One-Line Summary: RLHF aligns language models with human preferences by training a reward model on human comparisons, then using reinforcement learning to optimize the language model's outputs against that reward signal -- while a KL penalty keeps it from straying too far from its original behavior.
Prerequisites: Supervised fine-tuning, basic reinforcement learning concepts (policy, reward, optimization), the concept of a loss function, and an understanding of what language model alignment means and why it is needed.
What Is RLHF?
Supervised fine-tuning teaches a model the format of good responses -- but how do you teach it the quality? If you show a model ten different ways to answer "Explain quantum computing," how does it learn which explanation is clearest, most accurate, and most helpful? You can't easily encode "helpfulness" into a simple cross-entropy loss.
 Source: Hugging Face – Illustrating RLHF
Source: Hugging Face – Illustrating RLHF
RLHF solves this by borrowing an idea from reinforcement learning: let humans express preferences between model outputs, train a separate model to predict those preferences (the reward model), and then use that reward model as a signal to improve the language model itself.
Think of it like training a chef. SFT is like giving them a cookbook (follow these recipes). RLHF is like having food critics taste pairs of dishes, learning what the critics value, and then having the chef iteratively refine their cooking based on predicted critic scores -- while making sure they don't stray so far from cooking that they start doing something completely unrecognizable.
How It Works
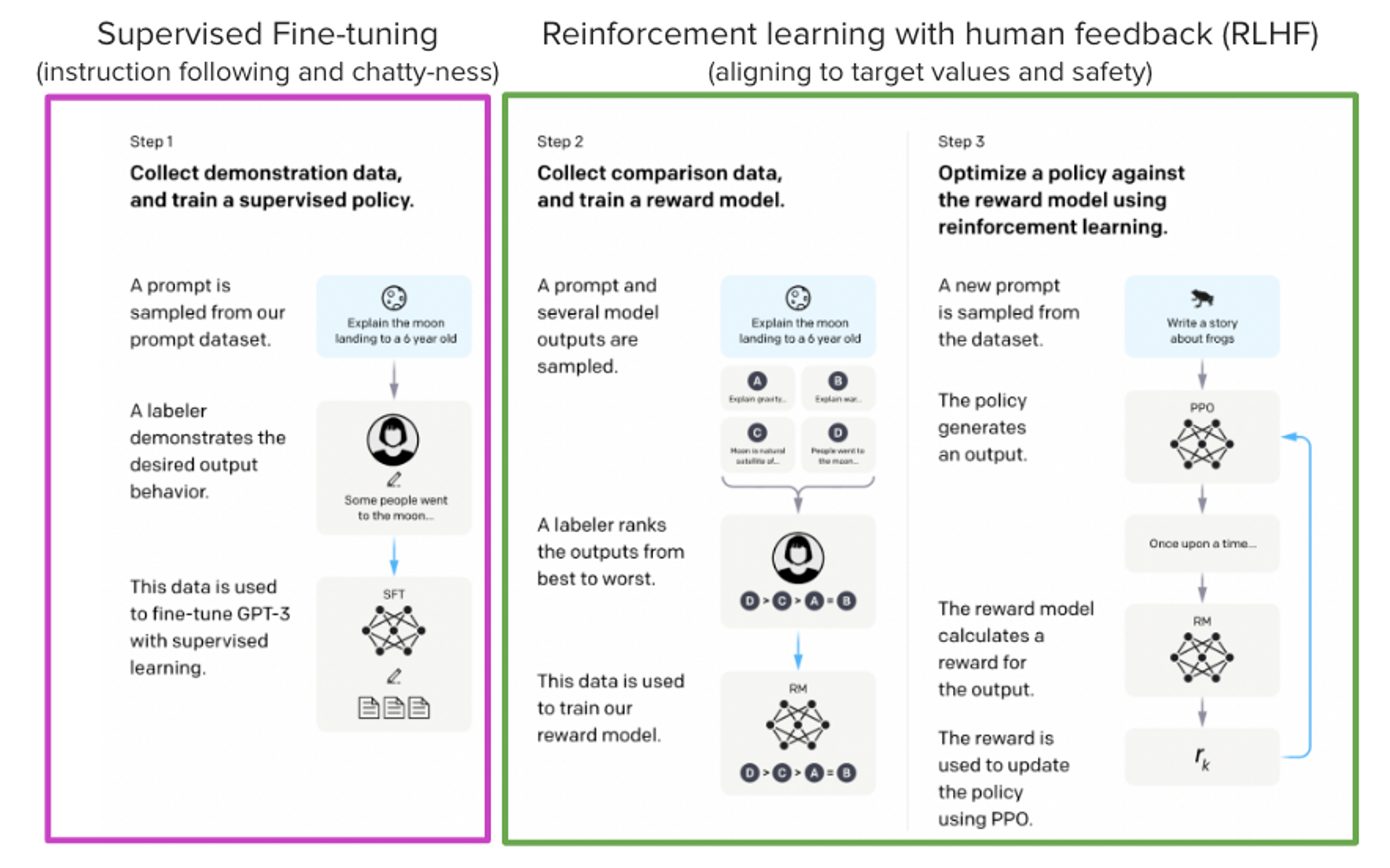
RLHF proceeds in three distinct stages:
flowchart TD
L1["policy"]
L2["reward model"]
L3["reference model"]
L4["KL penalty"]
L1 --> L2
L2 --> L3
L3 --> L4
L4 -.->|"repeat"| L1Stage 1: Collect Human Preference Data
Human annotators are presented with a prompt and two (or more) model-generated responses. They rank which response is better. For example:
Prompt: "Explain why the sky is blue in simple terms." Response A: "The sky is blue because of Rayleigh scattering..." Response B: "Blue light has a shorter wavelength..." Human judgment: A > B
This creates a dataset of preference pairs: where is the prompt, is the preferred (winning) response, and is the rejected (losing) response.
Stage 2: Train a Reward Model
