One-Line Summary: PagedAttention applies OS-style virtual memory paging to the KV cache, breaking each sequence's key-value data into fixed-size blocks that are dynamically allocated and mapped through per-sequence block tables, eliminating 60-80% memory waste and enabling 2-4x higher serving throughput.
Prerequisites: KV cache, self-attention, memory-bandwidth-bound vs. compute-bound operations, GPU memory hierarchy, virtual memory concepts (paging, page tables).
What Is PagedAttention?
Imagine a library where every book must be stored on a single, unbroken shelf. If a shelf is 100 slots long but a book only needs 37 slots, the remaining 63 slots sit empty -- no other book can use them. Worse, when you do not know in advance how long a book will be (it is still being written), you must reserve the maximum possible shelf length, wasting even more space. Now imagine a smarter system: each book's pages are scattered across any available slot in the library, and a compact index card records which slot holds which page. Suddenly, every slot can be used, and books of unpredictable length grow one page at a time. This is exactly what PagedAttention does for the KV cache.
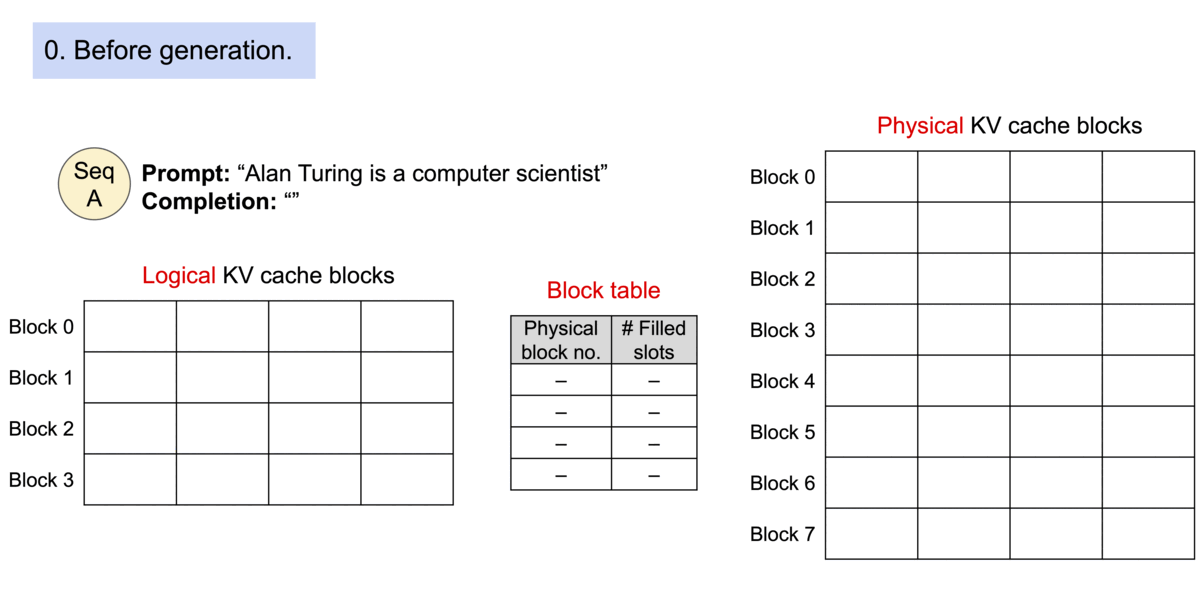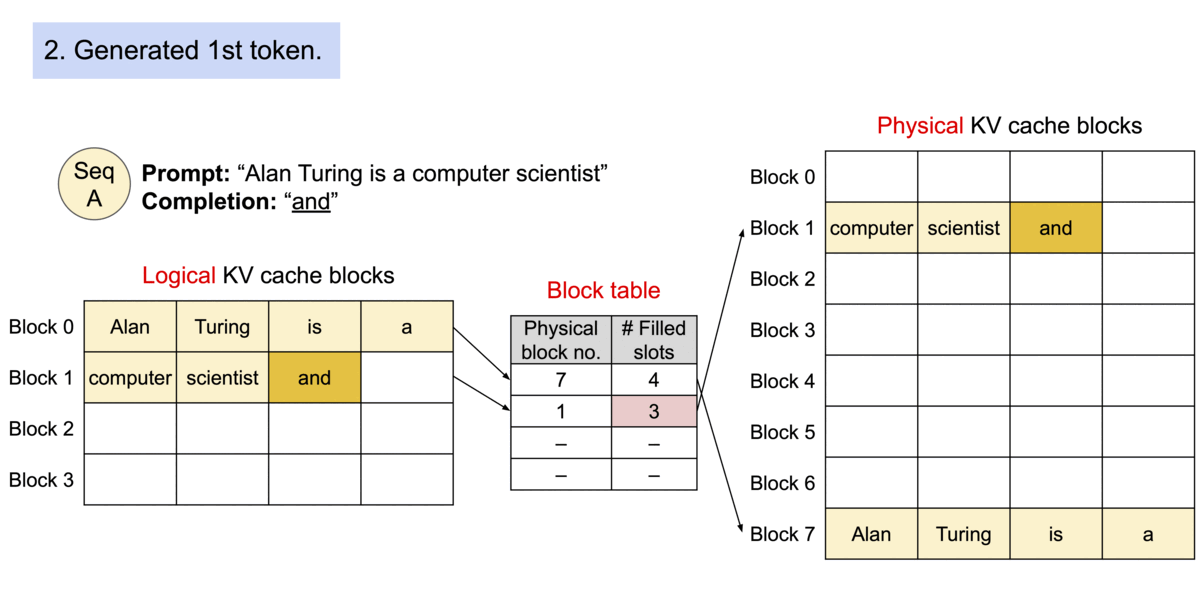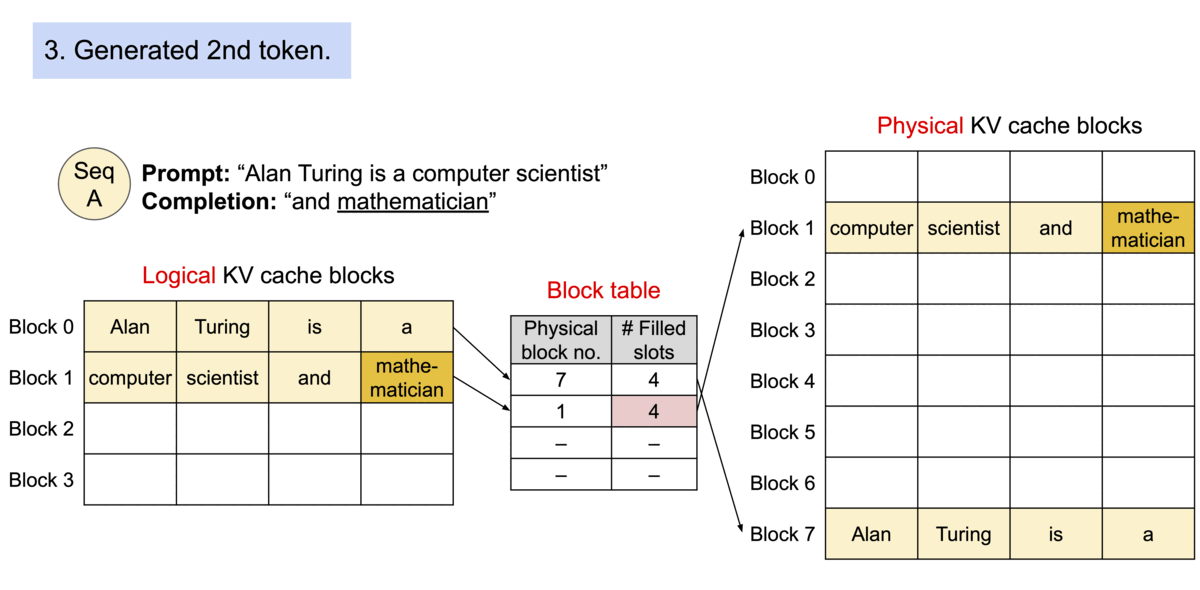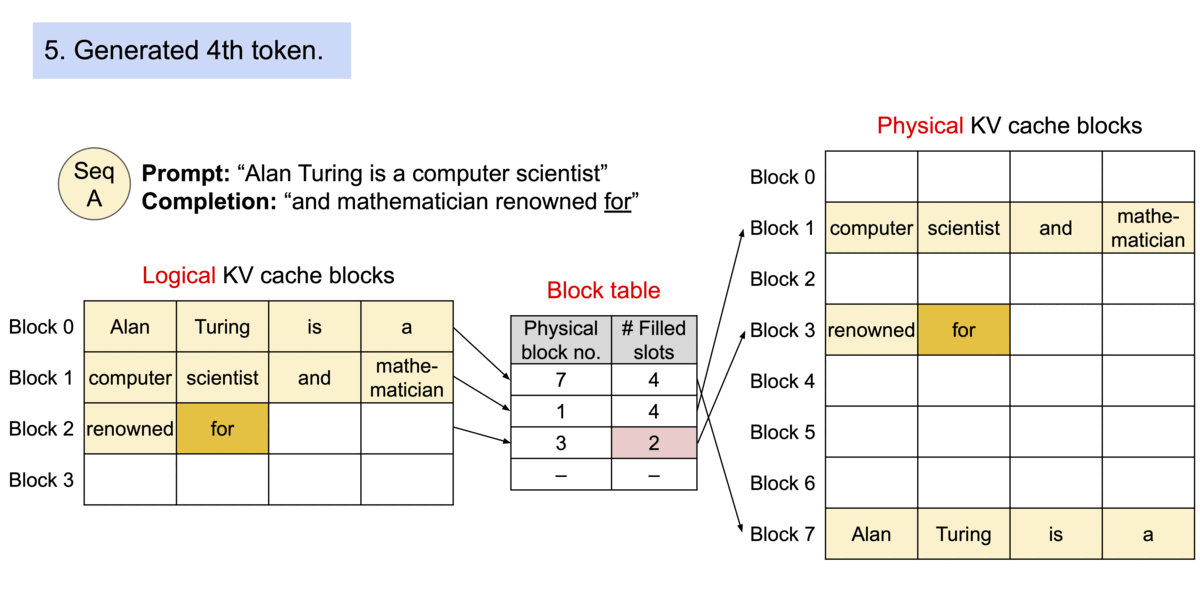 Source: vLLM Blog – vLLM: Easy, Fast, and Cheap LLM Serving
Source: vLLM Blog – vLLM: Easy, Fast, and Cheap LLM Serving
