source: Jay Alammar – The Illustrated GPT-2
This constraint is called "causal" because it enforces a causal ordering: the representation of a token can only be caused (influenced) by tokens that came before it, never by tokens from the future.
The term "masked" comes from the implementation: a mask is applied to the attention scores before softmax, setting all "future" positions to negative infinity so they receive zero attention weight.
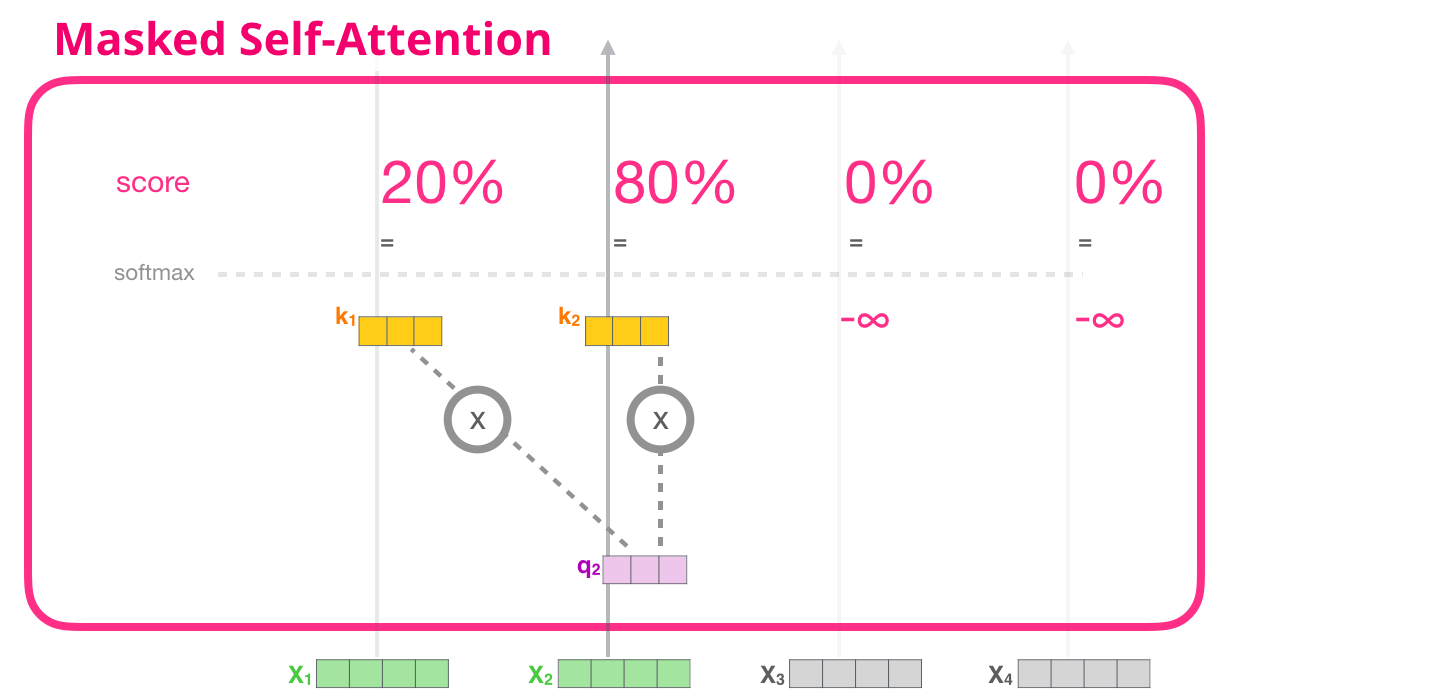
How It Works
 Source: Jay Alammar – A Visual Guide to Using BERT
Source: Jay Alammar – A Visual Guide to Using BERT
Step 1: Compute Attention Scores (Same as Standard)
As in regular self-attention, compute:
Step 2: Apply the Causal Mask
Construct an upper-triangular mask matrix where:
Add this mask to the scores:
The mask matrix looks like this (for a sequence of length 5):
[ 0 -inf -inf -inf -inf ]
[ 0 0 -inf -inf -inf ]
[ 0 0 0 -inf -inf ]
[ 0 0 0 0 -inf ]
[ 0 0 0 0 0 ]Step 3: Apply Softmax
Because , the softmax assigns exactly zero weight to all future positions. The resulting attention matrix is lower-triangular:
[ 1.0 0 0 0 0 ]
[ 0.4 0.6 0 0 0 ]
[ 0.1 0.3 0.6 0 0 ]
[ 0.2 0.1 0.3 0.4 0 ]
[ 0.1 0.1 0.2 0.2 0.4 ]Each row sums to 1.0, and all entries above the diagonal are exactly 0.
