One-Line Summary: Self-reflection enables LLM agents to evaluate, critique, and iteratively improve their own outputs across trials by converting feedback into natural language memory.
Prerequisites: ReAct pattern, chain-of-thought prompting, tool use and function calling, memory systems
What Is Self-Reflection?
Think of how a student improves on exams. After getting a test back, they do not just look at the score -- they review each mistake, understand why they got it wrong ("I confused meiosis with mitosis"), and store that insight for next time. The score alone (a scalar reward) is less useful than the verbal self-analysis ("I need to remember that meiosis produces four haploid cells"). Self-reflection in LLM agents works exactly this way: the agent attempts a task, evaluates its performance, generates a natural language critique, stores that critique in memory, and uses it to do better on the next attempt.
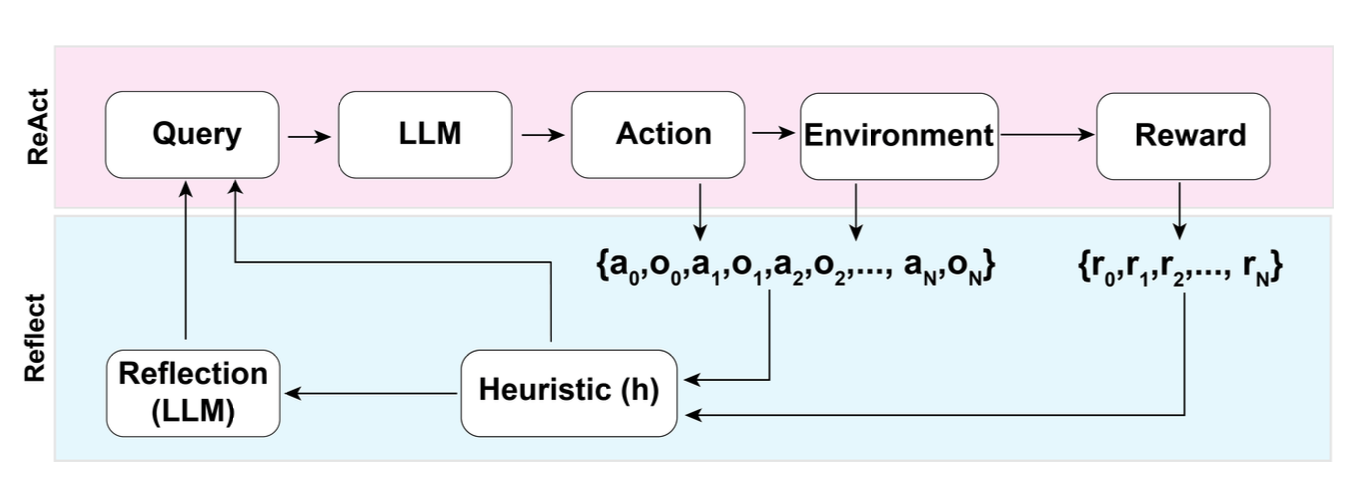 Source: Lilian Weng – LLM Powered Autonomous Agents
Source: Lilian Weng – LLM Powered Autonomous Agents
This is what Shinn et al. call "verbal reinforcement learning" in their Reflexion paper (NeurIPS 2023). Traditional reinforcement learning uses scalar rewards (0 or 1, pass or fail) to update model weights through gradient descent. Reflexion instead keeps the model weights completely frozen and converts those scalar signals into rich verbal feedback stored in an episodic memory buffer. The agent learns across trials without any gradient updates -- only through better prompting informed by its own reflections on past failures.
The broader family of self-improvement techniques includes Self-Refine (Madaan et al.), which iterates within a single trial through Generate-Critique-Refine loops, and Self-Debug (Chen et al.), which specifically targets code by executing it and debugging from error messages. All share the core principle: use feedback -- especially structured, verbal feedback -- to improve outputs iteratively.
How It Works
flowchart TD
L1["Generate"]
L2["Feedback"]
L3["Refine cycle"]
L1 --> L2
L2 --> L3
L3 -.->|"repeat"| L1The Reflexion Architecture
Reflexion has four components working in concert:
- Actor: The agent that attempts the task, typically running a ReAct-style loop with tools. This is the component that actually generates solutions.
- Evaluator: Assesses the actor's output against the task objective. Can be an external signal (unit tests passing, environment reward, ground truth match) or an LLM-based judge.
- Self-Reflection Model: Takes the full trajectory and the evaluator's assessment, then generates a verbal analysis of what went wrong, why it went wrong, and how to improve on the next attempt.
- Episodic Memory: Stores the self-reflection outputs as a growing buffer. On subsequent trials, these reflections are injected into the actor's prompt as accumulated experience.
The trial loop looks like this:
Trial 1: Actor attempts task → Evaluator scores (fail) →
Self-Reflection: "I failed because I used a greedy approach
that missed the optimal substructure. Next time, try dynamic
programming." → Stored in episodic memory
Trial 2: Actor reads past reflections from memory →
Attempts task with DP approach → Evaluator scores (fail) →
Self-Reflection: "DP was right but I had an off-by-one error
in the base case." → Added to memory
Trial 3: Actor reads accumulated reflections →
Fixes base case → Evaluator scores (pass) → DoneSelf-Refine: Within-Trial Improvement
Self-Refine (Madaan et al., 2023) operates differently from Reflexion -- it iterates within a single trial rather than across trials:
Step 1 (Generate): Model produces initial output for the task
Step 2 (Critique): Same or different model critiques the output,
identifying specific weaknesses or errors
Step 3 (Refine): Model revises the output based on the critique
Repeat Steps 2-3 for 2-3 iterations (empirically optimal)This is effective for tasks where the model can meaningfully evaluate its own output, such as code generation, summarization, constrained writing, and math problem solving. The key finding: beyond 3 iterations, improvements plateau and can sometimes reverse as the model over-corrects or fixates on minor issues.