In standard LLM serving, the KV cache for each sequence must occupy a contiguous block of GPU memory, pre-allocated to the maximum possible sequence length. Because generation lengths are unknown in advance, systems over-provision aggressively. Internal fragmentation (allocated but unused space within a reservation) and external fragmentation (unusable gaps between allocations) together waste 60-80% of KV cache memory. Since the KV cache is the dominant memory consumer during inference -- often larger than the model weights themselves at high batch sizes -- this waste directly limits how many sequences the GPU can serve simultaneously.
PagedAttention, introduced by the vLLM team (Kwon et al., 2023), solves this by borrowing the core abstraction of virtual memory from operating systems. Each sequence's KV cache is divided into fixed-size blocks (pages), and a per-sequence block table maps logical block indices to physical block locations in GPU memory. Blocks are allocated on demand as tokens are generated, and freed immediately when a sequence completes.
How It Works
flowchart LR
S1["Memory waste comparison between contiguous"]
S2["60-80% savings"]
S1 --> S2Block Tables and Dynamic Allocation
Each KV cache page holds the key and value vectors for a fixed number of tokens (typically 16 or 32). A block table for each sequence maps logical positions to physical memory blocks:
Sequence A block table:
Logical Block 0 → Physical Block 7
Logical Block 1 → Physical Block 3
Logical Block 2 → Physical Block 12
Sequence B block table:
Logical Block 0 → Physical Block 1
Logical Block 1 → Physical Block 9When a new token is generated, the system checks whether the current last block has room. If so, the new KV vectors are appended in-place. If the block is full, a new physical block is allocated from a free list and appended to the block table. This means:
