One-Line Summary: Residual connections (skip connections) add each layer's input directly to its output, creating a "residual stream" that flows through the entire model and enables effective training of networks with dozens to hundreds of layers.
Prerequisites: Basic neural network concepts (layers, gradient flow, backpropagation), understanding of the Transformer block structure (attention followed by FFN), and familiarity with the vanishing gradient problem.
What Is a Residual Connection?
Imagine a river flowing through a landscape. Along its path, tributaries add water. The river does not stop and start at each tributary -- it flows continuously, with each tributary contributing incrementally. A residual connection works the same way: there is a main "stream" of information flowing through the model, and each layer (attention, FFN) adds its contribution to this stream rather than replacing it.
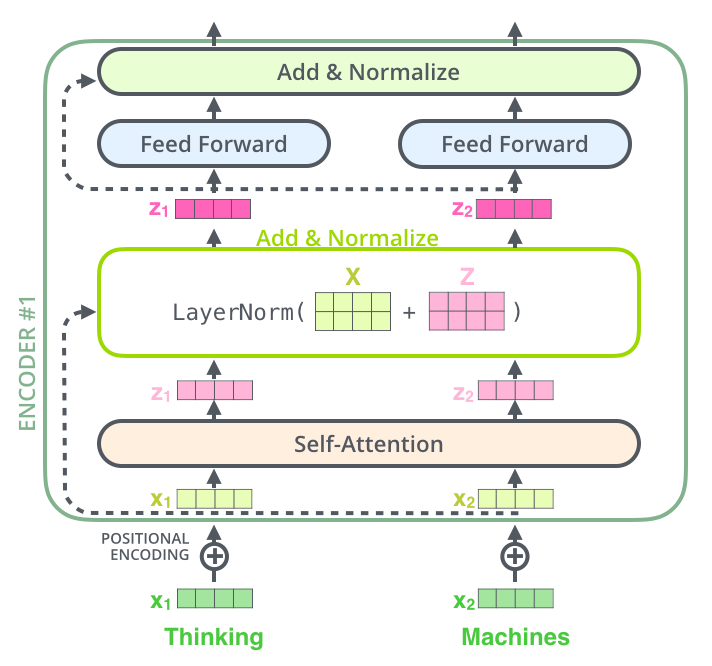 Source: Jay Alammar – The Illustrated Transformer
Source: Jay Alammar – The Illustrated Transformer
Mathematically, instead of computing where is some layer, a residual connection computes:
The layer only needs to learn the residual -- the difference between the desired output and the input. Hence the name "residual connection." If a layer has nothing useful to contribute, it can learn weights close to zero, and , meaning the input passes through unmodified. This is much easier than learning an identity mapping from scratch.
How It Works
flowchart LR
S1["Residual stream concept"]
S2["how information flows through the entire m"]
S1 --> S2In a Transformer Block
Each Transformer block contains two residual connections:
x_1 = x_0 + Attention(LayerNorm(x_0)) # First residual connection
x_2 = x_1 + FFN(LayerNorm(x_1)) # Second residual connection(This shows Pre-LN ordering. Post-LN applies LayerNorm after the addition instead.)
Through the Full Model
For a model with layers, the residual stream carries information from input to output:
where is the initial embedding (token embedding + positional encoding) and each term in the sum is one component's additive contribution. The final representation is the initial embedding plus the accumulated contributions from sub-layers.
Gradient Flow
The critical benefit for training comes from the gradient. During backpropagation, the gradient of the loss with respect to early layers must flow through the entire network. With residual connections, by the chain rule:
The identity matrix provides a gradient highway -- gradients can flow directly through the skip connection without being multiplied by layer weights. This prevents the vanishing gradient problem that plagues deep networks without residual connections, where gradients get exponentially smaller as they propagate backwards through many layers.
Why It Matters
Enabling Depth
Without residual connections, training a 100-layer Transformer would be practically impossible. Gradients would either vanish (become too small to update early layers) or explode (become too large, destabilizing training). Residual connections ensure that even the earliest layers receive meaningful gradient signal.
This is not a small detail -- it is an enabling technology. The entire scaling paradigm of modern LLMs (making models deeper and wider) depends on residual connections working correctly.