A reward model is trained to assign scalar scores to (prompt, response) pairs such that preferred responses receive higher scores. The standard approach uses the Bradley-Terry model of pairwise comparisons:
Where is the sigmoid function. This loss pushes the reward model to assign higher scores to preferred responses and lower scores to rejected ones, with the sigmoid ensuring the optimization focuses on the gap between scores rather than absolute values.
The reward model is typically initialized from the SFT model itself (or the same base model), with the final language modeling head replaced by a scalar output head.
Stage 3: Optimize the Policy with PPO
The language model (now called the "policy" in RL terminology) is optimized to maximize the reward model's scores using Proximal Policy Optimization (PPO). The optimization objective is:
This is the heart of RLHF. Let's unpack it:
- : The reward model's score for the generated response. We want to maximize this.
- : A penalty term that measures how far the policy has drifted from the reference policy (typically the SFT model). controls the strength of this penalty.
- The balance: Maximize reward while staying close to the original model.
The PPO algorithm itself involves:
- Sampling: Generate responses from the current policy for a batch of prompts.
- Scoring: Evaluate responses with the reward model.
- Computing advantages: Determine how much better each response is compared to the expected reward.
- Clipped updates: Update the policy parameters with clipped gradients to prevent overly large steps (the "proximal" in PPO).
The KL Divergence Penalty: Why It's Critical
Without the KL penalty, the policy would find degenerate ways to maximize reward -- exploiting quirks in the reward model rather than genuinely improving response quality. For example, the model might learn to produce responses that are extremely verbose (because the reward model slightly prefers longer responses) or repeat certain phrases that game the reward signal.
 Source: InstructGPT Paper (arXiv:2203.02155)
Source: InstructGPT Paper (arXiv:2203.02155)
The KL divergence:
measures how much the fine-tuned model's distribution differs from the reference model's distribution, token by token. A higher KL means the model has changed more. By penalizing high KL, we ensure the model retains its general language capabilities while improving on the specific quality dimensions the reward model captures.
