One-Line Summary: Reward modeling trains a neural network to predict human preferences over model outputs, producing a scalar score that serves as the optimization signal for reinforcement learning from human feedback -- and its quality is the single biggest bottleneck in the entire alignment pipeline.
Prerequisites: Understanding of RLHF at a high level, the Bradley-Terry model for pairwise comparisons, supervised learning and classification losses, and the concept of Goodhart's Law.
What Is Reward Modeling?
When we say a response is "good" or "helpful," we're making a complex, multidimensional judgment. A reward model is an attempt to distill that judgment into a single number -- a scalar score that captures how much a human would prefer one response over another.
 Source: Hugging Face – Illustrating RLHF
Source: Hugging Face – Illustrating RLHF
Think of a reward model as training an automated film critic. You show the critic thousands of pairs of movies along with audience preferences ("audiences preferred Movie A over Movie B"). Over time, the critic develops an internal model of what makes a good movie -- pacing, acting, story coherence, emotional impact. But the critic isn't perfect: it might overweight surface-level features (explosion count) and underweight subtle ones (thematic depth). This imperfection is the core challenge of reward modeling.
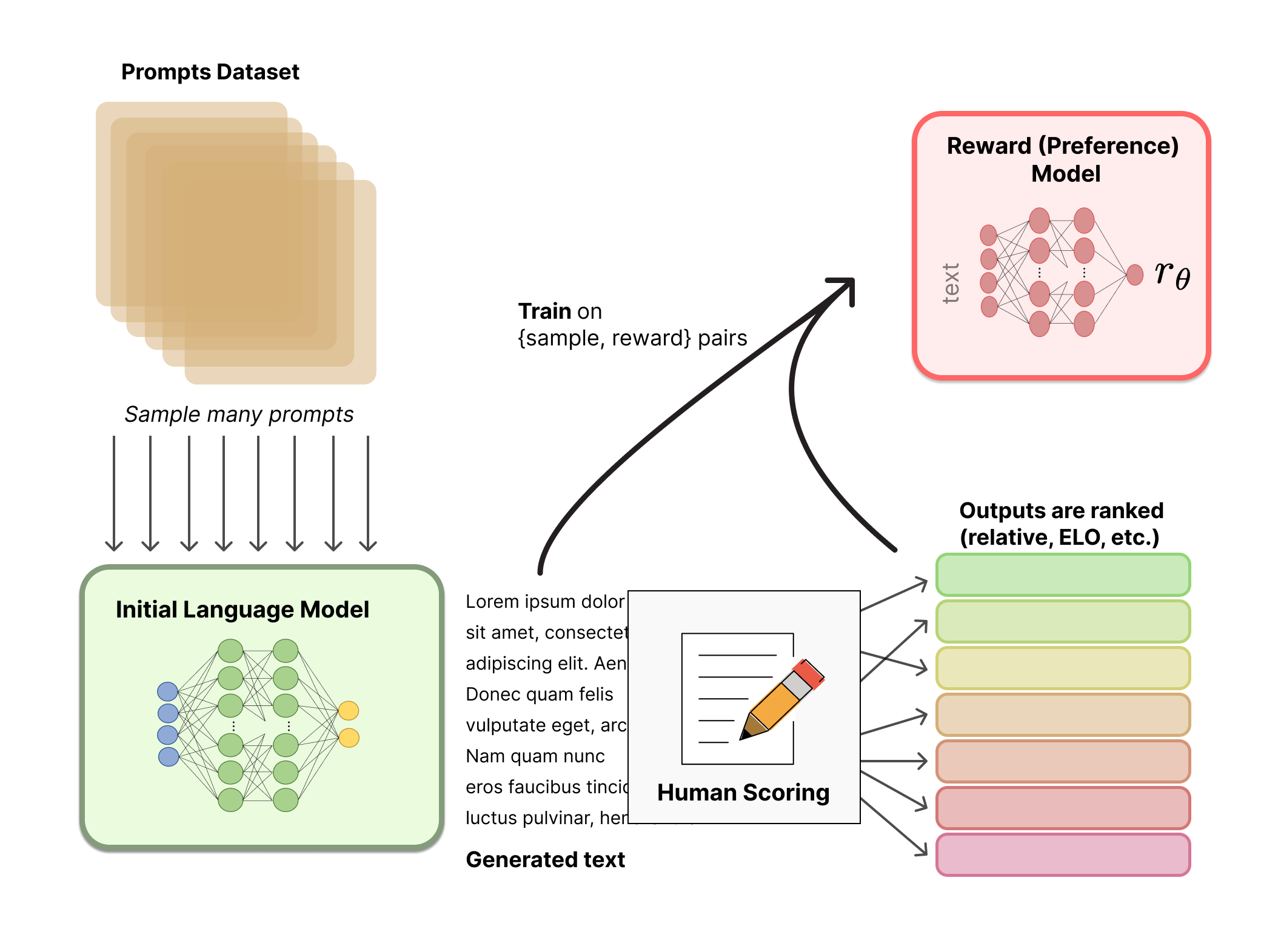
In the RLHF pipeline, the reward model sits between human judgment and model optimization. It amplifies a finite amount of human feedback into a dense signal that can guide millions of optimization steps. Everything downstream -- the quality of the final model -- depends on how well the reward model captures what humans actually value.
How It Works
 Source: Hugging Face – Illustrating RLHF
Source: Hugging Face – Illustrating RLHF
Data Collection
Human annotators are presented with a prompt and model-generated responses (typically to ). They rank the responses from best to worst. Each ranked pair becomes a training example:
Where is the prompt, is the preferred response, and is the rejected one. Collecting responses per prompt and extracting pairs from each is more efficient than collecting independent pairs.
