One-Line Summary: The Transformer is a neural network architecture built entirely on attention mechanisms that processes all input tokens in parallel, replacing sequential recurrence and becoming the universal foundation of modern large language models.
Prerequisites: Basic understanding of neural networks (layers, weights, forward pass), familiarity with what word embeddings are, and a general sense of why sequence modeling matters for language.
What Is the Transformer Architecture?
Imagine you are reading a book. A recurrent neural network (RNN) reads one word at a time, left to right, carrying a summary of everything it has read in a single, fixed-size memory vector. By the time it reaches word 500, its memory of word 1 is faded and compressed. The Transformer, by contrast, lays every word of the book out on a table simultaneously and lets each word look directly at every other word to decide what matters.
 Source: The Annotated Transformer -- Harvard NLP
Source: The Annotated Transformer -- Harvard NLP
Introduced in the landmark 2017 paper "Attention Is All You Need" by Vaswani et al. at Google, the Transformer discarded recurrence and convolutions entirely. Instead, it relies on a mechanism called self-attention to model relationships between all positions in a sequence at once. This single architectural bet turned out to be one of the most consequential decisions in the history of artificial intelligence.
How It Works
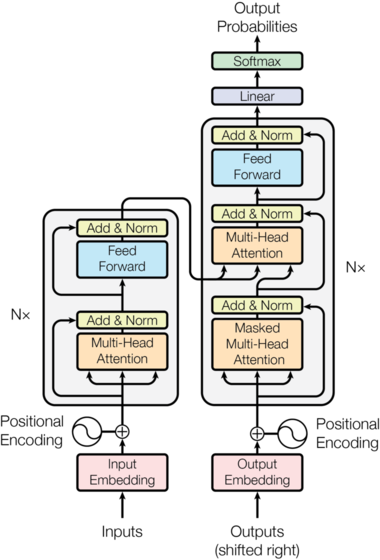
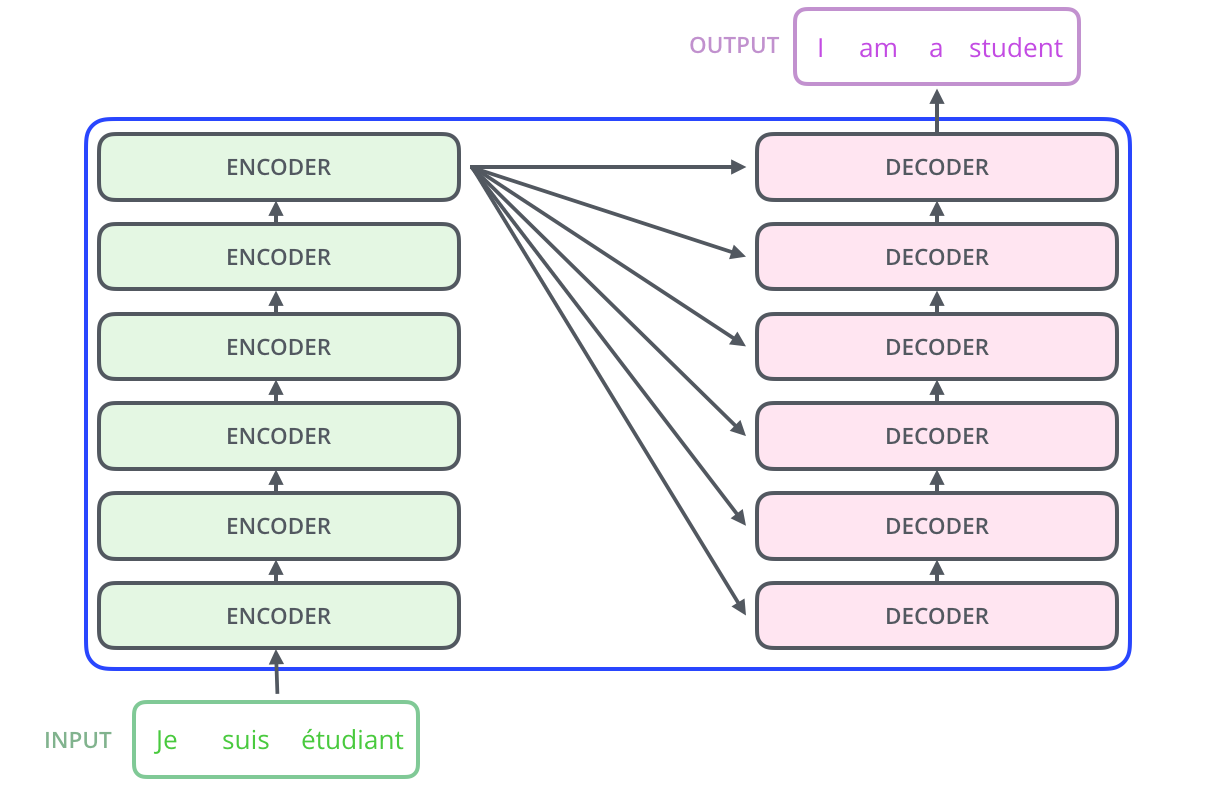
The original Transformer follows an encoder-decoder design. Here is the conceptual data flow:
 Source: The Illustrated Transformer -- Jay Alammar
Source: The Illustrated Transformer -- Jay Alammar
1. Input Embedding and Positional Encoding
Raw tokens (words or subwords) are converted into dense vectors via an embedding layer. Because the Transformer has no inherent sense of order (unlike RNNs), positional encodings are added to the embeddings so the model knows that "the" in position 1 is different from "the" in position 20. The original paper used sinusoidal functions for this:
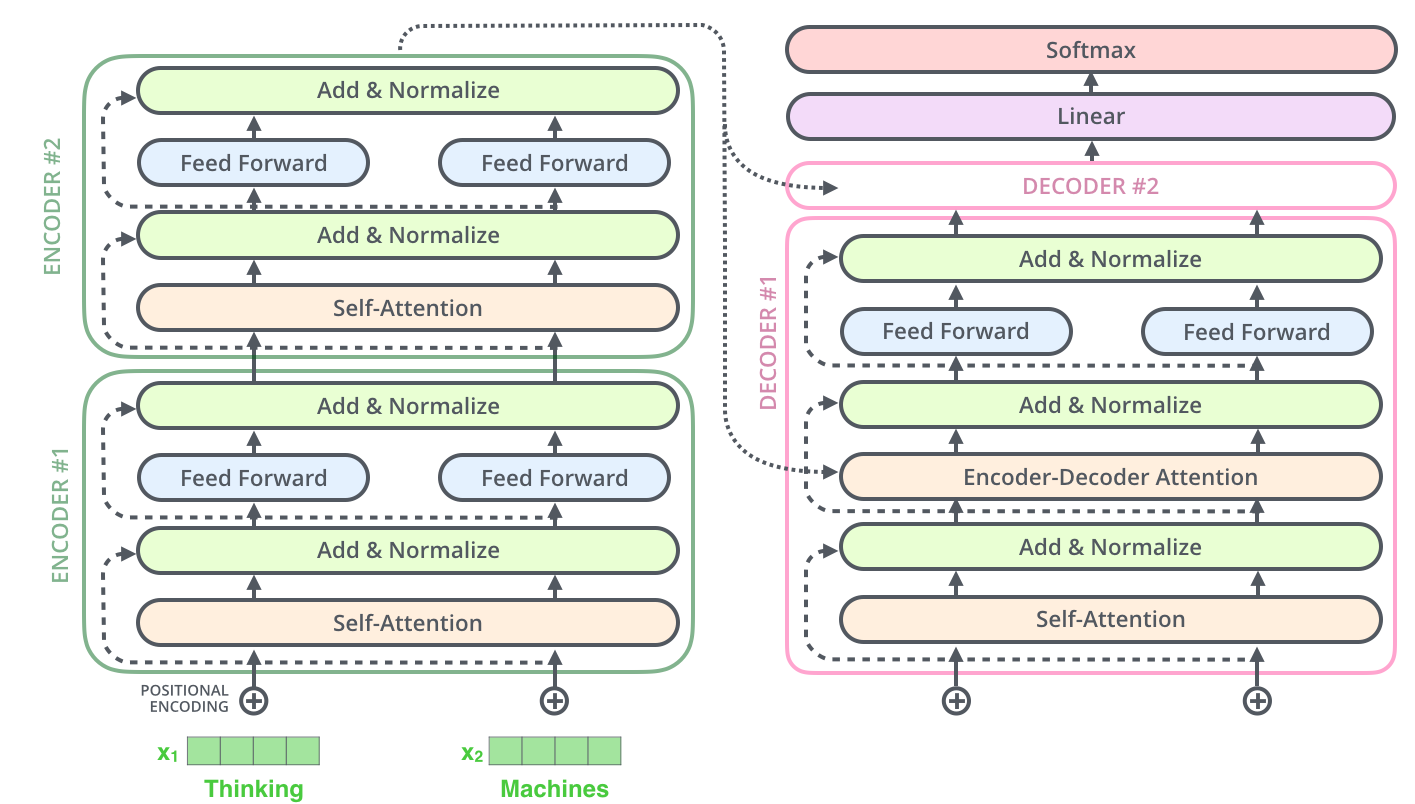
2. The Encoder Stack
The encoder is a stack of identical layers (the original paper used ). Each layer contains two sub-layers:
- Multi-Head Self-Attention: Every token attends to every other token in the input, producing context-aware representations.
