One-Line Summary: Function calling enables LLMs to interact with the outside world by generating structured requests (typically JSON) that an application layer executes and feeds back, transforming language models from text generators into general-purpose reasoning engines that can take real actions.
Prerequisites: Understanding of how LLMs generate text token by token, familiarity with JSON and APIs, basic knowledge of how software applications are structured, and awareness of the concept of structured output.
What Is Function Calling?
Imagine giving someone a phone and a directory of services. They cannot leave the room, but they can call any service, ask for information, and use the answers to help you. The person is the LLM, the phone is function calling, and the directory is the set of tool definitions you provide.
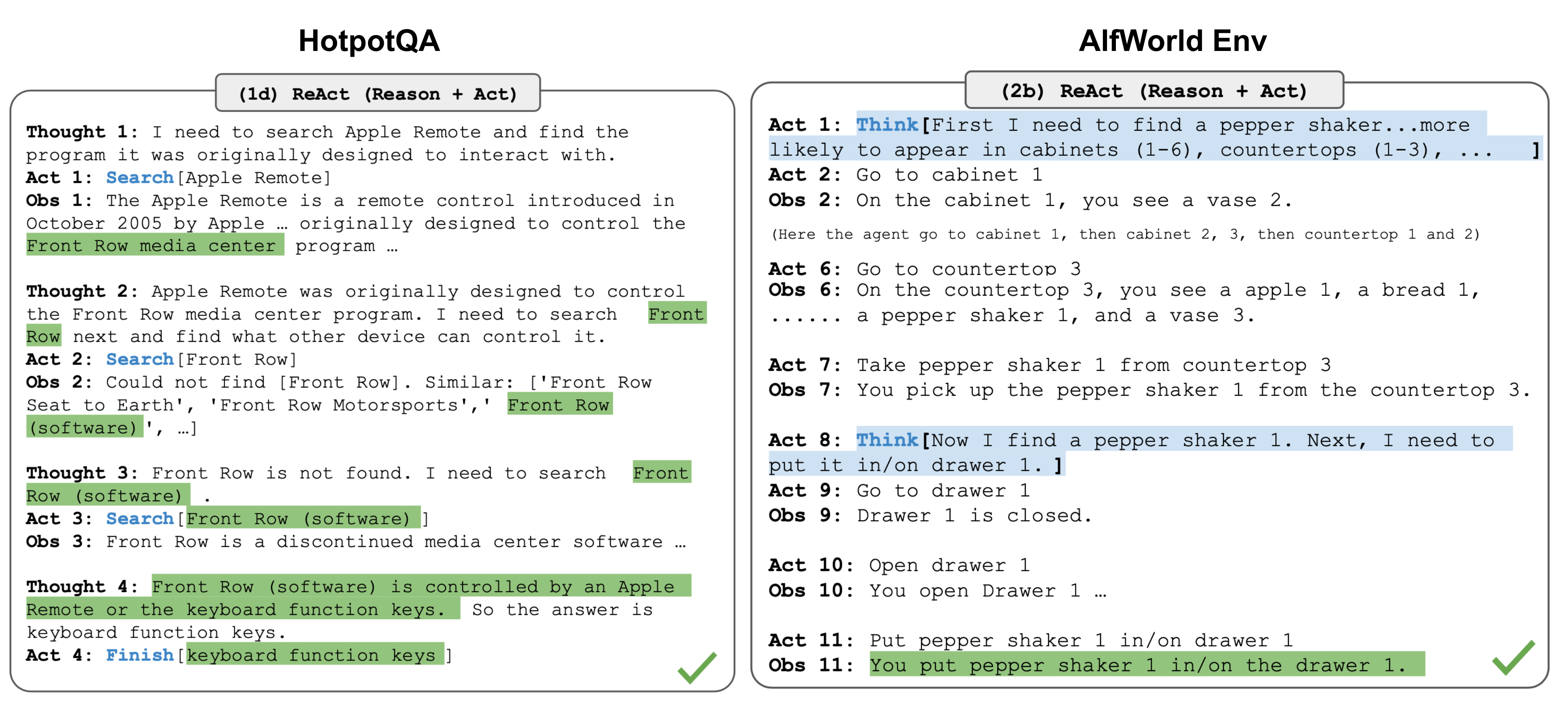 Source: Lilian Weng – LLM Powered Autonomous Agents
Source: Lilian Weng – LLM Powered Autonomous Agents
LLMs, by themselves, can only produce text. They cannot check today's weather, query a database, send an email, or perform calculations with guaranteed precision. Function calling bridges this gap by giving the model a formal way to say "I need to call this specific function with these specific arguments" and a mechanism for the application to execute that call and return the result.
This capability was popularized by OpenAI's June 2023 function calling API, but the pattern has since become a standard feature across major model providers including Anthropic (tool use), Google (function calling in Gemini), and open-source models fine-tuned for tool use.
How It Works
flowchart LR
S1["JSON schema definition"]
S2["LLM generating structured calls"]
S3["application executing them"]
S1 --> S2
S2 --> S3The Execution Loop
Function calling follows a well-defined cycle:
Step 1: Definition. The developer provides the model with a list of available tools, each described by a name, a description of what it does, and a JSON schema defining its parameters. For example:
{
"name": "get_weather",
"description": "Get current weather for a given city",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "City name"},
"units": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}Step 2: Decision. When the user asks a question like "What's the weather in Tokyo?", the model analyzes the query, determines it needs external data, and instead of generating a text response, it generates a structured function call:
{"name": "get_weather", "arguments": {"city": "Tokyo", "units": "celsius"}}Step 3: Execution. The application layer (your code) intercepts this function call, executes the actual API request, and obtains the result. Critically, the LLM never executes anything itself -- it only expresses intent in a structured format.
