One-Line Summary: Special tokens are reserved vocabulary entries that carry control signals rather than linguistic content, directing model behavior for tasks like indicating sequence boundaries, separating segments, and managing chat turn-taking.
Prerequisites: Understanding of tokenization (how text becomes tokens), token embeddings (how tokens become vectors), basic familiarity with how language models are trained and used for inference, and awareness of instruction tuning and chat-based LLM interfaces.
What Is a Special Token?
Imagine you're reading a script for a play. The words the actors speak are the content, but the script also contains stage directions: "ENTER Hamlet," "Exit, pursued by a bear," "End of Act III." These directions aren't part of the dialogue -- they're meta-information that controls the performance.
 Source: Jay Alammar – A Visual Guide to Using BERT
Source: Jay Alammar – A Visual Guide to Using BERT
Special tokens serve the same role for language models. They are tokens that don't represent text content but instead carry instructions to the model about structure and behavior. When the model sees <|endoftext|>, it doesn't interpret that as English words -- it understands that the current text has ended. When it sees <|im_start|>assistant, it knows it should begin generating a response in the assistant's voice.
These tokens are manually added to the vocabulary (not learned through BPE merges) and are given dedicated embedding vectors that are trained to encode their control functions. They are invisible to the end user in most interfaces but are essential to the functioning of every modern LLM.
How It Works
 Source: Jay Alammar – The Illustrated GPT-2
Source: Jay Alammar – The Illustrated GPT-2
The Core Special Tokens
BOS (Beginning of Sequence): Marks the start of input. Represented as <s> in LLaMA, <|startoftext|> in GPT-2, or similar variants. It provides a consistent positional anchor at position 0 and gives all subsequent tokens something to attend to. Some architectures omit a dedicated BOS token because position 0 itself serves as an implicit signal.
EOS (End of Sequence): Marks the end of a generated sequence. Represented as </s>, <|endoftext|>, <|end|>, etc. This is arguably the most important special token in autoregressive models. During generation, the model outputs a probability distribution over the vocabulary at each step. When the EOS token receives the highest probability (or is sampled), generation stops. Without a well-trained EOS token, the model would generate text forever.
PAD (Padding Token): Used to pad shorter sequences in a batch to equal length. Represented as <pad>, [PAD], or sometimes the EOS token doubles as PAD. Padding tokens are masked in the attention computation (attention mask = 0) so they don't influence the model's output. They exist purely for computational convenience.
where is the mask matrix with at padded positions, ensuring .
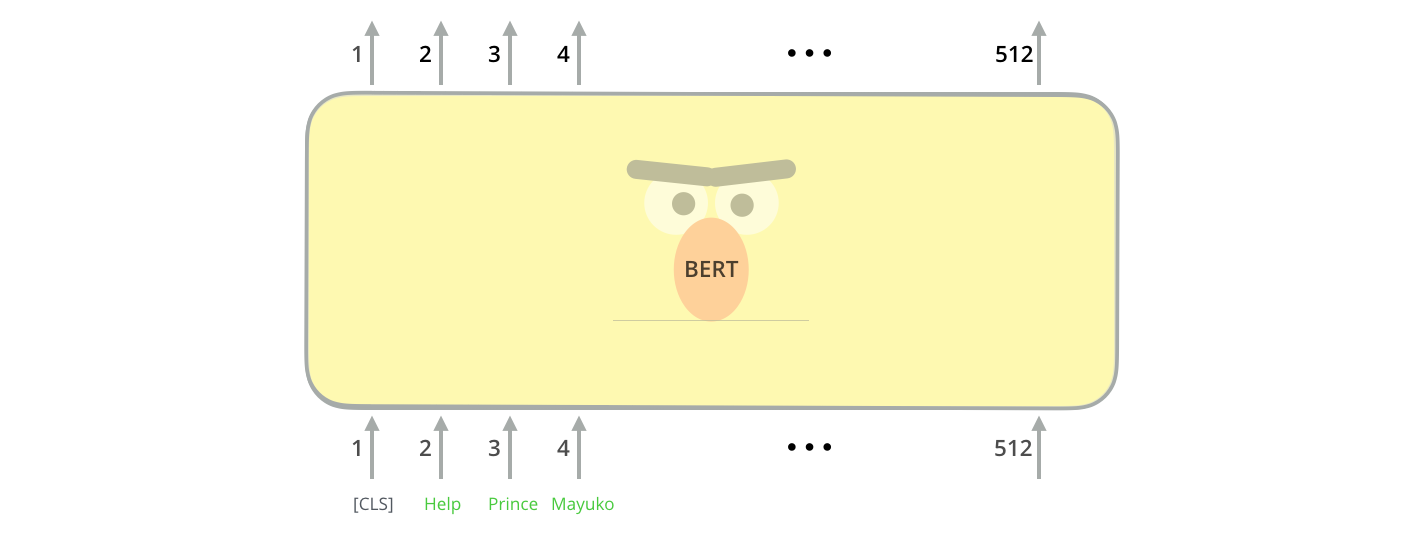
SEP (Separator Token): Used by encoder models like BERT to separate two input segments (e.g., a question and a passage). Represented as [SEP]. In BERT's input format: [CLS] sentence A [SEP] sentence B [SEP].
CLS (Classification Token): A BERT-specific token prepended to every input. The model's representation of this token (after all transformer layers) is used as the aggregate representation of the entire input for classification tasks. It acts as a "summary slot."
Chat Templates and Turn-Taking Tokens
Modern chat-based LLMs use elaborate special token schemes to structure multi-turn conversations. These tokens define who is speaking, where turns begin and end, and what role the model should adopt.
ChatML (OpenAI format):
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
What is the capital of France?<|im_end|>
<|im_start|>assistant
The capital of France is Paris.<|im_end|>LLaMA 2 Chat format:
<s>[INST] <<SYS>>
You are a helpful assistant.