- No pre-allocation: Memory grows exactly as needed, one block at a time.
- No contiguity requirement: Blocks for a single sequence can be scattered anywhere in GPU memory.
- Immediate reclamation: When a sequence finishes, all its physical blocks return to the free list instantly.
Modified Attention Kernel
Standard attention kernels assume contiguous KV tensors. PagedAttention requires a custom CUDA kernel that, for each query token, looks up the block table to gather the correct key and value vectors from their scattered physical locations:
# Pseudocode for paged attention computation
for each query_token in sequence:
for each logical_block in block_table[sequence_id]:
physical_block = block_table[sequence_id][logical_block]
keys = kv_cache_pool[physical_block].keys
values = kv_cache_pool[physical_block].values
# Compute attention scores against this block's keys
scores = query_token @ keys.T / sqrt(d_k)
# Accumulate weighted values
output += softmax(scores) @ valuesIn practice, the kernel is fused and highly optimized, processing multiple blocks in parallel. The overhead of indirect addressing through the block table is minimal compared to the memory savings gained.
Copy-on-Write for Shared Prefixes
When multiple sequences share a prefix (e.g., the same system prompt), their block tables can point to the same physical blocks for the shared portion. If one sequence needs to modify a shared block (which happens when decoding diverges), a copy-on-write mechanism duplicates only that block. This enables efficient beam search and parallel sampling without duplicating the entire KV cache per candidate.