Architecture
The reward model is typically a transformer initialized from the SFT model (or the same base model), with the language modeling head replaced by a scalar projection:
Where is the hidden state at the last token of the response, and is a learned linear projection to a scalar. Some implementations pool over all response tokens instead of using only the last token.
The Bradley-Terry Training Objective
The standard training objective assumes a Bradley-Terry model of pairwise preferences:
This says: the probability that is preferred equals the sigmoid of the reward difference. The training loss is:
Note that the absolute reward values don't matter -- only the difference between them. This means reward models are invariant to constant shifts: adding 5 to all rewards changes nothing.
Training Procedure
- Initialize from the SFT model checkpoint.
- Replace the LM head with a scalar output head.
- For each batch, compute rewards for both and .
- Compute the Bradley-Terry loss and backpropagate.
- Train for 1-2 epochs (overfitting is a major risk).
- Validate on held-out preference data by measuring accuracy at predicting held-out human preferences (typically 65-75% accuracy, given that human inter-annotator agreement is itself often only 60-75%).
Why It Matters
The reward model is the critical bottleneck of the entire RLHF pipeline. Consider the information flow:
Human preferences (rich, nuanced, but sparse) Reward model (compressed, potentially lossy) RL optimization (amplifies the reward signal across millions of steps)
Any errors in the reward model get amplified by RL optimization. If the reward model slightly prefers verbose responses, PPO will drive the model to be extremely verbose. If the reward model has a blind spot around a certain type of error, the policy will exploit it.
This creates a fundamental tension: we need the reward model to be a faithful proxy for human preferences, but it's a neural network trained on limited data with its own biases and failure modes. The quality ceiling of the entire alignment pipeline is set by the reward model.
Key Technical Details
-
Reward hacking / Goodhart's Law: When the policy optimizes aggressively against the reward model, it finds "adversarial examples" -- responses that score highly but are actually low quality. Classic examples: excessive hedging ("As an AI, I should note..."), sycophancy (agreeing with whatever the user says), or verbosity (longer responses often score higher, so the model becomes very long-winded).
-
Reward model overoptimization: Gao et al. (2022) showed a clear pattern: as you optimize more against a reward model, performance initially improves, then degrades. There's a "gold reward" (actual human preference) and a "proxy reward" (the reward model's score). The proxy keeps going up, but the gold reward peaks and declines. This is one of the most important results in alignment research.
The relationship can be approximated as:
Where the first term captures genuine improvement and the second captures overoptimization. The optimal KL divergence is at .
-
Inter-annotator disagreement: Humans often disagree about which response is better (agreement rates of 60-75% are typical). The reward model is trained on a noisy signal, and this noise floor limits achievable accuracy.
-
Reward model size: Larger reward models generally perform better but are more expensive to use during RL training (since every generated response needs to be scored). Common practice is to use a reward model of the same or smaller size as the policy.
Process Reward Models vs. Outcome Reward Models
A major development in reward modeling is the distinction between:
-
Outcome Reward Models (ORMs): Score the complete final response. This is the standard approach. The model sees the entire response and produces one scalar score.
-
Process Reward Models (PRMs): Score each individual step in the reasoning process. For a math problem, a PRM might evaluate: "Is step 1 correct? Is step 2 correct? Is step 3 correct?" This provides much denser feedback.
PRMs have shown strong results on tasks with verifiable intermediate steps (mathematics, coding, logical reasoning). The "Let's Verify Step by Step" paper (Lightman et al., 2023) demonstrated that PRMs significantly outperform ORMs on math reasoning when used for best-of-N selection.
The PRM training signal can be:
Where is the correctness label for step .
Common Misconceptions
- "The reward model captures human preferences perfectly." It's a lossy compression. Human preferences are contextual, multidimensional, and often contradictory between raters. The reward model captures a noisy average.
- "Higher reward always means better quality." Due to overoptimization, responses with the highest reward model scores are often worse than those with moderately high scores. This is why the KL penalty in RLHF is essential.
- "You only need to train the reward model once." In practice, reward models should be periodically retrained as the policy improves, because the distribution of responses the policy generates shifts over time (distributional shift).
- "Reward models just predict a 'goodness' score." They are trained to predict relative preference, not absolute quality. The absolute numbers are meaningless; only differences between scores carry information.
- "Bigger reward models are always better." There are diminishing returns, and bigger models are more expensive to run during the RL training loop, creating a practical trade-off.
Connections to Other Concepts
rlhf.md: depends entirely on the reward model as its optimization signal. The reward model is the bridge between sparse human feedback and dense RL training.dpo.md: implicitly defines a reward model within the policy itself, sidestepping explicit reward modeling but inheriting its theoretical structure.chain-of-thought-training.md: benefits from process reward models that can evaluate intermediate reasoning steps, not just final answers.constitutional-ai.md: uses AI feedback to generate preference data for reward model training, changing the data source but keeping the same reward modeling framework.goodharts-law.md: is the theoretical lens through which reward model overoptimization is understood: optimizing a proxy measure causes it to diverge from the true target.
Further Reading
- "Scaling Laws for Reward Model Overoptimization" (Gao et al., 2022) -- The definitive study of how RL overoptimization degrades true performance, establishing the empirical relationship between KL divergence and reward model exploitation.
- "Let's Verify Step by Step" (Lightman et al., 2023) -- OpenAI's work on process reward models, demonstrating that step-level supervision significantly improves mathematical reasoning.
- "A General Language Assistant as a Laboratory for Alignment" (Askell et al., 2021) -- Anthropic's early work on reward modeling, including detailed analysis of annotator disagreement and reward model accuracy.