One-Line Summary: Rotary Position Embedding encodes token positions by rotating query and key vectors in the attention mechanism, so that their dot product naturally depends on the relative distance between tokens rather than their absolute positions.
Prerequisites: Understanding of positional encoding (why transformers need position information), self-attention mechanism (queries, keys, values, dot product attention), basic complex number or rotation matrix concepts, and familiarity with why relative position is preferred over absolute position.
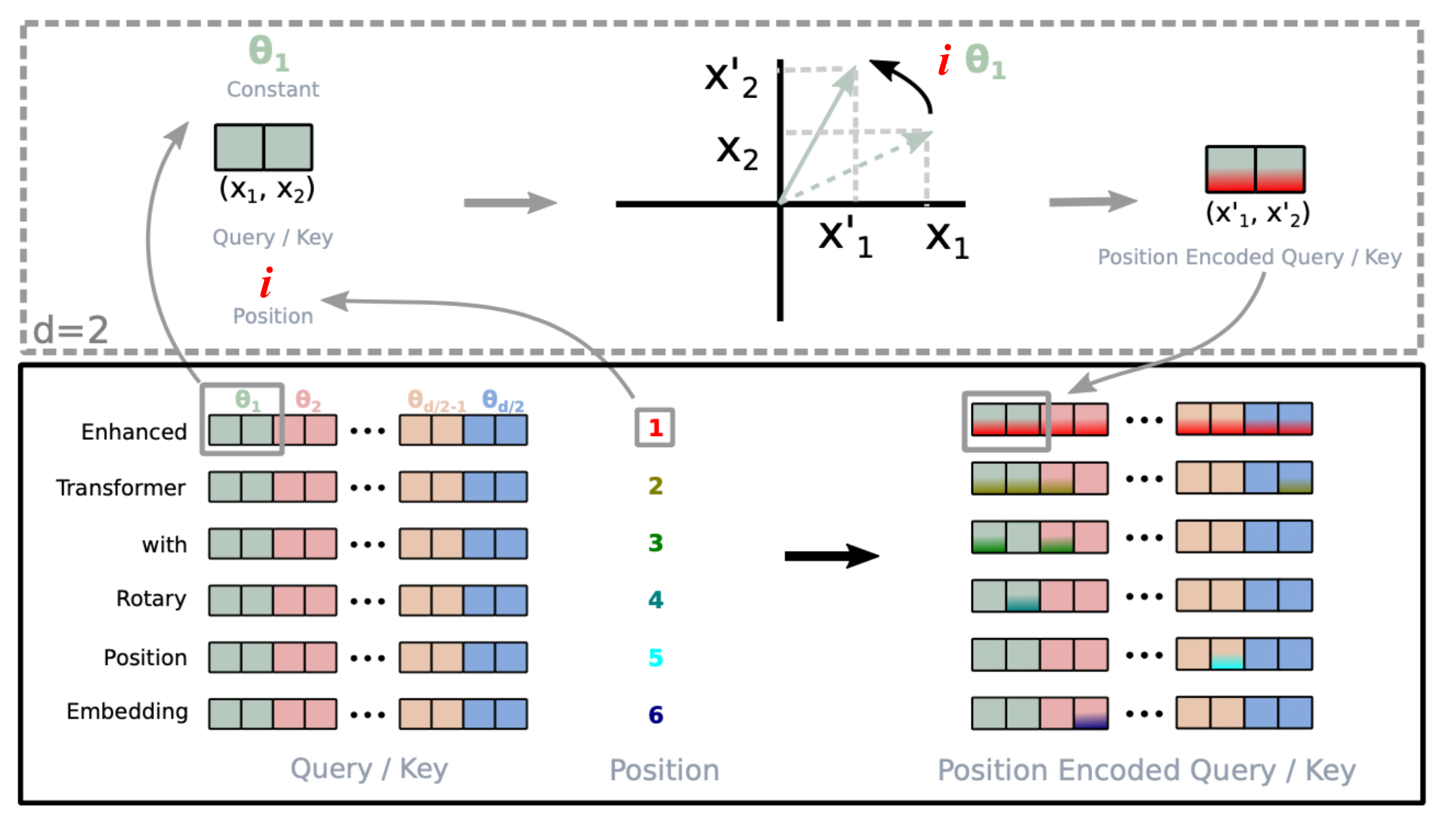
What Is Rotary Position Embedding?
Imagine two clock hands. Each starts pointing in a specific direction determined by the token it represents (its embedding). Now, rotate each hand by an angle proportional to its position in the sequence -- the first token gets a small rotation, the tenth token gets a larger rotation, the hundredth token gets a much larger rotation.
 Source: Lilian Weng – The Transformer Family
Source: Lilian Weng – The Transformer Family
When you measure the angle between the two hands, it depends only on the difference in their positions, not on where they are in absolute terms. Tokens that are 5 apart will always have the same angular difference, whether they're at positions (2, 7) or (100, 105).
This is the core insight of RoPE. By encoding position as rotation, the relative position information falls naturally out of the dot product computation in attention. Proposed by Jianlin Su et al. in 2021, RoPE has become the dominant positional encoding in modern LLMs -- it is used by LLaMA, Mistral, PaLM, Qwen, Gemma, and most other leading models.
How It Works
flowchart TD
C1["embedding dimension pairs"]
C2["showing low-frequency components for long-"]
C3["high-frequency for local position encoding"]
C1 --> C2
C2 --> C3The Mathematical Foundation
RoPE operates on pairs of dimensions in the query and key vectors. For a 2D case, consider a query vector at position . RoPE applies a rotation matrix:
where is a frequency parameter. The key vector at position is similarly rotated by .
The attention score between positions and becomes:
The last step follows because rotation matrices have the property . The dot product depends only on the relative position , not on the absolute positions and individually.