Why It Matters
RLHF is widely credited as the key technique that made ChatGPT possible and transformed language models from impressive demos into usable products. The InstructGPT paper (Ouyang et al., 2022) showed that a 1.3B parameter model with RLHF was preferred by human raters over a 175B parameter model without it. RLHF doesn't just improve models -- it makes smaller models behave better than larger ones without it.
This matters because human preferences are inherently comparative and multidimensional. "Helpfulness" involves accuracy, clarity, appropriate level of detail, safety, tone, and dozens of other factors that are nearly impossible to specify in a simple loss function. By training on human comparisons, RLHF implicitly captures all these dimensions.
RLHF also enabled the alignment of models with safety considerations -- teaching models to refuse harmful requests, provide balanced perspectives, and acknowledge uncertainty -- in ways that SFT alone struggled with.
Key Technical Details
- PPO hyperparameters are notoriously sensitive. The clipping range, learning rate, number of epochs per batch, and KL penalty coefficient () all interact in complex ways. Small changes can destabilize training.
- The reward model is the bottleneck. The policy can only be as good as the reward model's ability to capture human preferences. Errors in the reward model become the ceiling for alignment quality.
- Reward hacking is a persistent challenge. Models find ways to exploit reward model weaknesses -- producing responses that score high on the reward model but are actually low quality (Goodhart's Law: "When a measure becomes a target, it ceases to be a good measure").
- Training requires 4 models in memory simultaneously: the policy, the reference model, the reward model, and the value function (critic). This makes RLHF extremely memory-intensive.
- Typical values range from 0.01 to 0.2. Too low allows reward hacking; too high prevents meaningful learning.
- Multiple iterations of data collection and training can be performed, using updated models to generate new responses for human comparison.
Common Misconceptions
- "RLHF teaches the model new knowledge." Like SFT, RLHF primarily reshapes behavior and priorities, not factual knowledge. It teaches the model which of its existing capabilities to emphasize and how to present information.
- "The reward model perfectly captures human preferences." Reward models are noisy approximations. They disagree with individual human raters frequently and capture only a compressed version of preference distributions.
- "RLHF is just about safety." While safety is one goal, RLHF primarily improves helpfulness, coherence, and response quality. Safety-specific training is often a separate component.
- "PPO is the only RL algorithm used." While PPO is the most common, alternatives like REINFORCE, RLOO (REINFORCE Leave-One-Out), and expert iteration have been explored. The field is actively searching for more stable RL methods.
- "More RLHF is always better." Over-optimization against the reward model (the "alignment tax") can degrade general capabilities. There is a sweet spot.
Connections to Other Concepts
supervised-fine-tuning.md: is always the prerequisite step, providing the base policy that RLHF refines.reward-modeling.md: is a sub-component of RLHF worthy of deep study in its own right, as it is the critical bottleneck.dpo.md: emerged as a direct response to RLHF's instability, reparameterizing the problem to eliminate the need for an explicit reward model and RL loop.constitutional-ai.md: replaces human annotators with AI-generated feedback (RLAIF), modifying Stage 1 of the pipeline.- KL divergence appears throughout machine learning and information theory; in RLHF it serves as a regularizer preventing mode collapse.
Further Reading
- "Training Language Models to Follow Instructions with Human Feedback" (Ouyang et al., 2022) -- The InstructGPT paper that defined the modern RLHF pipeline and demonstrated its effectiveness at scale.
- "Learning to Summarize from Human Feedback" (Stiennon et al., 2020) -- The earlier OpenAI paper that established the reward model + PPO approach on the summarization task.
- "Proximal Policy Optimization Algorithms" (Schulman et al., 2017) -- The original PPO paper, essential for understanding the RL algorithm at the core of RLHF.