<</SYS>>
What is the capital of France? [/INST] The capital of France is Paris. </s>LLaMA 3 Chat format:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>
What is the capital of France?<|eot_id|><|start_header_id|>assistant<|end_header_id|>Each format uses different special tokens, and using the wrong format for a model will produce degraded output. The model was instruction-tuned with a specific template, and it expects that exact structure at inference time.
How Special Tokens Are Used in Instruction Tuning
During instruction fine-tuning (SFT), the training data is formatted with special tokens marking the structure. Crucially, the loss is typically computed only on the assistant's response tokens, not on the system/user tokens or the special tokens themselves. This is achieved through a loss mask:
Tokens: [BOS] [INST] What is 2+2? [/INST] 4 [EOS]
Loss: 0 0 0 0 0 0 0 1 1The special tokens are provided as input context but are not prediction targets. This teaches the model to generate content in response to the instruction format without trying to generate the format itself.
Implementation Details
Special tokens are added to the tokenizer with specific properties:
See also the Hugging Face documentation on chat templates and special tokens: Hugging Face – Chat Templates -- shows how different model families structure conversations with role-specific special tokens.
- They are never split by the tokenizer. The string
<|endoftext|>is always tokenized as a single token, never as<,|,end,of,text,|,>. - They have reserved IDs. These are typically at the beginning or end of the vocabulary. LLaMA's
<s>is token ID 1,</s>is token ID 2. - Their embeddings are trained. Like regular tokens, special tokens have learned embedding vectors. The BOS embedding learns to represent "this is the start of a sequence," and the model's layers learn to use this signal.
- They may be added post-tokenizer-training. The base BPE vocabulary is built first, then special tokens are appended. This means the vocabulary size = BPE vocabulary + number of special tokens.
Why It Matters
Special tokens are the invisible control plane of LLMs. Their correct handling is essential for:
- Stopping generation: Without a properly trained EOS token, models would generate indefinitely, producing increasingly incoherent text. EOS is the model's learned sense of "I'm done."
- Multi-turn conversation: Chat templates with role tokens (user, assistant, system) enable the model to maintain coherent conversations with clear speaker boundaries.
- Safety and alignment: System prompts, which contain safety instructions, are delineated by special tokens. The model's instruction-following behavior depends on recognizing these tokens correctly.
- Batched inference: Padding tokens and attention masks enable efficient batched processing of variable-length inputs on GPUs.
- Tool use: Modern models use special tokens to indicate tool calls (
<|tool_call|>), tool results (<|tool_result|>), and structured output boundaries.
Key Technical Details
- EOS token behavior can be overridden. Many inference frameworks allow specifying custom stop tokens or stop strings. A "stop sequence" is not necessarily the EOS token -- it can be any string that triggers the framework to halt generation.
- The attention mask must correctly handle special tokens. BOS tokens should be attended to (they carry useful signal). PAD tokens should be masked out. Getting this wrong is a common source of bugs.
- In autoregressive models (GPT-style), there is no CLS token. The equivalent of "sequence representation" is typically the last token's hidden state, or the BOS token's representation after processing the full sequence.
- Different fine-tuning stages may introduce new special tokens. A base model might have just BOS/EOS, while the chat-tuned version adds role tokens, tool tokens, and format tokens.
- Token IDs for special tokens vary across model families. Never hard-code special token IDs -- always use the tokenizer's built-in properties (e.g.,
tokenizer.eos_token_id).
Common Misconceptions
- "Special tokens are just markup and don't really matter." They are critical. Mismatched or missing special tokens are among the most common causes of degraded model performance. Using a chat model without its expected chat template can make it appear much less capable than it is.
- "EOS means the model thinks the text should end." EOS means the model predicts that generation should stop at this point given its training. It's a learned behavior, not a semantic judgment. Models can be trained to generate EOS prematurely (truncated responses) or too late (rambling).
- "All models use the same special tokens." Every model family has its own set. Mixing them up (e.g., using BERT's
[CLS]with LLaMA) produces nonsense because the model has no training signal for tokens from another vocabulary. - "The model doesn't see special tokens." It absolutely does. Special tokens are embedded and processed through all transformer layers just like regular tokens. The model learns specific attention patterns around them.
- "PAD tokens on the left vs. right doesn't matter." For autoregressive models, left-padding (adding PAD tokens at the start) is necessary so that all sequences in a batch end at the same position, which is where generation continues. Right-padding is standard for encoder models. Getting this wrong causes subtle but significant bugs.
Connections to Other Concepts
tokenization.md: Special tokens are part of the vocabulary but are not created through the BPE/subword process. They are manually added to the tokenizer.token-embeddings.md: Special tokens have their own learned embedding vectors in the embedding matrix.positional-encoding.md: The BOS token typically occupies position 0, creating a fixed positional reference point.context-window.md: Special tokens consume positions in the context window. A complex chat template with many special tokens reduces the space available for actual content.vocabulary-design.md: Special tokens are a fixed overhead in the vocabulary. Models with many special tokens (e.g., for multilingual or multi-task use) dedicate vocabulary slots to these control signals.
Further Reading
- Devlin, J., et al. (2019). "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding." NAACL 2019. -- Introduced CLS and SEP tokens and defined the paradigm for special token usage in encoder models.
- Touvron, H., et al. (2023). "LLaMA 2: Open Foundation and Fine-Tuned Chat Models." arXiv:2307.09288. -- Documents the chat template and special token design for one of the most influential open model families.
- OpenAI. "Chat Markup Language (ChatML)." -- The specification for OpenAI's chat formatting, defining how special tokens structure multi-turn conversations with system, user, and assistant roles.