- Position-wise Feed-Forward Network (FFN): A two-layer fully connected network applied independently to each position.
Each sub-layer is wrapped with a residual connection and followed by layer normalization: .
3. The Decoder Stack
The decoder is also a stack of identical layers, but each layer has three sub-layers:
- Masked Multi-Head Self-Attention: Same as the encoder's self-attention, but with a causal mask preventing positions from attending to future tokens.
- Cross-Attention: The decoder attends to the encoder's output, allowing it to "read" the source representation.
- Position-wise FFN: Same structure as in the encoder.
4. Output Layer
The decoder's output passes through a linear layer and a softmax to produce probabilities over the vocabulary for the next token.
 Source: Jay Alammar – The Illustrated Transformer
Source: Jay Alammar – The Illustrated Transformer
The Full Forward Pass (Summarized)
Input tokens -> Embedding + Positional Encoding -> Encoder Layers (x N) -> Encoder Output
Target tokens -> Embedding + Positional Encoding -> Decoder Layers (x N, with cross-attention to encoder output) -> Linear + Softmax -> Predicted token probabilitiesWhy It Matters
The Transformer's impact cannot be overstated. Before 2017, the dominant sequence models were RNNs (especially LSTMs and GRUs). These suffered from three critical problems:
-
Sequential bottleneck: RNNs process tokens one at a time. You cannot compute the representation for word 10 until you have processed words 1 through 9. This made training painfully slow and poorly suited to modern GPUs, which excel at parallel computation.
-
Vanishing gradients over long sequences: Despite gating mechanisms in LSTMs, information from early tokens still degraded over hundreds of steps.
-
Fixed-size hidden state: All context had to be compressed into a single vector, creating an information bottleneck.
The Transformer solved all three. Self-attention connects every token to every other token in sequential steps (though computation), enabling massive parallelism. Residual connections and layer normalization allow gradients to flow through dozens or hundreds of layers. And the attention mechanism creates a flexible, dynamic routing of information rather than a fixed bottleneck.
This parallelism is why the Transformer could scale. The entire era of large language models, from GPT-2 (2019) to GPT-4 (2023) to modern open-weight models, is built on scaling the Transformer to billions or trillions of parameters across thousands of GPUs. None of this would have been feasible with RNNs.
Post-2023 Architectural Innovations
The core Transformer design has remained remarkably stable since 2017, but modern LLMs incorporate significant refinements that improve training stability, efficiency, and capability:
Pre-Norm vs. Post-Norm: The original Transformer applied layer normalization after the residual addition (Post-Norm): . Modern models universally use Pre-Norm, applying normalization before the sub-layer: . Pre-Norm enables stable training of much deeper networks (100+ layers) without careful initialization or warmup tricks.
RMSNorm over LayerNorm: Most modern LLMs (LLaMA, Gemma, Qwen) replace LayerNorm with RMSNorm (Root Mean Square Normalization), which drops the mean-centering step. RMSNorm is computationally cheaper (one fewer reduction operation) and empirically performs equally well, saving 5-10% wall-clock time at scale.
SwiGLU Feed-Forward Networks: The original FFN used ReLU activation between two linear layers. Modern architectures (LLaMA, PaLM, Gemma) use SwiGLU, a gated activation that combines Swish (silu) with a gating mechanism:
FFN_SwiGLU(x) = (Swish(xW_1) ⊙ xW_3) W_2This adds a third weight matrix but improves quality enough that the total parameter count is typically reduced to compensate (e.g., using instead of ), resulting in better performance at the same compute budget.
Rotary Position Embeddings (RoPE): Sinusoidal and learned positional encodings have been replaced by RoPE in virtually all modern decoder-only models. RoPE encodes relative position by rotating query and key vectors, enabling natural length generalization and compatibility with context window extension techniques like NTK-aware scaling and YaRN.
Grouped Query Attention (GQA): Instead of having equal numbers of query, key, and value heads (standard Multi-Head Attention) or a single KV head (Multi-Query Attention), GQA uses an intermediate number of KV groups. LLaMA 3 uses 8 KV heads shared across 64 query heads, reducing KV cache memory by 8x while maintaining nearly full-attention quality.
Tied and Untied Embeddings: The original Transformer tied input and output embedding matrices. Modern practice varies: some models (Gemma) tie them to save parameters; others (LLaMA) untie them, using separate matrices for input tokens and output prediction, which can improve quality when vocabulary is large.