Extending to Higher Dimensions
For a -dimensional embedding, RoPE divides the dimensions into pairs, each rotating at a different frequency:
The full rotation for position is a block-diagonal matrix:
where each is a 2x2 rotation matrix. Low-frequency dimensions ( small) encode coarse, long-range position information. High-frequency dimensions ( large) encode fine-grained, local position information. This multi-frequency scheme is directly analogous to the sinusoidal positional encoding from the original transformer -- but applied within the attention computation itself rather than added to the embeddings.
Complex Number Interpretation
Equivalently, RoPE can be understood through complex numbers. Treating each dimension pair as a complex number , RoPE simply multiplies by :
This is an elegant rotation in the complex plane, and the relative position property follows from:
The asterisk denotes the complex conjugate. The phase depends only on the distance .
Context Extension: NTK-Aware Interpolation and YaRN
A critical challenge: if a model is trained with RoPE on sequences of length , how can it handle sequences of length ?
See also the detailed RoPE explanation with diagrams at: EleutherAI Blog – Rotary Embeddings -- includes visual derivations of the rotation matrices and their effect on attention scores.
Position Interpolation (PI): Simply scale all positions by , mapping positions to . This works but requires fine-tuning and can lose resolution for nearby tokens.
NTK-Aware Interpolation: Instead of uniformly scaling all frequencies, it scales primarily the low-frequency components (which carry long-range information) while preserving high-frequency components (which carry local information). The base frequency is modified:
where is a scaling factor. This is analogous to changing the base of the number system rather than squishing numbers into a smaller range.
YaRN (Yet another RoPE extensioN): Combines NTK-aware interpolation with a temperature adjustment to the attention logits and dimension-dependent interpolation. It divides dimensions into three groups:
- High-frequency dimensions: no interpolation needed (they don't "wrap around" within training length).
- Low-frequency dimensions: full interpolation applied.
- Medium-frequency dimensions: smooth interpolation between the two extremes.
YaRN achieves reliable context extension with minimal fine-tuning, enabling models trained at 4K context to operate effectively at 64K-128K.
Why It Matters
RoPE has become the de facto standard for position encoding in modern LLMs for several compelling reasons:
- Relative position for free: The dot product structure naturally encodes relative distance, which aligns with how language works (syntax and semantics are about relative word positions, not absolute ones).
- No additional parameters: Unlike learned positional embeddings, RoPE introduces zero trainable parameters. The rotation angles are computed deterministically from the position.
- Extensibility: The context extension techniques (PI, NTK, YaRN) allow models to generalize beyond their training length, which has been crucial for the expansion from 2K/4K context windows to 128K and beyond.
- Efficiency: RoPE is applied as element-wise operations on queries and keys, adding negligible computational overhead.
- Compatibility with KV caching: RoPE rotations are applied independently to each position, so cached keys don't need recomputation when the sequence extends -- essential for efficient autoregressive inference.
Key Technical Details
- RoPE is applied only to queries and keys, not to values. Values carry content information that should not be position-modulated.
- The base frequency of 10,000 is a design choice inherited from sinusoidal encoding. Some models (notably Code LLaMA) use a base of 1,000,000 for better long-context performance, as the higher base stretches the frequency spectrum.
- RoPE naturally leads to a decay in attention with distance: at high-frequency dimensions, far-apart tokens have rapidly oscillating phases that tend to cancel out, creating a soft distance penalty. This mirrors how nearby words are typically more relevant than distant ones.
- In multi-head attention, RoPE is applied independently within each head. Different heads can learn to use the positional information differently -- some heads attend locally, others globally.
- The computational implementation avoids constructing the full rotation matrix. Instead, it uses element-wise multiplication and addition: for pair , the rotated values are and .
Common Misconceptions
- "RoPE replaces attention." RoPE modifies the queries and keys within the standard attention mechanism. Attention itself is unchanged; RoPE is a preprocessing step on Q and K.
- "RoPE can extrapolate to any length without modification." Vanilla RoPE degrades significantly beyond the training context length. The extension methods (PI, NTK, YaRN) are necessary for reliable long-context performance.
- "RoPE encodes absolute position." While the rotation angle is a function of absolute position , the resulting attention score depends only on relative position . The encoding is absolute in form but relative in effect.
- "All dimensions are equally important for position." Low-frequency dimensions capture long-range position, while high-frequency dimensions capture local position. Context extension methods exploit this by treating different frequency bands differently.
Connections to Other Concepts
positional-encoding.md: RoPE is a specific positional encoding method that superseded sinusoidal and learned absolute approaches.self-attention.md: RoPE operates directly within the attention computation, modifying how Q and K interact.context-window.md: RoPE's extensibility properties (NTK, YaRN) are key enablers of long-context models.token-embeddings.md: RoPE is applied after the initial embedding and Q/K projections, not to the embeddings themselves.supervised-fine-tuning.md: Context extension via RoPE modification typically requires some fine-tuning to adapt the model to the new positional distribution.
Further Reading
- Su, J., Lu, Y., Pan, S., Murtadha, A., Wen, B., & Liu, Y. (2021). "RoFormer: Enhanced Transformer with Rotary Position Embedding." arXiv:2104.09864. -- The original RoPE paper.
- Chen, S., Wong, S., Chen, L., & Tian, Y. (2023). "Extending Context Window of Large Language Models via Positional Interpolation." arXiv:2306.15595. -- Introduced Position Interpolation for extending RoPE-based models.
- Peng, B., Quesnelle, J., Fan, H., & Shippole, E. (2023). "YaRN: Efficient Context Window Extension of Large Language Models." arXiv:2309.00071. -- The state-of-the-art approach for RoPE context extension.