One-Line Summary: Sampling strategies control how an LLM selects the next token from its predicted probability distribution, ranging from deterministic (always pick the most likely) to highly creative (sample from a broad set of candidates), with each method offering a different trade-off between coherence and diversity.
Prerequisites: Softmax function, probability distributions, logits (raw model outputs before softmax), autoregressive generation (token-by-token left-to-right).
What Is Token Sampling?
When an LLM generates text, it does not "know" the next word. It produces a probability distribution over its entire vocabulary -- often 32,000 to 128,000 tokens -- and then must choose one. The strategy for making that choice profoundly affects the quality, creativity, and consistency of the output.
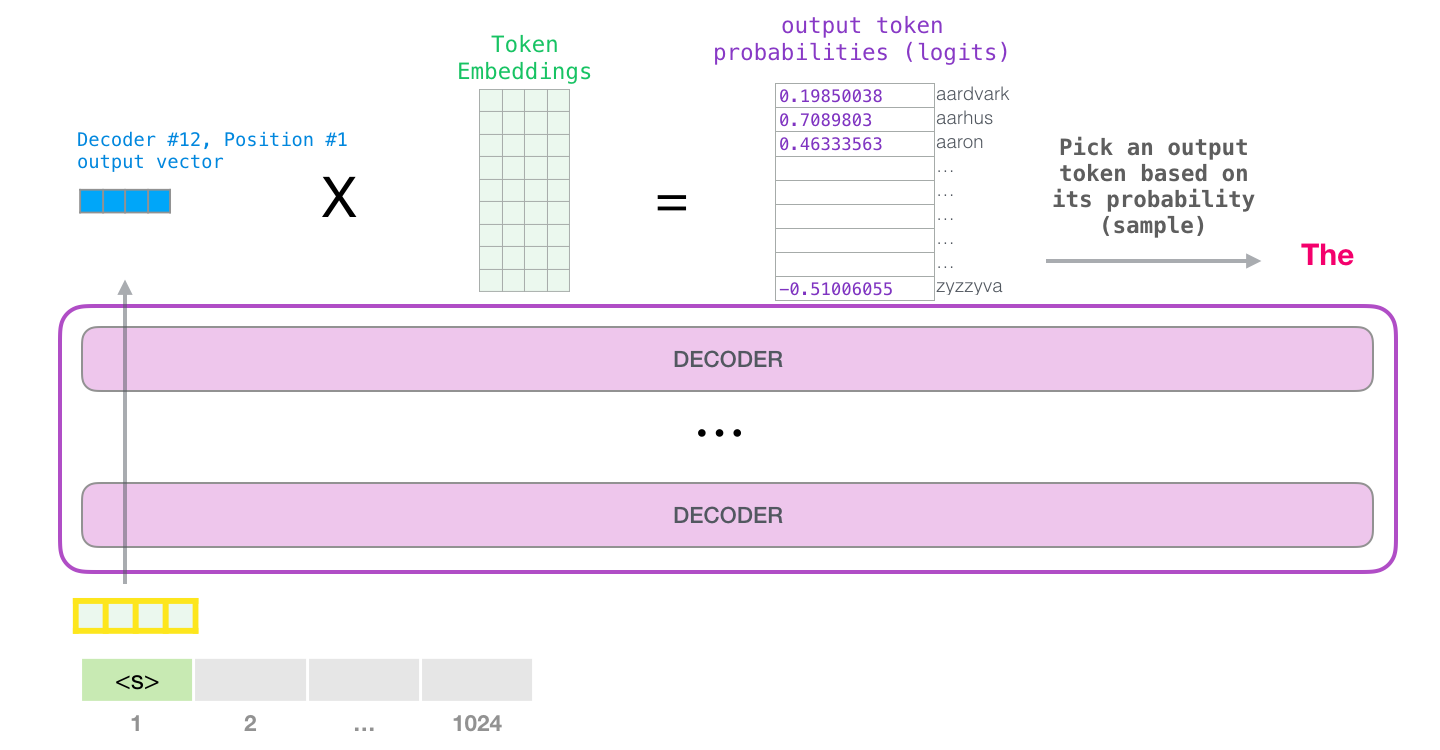 Source: Jay Alammar – The Illustrated GPT-2
Source: Jay Alammar – The Illustrated GPT-2
Think of it like a chef selecting ingredients. Greedy decoding always picks the single freshest ingredient regardless of the dish. Temperature adjusts how adventurous the chef is. Top-k limits the chef to choosing among only the k freshest ingredients. Top-p lets the chef consider any ingredient that, together with better options, makes up a certain percentage of total freshness. Each approach yields different meals.
How It Works
flowchart LR
subgraph L1["Top-k"]
LI3["Top-p sampling comparison"]
end
subgraph R2["Top-p sampling comparison showing how"]
RI4["Feature 1"]
endGreedy Decoding
The simplest strategy: always select the token with the highest probability.
Fast and deterministic, but tends to produce repetitive, generic text. It often gets stuck in loops and misses higher-quality sequences that require a less-probable token early on.
Temperature Scaling
Temperature modifies the logits before applying softmax, controlling the "sharpness" of the distribution:
where z_i are the raw logits and T is the temperature parameter.
- T = 1.0: The default distribution as the model learned it.
- T < 1.0 (e.g., 0.3): Sharpens the distribution, making high-probability tokens even more likely. Approaches greedy decoding as T approaches 0.
- T > 1.0 (e.g., 1.5): Flattens the distribution, giving low-probability tokens a better chance. Increases creativity but also increases incoherence.
Temperature does not change which tokens are available -- it changes how likely each one is to be chosen.
Top-K Sampling
Top-k sampling truncates the distribution to only the k most probable tokens, then renormalizes:
- Sort tokens by probability.
- Keep only the top k tokens.