Step 4: Feedback. The function result is sent back to the model as a new message in the conversation. The model then uses this result to generate its final natural language response: "It's currently 22 degrees Celsius in Tokyo with partly cloudy skies."
Step 5: Iteration. The model may decide it needs additional function calls. This creates a loop: generate call, execute, feed back result, generate next call or final response. Complex tasks might involve 5-10 function calls in sequence.
Parallel Tool Calling
Modern implementations support parallel function calling, where the model generates multiple function calls in a single response. If the user asks "Compare the weather in Tokyo and London," the model can emit both get_weather("Tokyo") and get_weather("London") simultaneously, and the application can execute them in parallel. This reduces latency significantly for independent operations.
Model Context Protocol (MCP)
MCP, introduced by Anthropic in late 2024, is an open protocol that standardizes how LLMs connect to external tools and data sources. Think of it as a universal adapter: instead of each application implementing its own tool integration layer, MCP defines a standard client-server protocol where tool providers (MCP servers) expose capabilities and LLM applications (MCP clients) consume them.
MCP servers can expose three types of capabilities: tools (functions the model can call), resources (data the model can read), and prompts (templates for common interactions). The protocol handles discovery, invocation, and result passing in a standardized way, analogous to how USB standardized peripheral connections.
This matters because it enables a ecosystem where tool integrations are built once and used everywhere, rather than being reimplemented for every LLM application.
Designing Tool Schemas
Good tool design is crucial for reliable function calling:
Clear descriptions: The model decides which tool to use based primarily on the description. "Searches the company knowledge base for relevant documents" is far more useful than "search_kb."
Specific parameter types: Use enums for constrained choices, provide defaults where sensible, and mark required vs. optional parameters explicitly.
Granularity: Prefer many small, focused tools over few large, multi-purpose ones. A search_documents tool and a get_document_by_id tool are better than a single document_manager tool with a mode parameter.
Error handling in descriptions: Tell the model what to do when a tool returns an error or empty result. "If no results are found, try broadening the search terms" helps the model recover gracefully.
Common Tool Patterns
- Search tools: Query databases, knowledge bases, or the web. The most common pattern in RAG applications.
- Calculator/code execution: Offload precise computation to tools rather than relying on the model's arithmetic.
- Database query: Generate and execute SQL or API queries against structured data.
- API integration: Call external services (email, calendar, CRM, payment systems).
- File operations: Read, write, or manipulate files in a controlled environment.
Why It Matters
Function calling transforms LLMs from passive text generators into active agents that can interact with the real world. Without it, an LLM can only tell you about things. With it, an LLM can do things: book a flight, update a database, send a notification, execute code, or orchestrate a complex workflow.
This is the foundation of the agent paradigm. Every AI agent -- from coding assistants to customer service bots to autonomous research systems -- depends on reliable function calling to interact with its environment.
Key Technical Details
- The model does not execute functions. This is the most important architectural point. The model generates a JSON request; your application code decides whether and how to execute it. This provides a crucial safety layer.
- Tool choice control: APIs typically offer modes like
auto(model decides),required(model must call a tool),none(model cannot call tools), or forcing a specific tool. Userequiredwhen you know a tool call is needed. - Token cost: Tool definitions consume input tokens. Twenty tools with detailed schemas can use 2000-3000 tokens before any conversation content. Be judicious with how many tools you expose.
- Reliability scales with tool count inversely: Models are highly reliable at choosing among 3-5 tools. With 20+, accuracy drops. Consider routing or sub-agent architectures for large tool sets.
- Structured output guarantees: Some providers (OpenAI's strict mode, Anthropic's tool use) guarantee that function call arguments conform to the provided JSON schema, eliminating parse errors.
Common Misconceptions
"The LLM actually runs the code." The model only generates text that describes what function to call and with what arguments. Execution happens entirely in application code that the developer controls.
"Function calling is just prompt engineering with JSON." While early approaches did use prompt-based tool use, modern function calling is trained into the model during fine-tuning, with special tokens and training data for tool interactions. It is more reliable and structured than prompt-based approaches.
"Any model can do function calling." Models need specific training for reliable function calling. Base models or models not fine-tuned for tool use will produce unreliable structured output. Look for explicit function calling support in model documentation.
"More tools are always better." Each additional tool increases the chance of misrouting. Curate your tool set to include only what is necessary for the current task context.
Connections to Other Concepts
ai-agents.md: are built on top of function calling -- the agent loop is essentially repeated function calling with reasoning between calls.structured-output.md: is the underlying capability that makes function calling work -- the model must produce valid JSON conforming to a schema.rag.md: often uses function calling as its trigger mechanism: the model calls asearchtool to retrieve documents.prompt-engineering.md: applies to tool descriptions and system prompts that guide tool selection behavior.safety-by-design.md: become critical when tools can take real-world actions. The application layer must implement authorization, rate limiting, and human-in-the-loop approval for sensitive operations.
Further Reading
- Schick, T. et al. (2023). "Toolformer: Language Models Can Teach Themselves to Use Tools." NeurIPS 2023. The foundational paper on training LLMs to use tools autonomously.
- Patil, S. et al. (2023). "Gorilla: Large Language Model Connected with Massive APIs." Demonstrates LLMs trained on API documentation for accurate function calling across thousands of APIs.
- Anthropic (2024). "Model Context Protocol (MCP) Specification." The open standard for LLM-tool integration.