Deeper and Wider Trade-offs: Modern scaling research reveals that for a fixed parameter budget, width (model dimension) and depth (layer count) should be scaled together following specific ratios. DeepSeek-V3 uses 61 layers with ; LLaMA 3 405B uses 126 layers with . The trend favors deeper models with grouped query attention, as depth captures more compositional reasoning.
Key Technical Details
- Original dimensions: , , 8 attention heads, 6 layers for both encoder and decoder.
- Parameter count of the original Transformer: approximately 65 million (tiny by modern standards).
- Modern LLMs (GPT-3, LLaMA, etc.) use only the decoder portion, with layer counts of 32 to 120+ and values of 4096 to 16384+.
- Computational complexity of self-attention is where is sequence length and is dimension. This quadratic scaling in sequence length is the architecture's primary limitation.
- The original model was trained on WMT English-to-German and English-to-French translation tasks.
- Training used the Adam optimizer with a warmup-then-decay learning rate schedule, which became standard practice.
- Modern decoder-only recipe (as of 2025): Pre-Norm with RMSNorm, SwiGLU FFN, RoPE, GQA, untied embeddings. This combination (pioneered by LLaMA and adopted by Qwen, Gemma, Mistral, and others) has become the de facto standard for open-weight models.
- Context lengths have expanded from 512 tokens (original) to 128K-1M+ tokens in modern models, enabled by RoPE scaling, FlashAttention, and ring attention.
Common Misconceptions
- "The Transformer is just attention." While attention is the signature innovation, the architecture equally depends on feed-forward layers, residual connections, layer normalization, and positional encodings. Remove any one of these, and the model fails.
- "Transformers understand word order through attention." Attention itself is permutation-invariant. Without positional encodings, a Transformer cannot distinguish "dog bites man" from "man bites dog." The positional encoding is doing critical work.
- "Modern LLMs use the full encoder-decoder Transformer." Most modern LLMs (GPT, LLaMA, Claude, Gemini) are decoder-only. The encoder-decoder variant is used in models like T5 and BART but is less common for pure text generation.
- "Transformers replaced RNNs because they are more accurate." The initial advantage was not just accuracy but training speed. Parallelism allowed researchers to train on far more data, which then led to better accuracy. The scaling is the key insight, not just the architecture in isolation.
- "The Transformer architecture hasn't changed since 2017." While the core self-attention mechanism remains, modern models use substantially different components: RMSNorm instead of LayerNorm, SwiGLU instead of ReLU FFNs, RoPE instead of sinusoidal positions, GQA instead of standard multi-head attention, and Pre-Norm instead of Post-Norm. A 2025 decoder-only model shares the same conceptual framework but differs significantly in implementation details.
Connections to Other Concepts
-
self-attention.md: The core mechanism inside each Transformer layer (seeself-attention.md). -
multi-head-attention.md: The practical form attention takes in the Transformer (seemulti-head-attention.md). -
residual-connections.md: The skip connections that make deep Transformers trainable (seeresidual-connections.md). -
layer-normalization.md: The normalization scheme that stabilizes training (seelayer-normalization.md). -
feed-forward-networks.md: The layers that store factual knowledge (seefeed-forward-networks.md). -
positional-encoding.md: Covered in a dedicated topic; the mechanism that gives order to the Transformer's otherwise order-agnostic attention. -
autoregressive-generation.md: How the decoder generates text token by token (seeautoregressive-generation.md). -
grouped-query-attention.md: The KV-sharing strategy used in most modern models (seegrouped-query-attention.md). -
mixture-of-experts.md: The architectural extension replacing dense FFNs with sparse, routed expert networks (seemixture-of-experts.md). -
state-space-models.md: The primary architectural alternative aiming to replace the quadratic attention mechanism with linear-time recurrence (seestate-space-models.mdin Advanced & Emerging).
Further Reading
- "Attention Is All You Need" -- Vaswani et al., 2017 (the original Transformer paper)
- "The Illustrated Transformer" -- Jay Alammar (widely regarded as the best visual explanation)
- "Formal Algorithms for Transformers" -- Mary Phuong and Marcus Hutter, 2022 (a rigorous mathematical treatment)
- "LLaMA: Open and Efficient Foundation Language Models" -- Touvron et al., 2023 (codified the modern decoder-only recipe: Pre-Norm with RMSNorm, SwiGLU, RoPE)
- "The Llama 3 Herd of Models" -- Meta, 2024 (the most detailed public description of a modern large-scale Transformer training and architecture)