- Set all other probabilities to 0.
- Renormalize the remaining k probabilities to sum to 1.
- Sample from this truncated distribution.
For example, with k = 50, the model only considers the 50 most likely tokens at each step. This prevents sampling from the long tail of nonsensical tokens.
Weakness: A fixed k is a blunt instrument. When the model is confident (one token has 95% probability), k = 50 still allows 49 unlikely tokens. When the model is uncertain (many tokens are plausible), k = 50 might cut off reasonable options.
Nucleus (Top-P) Sampling
Top-p (nucleus) sampling, introduced by Holtzman et al. (2020), adapts the cutoff dynamically:
- Sort tokens by probability in descending order.
- Accumulate probabilities until the cumulative sum reaches p.
- Keep only the tokens in this "nucleus."
- Set all other probabilities to 0 and renormalize.
- Sample from the nucleus.
With p = 0.9, the model considers the smallest set of tokens whose combined probability is at least 90%. When the model is confident, this might be just 2-3 tokens. When uncertain, it might be hundreds.
This adaptive behavior makes top-p generally more robust than top-k across different contexts within the same generation.
Min-P Sampling
Min-p is a newer approach that sets a relative probability floor. A token is included only if its probability is at least some fraction of the most probable token's probability:
With min_p = 0.1, if the top token has probability 0.6, any token with probability below 0.06 is excluded. This scales naturally: when the model is confident, the threshold is high and few tokens pass; when uncertain, the threshold is low and many tokens remain.
Min-p avoids both the fixed-size problem of top-k and the occasional instability of top-p where a long tail of very low-probability tokens can sneak into the nucleus.
Beam Search
Beam search maintains multiple candidate sequences (beams) in parallel:
- At each step, expand each beam by considering the top k next tokens.
- Score all expanded sequences by cumulative log-probability.
- Keep only the top b sequences (beam width).
- Repeat until all beams produce an end token.
Beam search with beam width b finds better overall sequences than greedy decoding but is computationally expensive (b times the cost) and tends to produce bland, high-probability text. It is most useful for tasks with a clear "correct" output, like machine translation, rather than open-ended generation.
Repetition, Frequency, and Presence Penalties
These penalties discourage the model from repeating itself:
- Repetition penalty: Divides the logits of previously generated tokens by a penalty factor (e.g., 1.2). Simple but effective.
- Frequency penalty: Subtracts a value proportional to how many times a token has appeared. Tokens used 5 times are penalized more than tokens used once.
- Presence penalty: Subtracts a flat value from any token that has appeared at all, regardless of frequency. Encourages topic diversity.
These are applied to logits before temperature scaling and top-k/top-p filtering.
Why It Matters
Sampling strategy is arguably the most user-facing aspect of LLM behavior. The same model can produce robotic, repetitive text or wildly creative prose depending solely on these settings. For application developers, choosing the right sampling configuration is critical:
- Customer support chatbots need low temperature for consistent, accurate answers.
- Creative writing assistants need higher temperature with top-p filtering for interesting but coherent text.
- Code generation benefits from low temperature (correctness matters more than creativity).
- Brainstorming tools want high diversity with guardrails against nonsense.
Key Technical Details
- Temperature and top-k/top-p are typically combined: temperature is applied first (to logits), then top-k or top-p filters the resulting distribution.
- Setting both top-k and top-p applies both filters (intersection). Most practitioners use one or the other.
- A temperature of 0 is often implemented as greedy decoding (argmax) rather than true division by zero.
- Most API providers (OpenAI, Anthropic) default to temperature around 0.7-1.0 and top-p around 0.9-1.0.
- Beam search is largely unused for chat/conversational LLMs due to its tendency toward generic output and high cost.
- Classifier-Free Guidance (CFG) is an emerging technique borrowed from image generation that interpolates between conditional and unconditional logits to strengthen instruction following.
Common Misconceptions
- "Temperature = 0 means the model gives the 'right' answer." It means the model gives the most probable answer, which is not always the best or most helpful one. Temperature 0 can produce degenerate outputs for open-ended prompts.
- "Higher temperature = more creative." Only up to a point. Beyond about 1.2-1.5, outputs rapidly become incoherent rather than creative. Temperature amplifies randomness, not imagination.
- "Top-p = 1.0 means no filtering." Correct -- and this is often the default, meaning top-p is effectively disabled unless explicitly set lower.
- "These settings affect the model's understanding." They do not. The model's internal representations and probabilities are fixed. Sampling strategies only change how the output token is selected from that fixed distribution.
- "Beam search always produces better results." It produces higher-probability sequences, but human evaluators often prefer the more varied outputs from nucleus sampling.
Connections to Other Concepts
kv-cache.md: Every sampling strategy still relies on KV cache for efficient autoregressive generation. The sampling choice happens after the forward pass.speculative-decoding.md: The acceptance/rejection step in speculative decoding must account for the target model's sampling distribution, making the interaction between speculative decoding and non-greedy sampling a subtle technical challenge.knowledge-distillation.md: Temperature plays a dual role -- in distillation, high temperature softens the teacher's distribution to transfer more information. In sampling, it softens the distribution to increase diversity.quantization.md: Reduced precision can slightly alter the probability distribution, which interacts with sampling. At very low bit widths, the effective temperature may shift.
Further Reading
- "The Curious Case of Neural Text Degeneration" (Holtzman et al., 2020) -- The paper that introduced nucleus (top-p) sampling and demonstrated why greedy and beam search produce degenerate text.
- "Hierarchical Neural Story Generation" (Fan et al., 2018) -- Early influential work on top-k sampling for creative text generation.
- "A Systematic Evaluation of Large Language Model Sampling Strategies" -- Various benchmark studies comparing sampling methods across tasks, useful for practical parameter selection.