Self-Debug: Code-Specific Reflection
Self-Debug (Chen et al., 2023) applies self-reflection specifically to code generation:
- Generate code from a natural language specification
- Execute the code against test cases
- Feed the error messages and failing test outputs back to the model
- Ask the model to explain the bug and generate a fix
- Repeat until tests pass or iteration limit is reached
The execution feedback provides a reliable external signal -- code either works or it does not -- making this one of the most effective self-reflection domains.
Benchmark Results
The results from Reflexion are striking:
- HumanEval (code generation): 91.0% pass@1, which was state-of-the-art at the time of publication, up from approximately 80% with base GPT-4 on a single attempt.
- ALFWorld (interactive tasks): 97% success rate, a +22 percentage point improvement over base ReAct (75%), showing that learning from past failures dramatically improves multi-step task completion.
- HotpotQA (multi-hop QA): Significant improvements through iterative retrieval refinement guided by reflection on which search queries failed and why.
Self-Debug showed similar gains: models that could execute code, read error messages, and revise achieved substantially higher pass rates than single-attempt generation across multiple programming benchmarks.
When Self-Reflection Helps vs Hurts
Self-reflection is most effective on verifiable tasks where the evaluator can provide a clear, reliable signal: code generation (test suites pass or fail), math (answer matches or does not), and fact verification (evidence supports or contradicts). It struggles on subjective tasks like creative writing, open-ended brainstorming, or style preferences, where there is no objective standard for the evaluator to check against. It also cannot help when the model fundamentally lacks the capability to solve the problem -- reflecting on why you failed at calculus does not help if you never learned calculus.
Why It Matters
- Learning without training: Reflexion achieves trial-over-trial improvement without any weight updates, making it applicable to frozen API-based models where you cannot fine-tune.
- State-of-the-art code generation: The 91.0% HumanEval score demonstrated that iterative self-improvement could match or exceed specialized fine-tuning approaches at a fraction of the development cost.
- Composable with existing agents: Self-reflection can be layered on top of any ReAct-style agent as an outer loop, improving performance with minimal architectural changes to the underlying system.
- Interpretable improvement: The natural language reflections provide a human-readable record of what the agent learned and why, enabling debugging, trust-building, and system improvement.
- Cost-effective scaling: Adding 2-3 reflection iterations costs 2-3x more tokens but can yield 10-20+ percentage point accuracy gains, often a better tradeoff than scaling to a larger and more expensive model.
Key Technical Details
- Reflexion's episodic memory typically stores the 3-5 most recent reflections to avoid context window overflow; older reflections are discarded or summarized
- Self-Refine improvements plateau after 2-3 iterations; a 4th iteration yields less than 1% additional gain on average across benchmarks
- The evaluator signal quality is critical -- unit tests and code execution provide reliable binary signals; LLM-based evaluation introduces noise and potential bias
- Huang et al. (2023) showed that self-correction WITHOUT external feedback (no tools, no tests, no ground truth) actually degrades performance by 1-5% on average
- Self-reflection works best on verifiable tasks: code (test suites), math (answer checking), fact verification (search). It struggles on subjective tasks like creative writing where "better" is ambiguous
- Memory injection format matters: structured reflections ("I failed because X; next time I should Y") outperform raw trajectory replays by 8-12% on task success rate
- Combining Reflexion with self-consistency (multiple attempts per trial, then vote) further improves results but multiplies cost
- The reflection model can be smaller and cheaper than the actor model, since critique is generally easier than generation
Common Misconceptions
- "LLMs can reliably self-correct without external feedback." This is the most dangerous misconception. Huang et al. (2023) demonstrated that when models are simply asked "are you sure?" or "check your answer" without access to tools or ground truth, performance actually decreases. The model second-guesses correct answers as often as it fixes incorrect ones. Self-reflection requires an external grounding signal to be effective.
- "More reflection iterations always help." Empirically, 2-3 iterations is the sweet spot for both Reflexion and Self-Refine. Beyond that, models can enter loops of over-correction, undoing previous improvements or fixating on irrelevant details while ignoring the core problem.
- "Self-reflection can compensate for fundamental capability gaps." If a model lacks the underlying knowledge or reasoning ability to solve a problem, reflecting on failures will not help. You cannot reflect your way to solving differential equations if the model does not understand calculus. Reflection amplifies existing capability; it does not create new capability from scratch.
Connections to Other Concepts
react-pattern.md: Reflexion wraps a ReAct agent in an outer evaluation-reflection loop, adding cross-trial learning to within-trial reasoning and acting.memory-systems.md: Episodic memory is the mechanism that carries reflections across trials, making accumulated experience accessible to future attempts.chain-of-thought-prompting.md: Self-reflection extends CoT from single-pass reasoning to iterative, feedback-driven reasoning across multiple attempts at the same problem.multi-agent-systems.md: Critic agents in multi-agent architectures perform a role analogous to the evaluator and self-reflection components in Reflexion, providing external feedback.
Further Reading
- Shinn et al., "Reflexion: Language Agents with Verbal Reinforcement Learning," arXiv:2303.11366, NeurIPS 2023
- Madaan et al., "Self-Refine: Iterative Refinement with Self-Feedback," arXiv:2303.17651, NeurIPS 2023
- Chen et al., "Teaching Large Language Models to Self-Debug," arXiv:2304.05128, 2023
- Huang et al., "Large Language Models Cannot Self-Correct Reasoning Yet," arXiv:2310.01798, 2023