Integration with Radix Trees (RadixAttention)
SGLang extends PagedAttention with a radix tree data structure that indexes all cached KV blocks by their token content. When a new request arrives, the system traverses the radix tree to find the longest matching prefix already in the cache, reuses those blocks, and only computes KV vectors for the new tokens. Eviction follows an LRU (Least Recently Used) policy at the block level.
Why It Matters
- Memory efficiency: PagedAttention reduces KV cache memory waste from 60-80% to under 4%, enabling far more concurrent sequences on the same GPU hardware.
- Throughput multiplication: By fitting 2-4x more sequences in memory, the GPU processes more tokens per second, directly reducing serving cost.
- Foundation of modern serving: vLLM, the most widely deployed open-source LLM serving engine, is built entirely around PagedAttention. TensorRT-LLM, SGLang, and other frameworks have adopted the same principle.
- Enables advanced scheduling: Dynamic block allocation makes continuous batching, prefix caching, and speculative decoding far more practical since memory can be reclaimed and reassigned at fine granularity.
- Scales with context length: As context windows grow to 128K+ tokens, the KV cache grows proportionally. Without paging, long-context serving would require enormous over-provisioned memory buffers.
Key Technical Details
- Block size: Typical values are 16 or 32 tokens per block. Smaller blocks reduce internal fragmentation but increase block table overhead; larger blocks amortize metadata costs but waste more space in the final partially-filled block.
- Fragmentation reduction: Internal fragmentation is limited to the last block of each sequence (at most
block_size - 1token slots wasted). External fragmentation is eliminated entirely since any free block can be used by any sequence. - Memory overhead of block tables: Each block table entry is a single integer (physical block index). For a sequence of 4096 tokens with block size 16, the block table has 256 entries -- negligible compared to the KV data itself.
- Kernel performance: The paged attention kernel in vLLM achieves within 5-10% of the throughput of a contiguous-memory kernel for typical workloads, a small price for the memory savings.
- Multi-GPU support: Block tables naturally extend to distributed settings. Each GPU maintains its own physical block pool, and the block table maps logical blocks to (GPU, physical block) pairs.
- Pre-emption support: If memory pressure is high, low-priority sequences can have their blocks swapped to CPU memory or recomputed later, enabling graceful degradation under load.
Common Misconceptions
- "PagedAttention is only useful for large batch sizes." Even at batch size 1, the elimination of pre-allocation waste is valuable, especially for long or variable-length sequences. The benefits compound at larger batch sizes, but the mechanism helps universally.
- "The indirection through block tables adds significant latency." The overhead is minimal (typically <5%) because modern GPUs handle indirect memory access efficiently, and the computation is dominated by the matrix operations of attention, not by address lookups.
- "PagedAttention changes the model's outputs." It is purely a memory management optimization. The mathematical computation of attention is identical -- the same keys, values, and queries produce the same results regardless of their physical memory layout.
- "You need PagedAttention only if you are memory constrained." In practice, nearly all LLM serving deployments are memory constrained at scale. The KV cache is almost always the binding resource, making paged management effectively mandatory.
Connections to Other Concepts
kv-cache.md: PagedAttention is a memory management layer on top of the KV cache. Understanding the KV cache -- what it stores, how it grows, and why it dominates memory -- is essential context.continuous-batching.md: Dynamic block allocation enables continuous batching by making it trivial to allocate memory for incoming requests and reclaim it from completed ones without defragmenting.prefix-caching.md: Copy-on-write and block-level sharing are the mechanisms that make prefix caching efficient. RadixAttention builds directly on PagedAttention's block abstraction.flash-attention.md: Flash Attention optimizes the computation of attention (tiling for SRAM locality). PagedAttention optimizes the memory management of attention's KV data. They are complementary and used together in production.speculative-decoding.md: When draft tokens are rejected, their KV cache blocks can be freed immediately, making speculative decoding more memory-efficient under paged management.
Further Reading
- Kwon et al., "Efficient Memory Management for Large Language Model Serving with PagedAttention" (2023) -- The foundational paper introducing PagedAttention and vLLM, with detailed benchmarks showing 2-4x throughput improvement.
- Zheng et al., "SGLang: Efficient Execution of Structured Language Model Programs" (2024) -- Introduces RadixAttention, which extends PagedAttention with radix-tree-based prefix caching.
- vLLM documentation (vllm.readthedocs.io) -- Practical guide to deploying and configuring PagedAttention in production.