The Residual Stream Interpretation
Anthropic's mechanistic interpretability research (Elhage et al., 2021) introduced a powerful way to think about residual connections: the residual stream. Rather than viewing the Transformer as a pipeline where each layer transforms the representation, think of it as:
- A shared communication channel (the residual stream) that has a fixed dimension .
- Each attention head and FFN reads from and writes to this stream.
- The stream carries information from the input embedding all the way to the output.
Under this interpretation:
- Attention heads read from the stream (via their query and key projections), process information, and write results back to the stream (via their output projection).
- FFN layers similarly read from the stream, compute, and write back.
- The final output is the entire accumulated content of the stream.
This "stream" metaphor is why a single attention head or a single layer ablation (removing it) often causes only moderate performance degradation: the stream still carries information from all the other components.
Layer Ablation and Robustness
A remarkable property of models with residual connections: you can remove entire layers and the model still produces somewhat coherent output. This is because removing a layer only removes its additive contribution; the rest of the stream remains intact. Research has shown that middle layers can often be removed with less impact than early or late layers, suggesting a degree of redundancy in the middle of the network.
This robustness is a direct consequence of the additive nature of residual connections. In a non-residual network, removing a layer would break the entire computation chain.
Key Technical Details
- Dimension preservation: Residual connections require the input and output dimensions to be identical. This is why stays constant throughout the Transformer (all 32, 64, or 120+ layers).
- No learned parameters: The skip connection itself has zero parameters. It is a pure identity function. The learning happens in the layers that contribute to the stream.
- Interaction with layer normalization: The placement of LayerNorm relative to the residual connection (Pre-LN vs Post-LN) significantly affects training stability (see
layer-normalization.md). - Scaling at depth: In very deep models, the residual stream can grow in magnitude since each layer adds to it. This is one reason normalization is necessary.
- Originally from ResNet: Residual connections were introduced by He et al. (2015) for image classification (ResNet). The Transformer adopted them for the same fundamental reason: enabling deep networks.
- Residual stream bandwidth: The stream has a fixed bandwidth of dimensions. All information flowing through the model must be encoded in these dimensions, creating a potential bottleneck. Some research explores whether increasing independently of attention head size could be beneficial.
Common Misconceptions
- "Residual connections are a minor implementation detail." They are arguably the most important structural element enabling deep Transformers. Without them, models beyond a few layers deep would be untrainable.
- "The model learns to use or ignore the skip connection." The skip connection is always active -- it is a hard-wired identity function. The model learns how much additional information to add through each layer's contribution.
- "Each layer completely transforms the representation." In the residual stream view, each layer makes an incremental additive update. The representation evolves gradually across layers rather than being completely overwritten at each step.
- "Removing the last layer would have the most impact." While the final layer matters, empirical studies show that the impact of removing a layer varies. Early layers (which establish basic representations) and the final layer (which prepares for prediction) tend to be more critical than middle layers.
- "Residual connections eliminate the vanishing gradient problem entirely." They mitigate it dramatically but do not eliminate it completely. Very deep models still require careful initialization and learning rate scheduling. Layer normalization works in tandem with residual connections to fully stabilize training.
Connections to Other Concepts
layer-normalization.md: Works alongside residual connections to stabilize the magnitude of activations in the residual stream (seelayer-normalization.md).transformer-architecture.md: Residual connections are the structural backbone that ties attention and FFN layers together (seetransformer-architecture.md).self-attention.md: These are the components that read from and write to the residual stream (seeself-attention.md,feed-forward-networks.md).mechanistic-interpretability.md: The residual stream framework is central to understanding how Transformer circuits work.mixture-of-experts.md: MoE layers also write additively to the residual stream, just through a selected subset of expert FFNs (seemixture-of-experts.md).
Further Reading
- "Deep Residual Learning for Image Recognition" -- He et al., 2015 (the original ResNet paper that introduced skip connections)
- "A Mathematical Framework for Transformer Circuits" -- Elhage et al., Anthropic, 2021 (introduces the residual stream interpretation)
- "The Lazy Neuron Phenomenon: On Emergence of Activation Sparsity in Transformers" -- Li et al., 2023 (explores how information flows through residual streams)