Step 4: Compute Output (Same as Standard)
Token at position receives a weighted combination of values only from positions through .
Why Instead of 0?
A common question: why not just set the scores to 0 for masked positions? Because softmax of 0 is not 0 -- it is , which would give future tokens a nonzero attention weight. Only (in practice, a very large negative number like ) ensures after softmax.
Why It Matters
Causal masking is the mechanism that makes autoregressive language modeling possible. Without it, when predicting token , the model could cheat by looking at the actual token in the input. The mask prevents this information leakage.
Training Efficiency
Causal masking provides an enormous practical benefit: parallel training on all positions simultaneously. During training, the model processes an entire sequence at once. The causal mask ensures that the prediction for position uses only information from positions , even though the full sequence is available in the batch. This means we compute predictions for all positions in a single forward pass and compute loss terms simultaneously.
Without the mask, we would need to process positions sequentially (as in an RNN) or run separate forward passes. The mask makes it possible to train efficiently while maintaining the autoregressive property.
The Difference from Bidirectional Attention
In encoder models like BERT, there is no causal mask. Every token attends to every other token, including tokens that come after it. This is called bidirectional (or full) attention. BERT uses this because its training objective (masked language modeling) requires understanding the full context to fill in blanked-out words.
| Property | Causal (Decoder) | Bidirectional (Encoder) |
|---|---|---|
| Attention scope | Past + current only | All positions |
| Mask shape | Lower triangular | No mask (full matrix) |
| Use case | Text generation | Text understanding |
| Models | GPT, LLaMA, Claude | BERT, RoBERTa |
| Training objective | Next-token prediction | Masked token prediction |
In the original encoder-decoder Transformer, the encoder uses bidirectional attention and the decoder uses causal attention. Modern decoder-only models use causal attention exclusively.
Key Technical Details
- Implementation: In practice, the mask is often represented as a boolean tensor and applied using
torch.whereor by adding values. Flash Attention kernels build the causal mask into the fused attention computation for efficiency. - Prefix LM variant: Some models (e.g., PaLM for certain tasks, T5 in some configurations) use a "prefix" approach where the first tokens use bidirectional attention (no mask) and subsequent tokens use causal attention. This is useful when the input has a known-complete prompt followed by generation.
- Computational saving: Because the upper triangle of the attention matrix is always zero, efficient implementations can skip computing those entries entirely, reducing attention computation by roughly half.
- KV cache connection: During autoregressive generation, the causal mask means each new token only needs to compute attention against cached keys/values from previous tokens plus its own. It never looks forward, so the cache is append-only.
- The mask does not add parameters: The causal mask is a fixed structural constraint, not a learned component. It adds zero parameters to the model.
Common Misconceptions
- "Causal attention means the model cannot understand context." Causal attention prevents attending to future tokens, but the model can still develop rich contextual understanding of everything before the current position. After many layers, representations become highly contextualized.
- "The mask is applied after softmax." No. The mask (adding ) is applied before softmax. Applying it after would be too late, as softmax would have already distributed weight to future tokens.
- "Causal attention is less powerful than bidirectional attention." For generation tasks, causal attention is not less powerful; it is appropriate. Using bidirectional attention for generation would allow information leakage and make the model unable to generate text at inference time (when future tokens do not exist yet).
- "Each layer applies a different mask." The causal mask is the same in every layer -- it is a fixed structural property of the architecture, not something that varies or is learned.
Connections to Other Concepts
self-attention.md: Causal attention is self-attention with an additional masking step (seeself-attention.md).autoregressive-generation.md: The causal mask is what enables the left-to-right generation process (seeautoregressive-generation.md).next-token-prediction.md: Causal masking is essential for the training objective to work correctly (seenext-token-prediction.md).encoder-decoder-architecture.md: The distinction between causal and bidirectional attention defines the difference between encoder and decoder (seeencoder-decoder-architecture.md).kv-cache.md: The append-only nature of the KV cache is a direct consequence of the causal mask.
Further Reading
- "Attention Is All You Need" -- Vaswani et al., 2017 (introduces the masked attention mechanism in the decoder)
- "Language Models are Unsupervised Multitask Learners" -- Radford et al., 2019 (GPT-2 paper, demonstrating the power of decoder-only causal models)
- "What Can Transformers Learn In-Context? A Case Study of Simple Function Classes" -- Garg et al., 2022 (explores the capabilities that emerge from the causal attention structure)