One-Line Summary: Self-attention allows every token in a sequence to dynamically compute a weighted combination of all other tokens' representations, enabling the model to capture contextual relationships regardless of distance.
Prerequisites: Understanding of vectors and matrices, dot products, the softmax function, and a general sense of how neural network layers transform inputs.
What Is Self-Attention?
Think of self-attention as an internal search engine. When the model processes the word "it" in the sentence "The cat sat on the mat because it was tired," it needs to figure out what "it" refers to. Self-attention lets the model issue a query ("What am I looking for?"), compare it against keys from every other word ("What do I contain?"), and then retrieve a weighted blend of values ("Here is my information") based on the match scores.
 Source: The Illustrated Transformer -- Jay Alammar
Source: The Illustrated Transformer -- Jay Alammar
More precisely: every token produces three vectors -- a query, a key, and a value. The query of one token is compared against the keys of all tokens (including itself) to produce attention scores. These scores, after normalization, determine how much of each token's value to mix into the output representation.
This is "self" attention because the queries, keys, and values all come from the same sequence. The model is attending to itself.
How It Works
 Source: The Illustrated Transformer -- Jay Alammar
Source: The Illustrated Transformer -- Jay Alammar
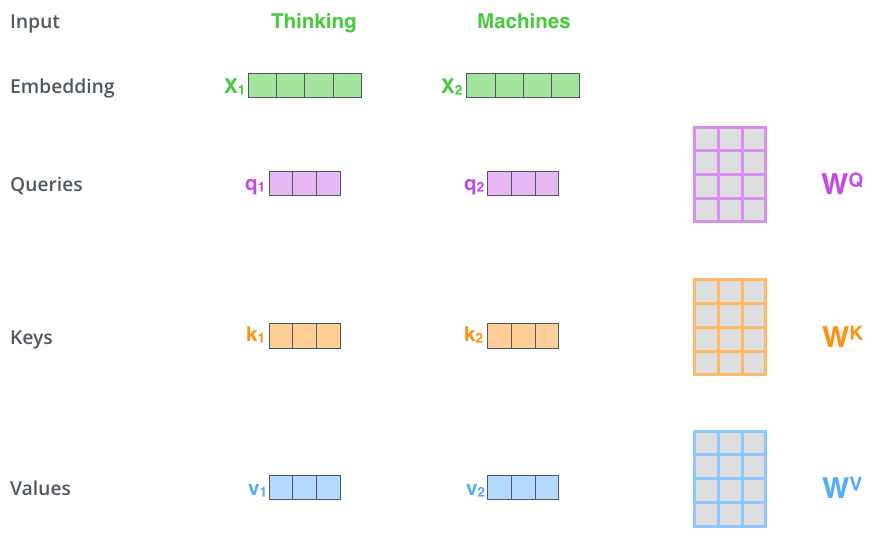
Step 1: Produce Queries, Keys, and Values
Given an input matrix (where is sequence length and is the embedding dimension), we compute:
where and are learned weight matrices.
Step 2: Compute Attention Scores
The raw attention scores are the dot product between each query and all keys:
This produces an matrix where entry represents how much token should attend to token .
Step 3: Scale
The scores are divided by :
Why scale? Without scaling, when is large, dot products tend to grow large in magnitude. Large values push softmax into regions where its gradients are extremely small (saturation), making learning slow or unstable. Dividing by keeps the variance of the dot products approximately equal to 1, regardless of the dimension. If queries and keys have components with variance 1, their dot product has variance , so dividing by normalizes this back to variance 1.
Step 4: Apply Softmax
The softmax is applied row-wise, so each row sums to 1. Row of matrix now contains the attention weights for token -- a probability distribution over all tokens indicating how much each contributes.
Step 5: Compute Weighted Values
 Source: Jay Alammar – The Illustrated Transformer
Source: Jay Alammar – The Illustrated Transformer
Each token's output is a weighted sum of all value vectors, with the weights from the attention matrix. The complete formula in one line:
The Search Engine Analogy (Expanded)
| Search Engine | Self-Attention |
|---|---|
| You type a search query | Token produces a query vector |
| Each web page has metadata/keywords | Each token produces a key vector |
| Pages are ranked by relevance | Dot product produces a relevance score |
| You get a ranked list of results | Softmax normalizes scores into a distribution |
| You read the content of top results | Value vectors are weighted and combined |
 Source: The Illustrated Transformer -- Jay Alammar
Source: The Illustrated Transformer -- Jay Alammar
The key insight: the "search query" changes depending on context. The word "bank" in "river bank" issues a different query than "bank" in "bank account," because the query is computed from the current representation, which is influenced by surrounding context in deeper layers.
Why It Matters
Self-attention is the fundamental operation that gives Transformers their power. It provides three critical capabilities:
-
Long-range dependencies: Token 1 can directly attend to token 1000 in a single step. In an RNN, information from token 1 would need to survive 999 sequential steps, getting degraded along the way.
-
Dynamic, input-dependent computation: Unlike a convolutional filter with fixed weights, attention weights change for every input. The model dynamically decides what to focus on based on the actual content it is processing.
-
Parallelism: The entire attention computation is a series of matrix multiplications. Every token's attention can be computed simultaneously on a GPU, unlike the sequential nature of RNNs.
Self-attention is also the mechanism that makes Transformers interpretable (to a degree). By visualizing attention patterns, researchers can sometimes see that the model has learned to attend to syntactically or semantically relevant tokens.
Key Technical Details
- Time complexity: -- quadratic in sequence length due to the attention matrix. This is the primary scalability bottleneck for long sequences.
- Space complexity: for storing the attention matrix (per head, per layer).
- Typical dimensions: In GPT-3 (175B), and per head.
- The attention matrix is often sparse in practice: most tokens attend strongly to only a few other tokens, with the rest receiving near-zero weight.
- Positional information is not inherent in self-attention. The operation is permutation-equivariant -- shuffling input tokens shuffles the output in the same way. Positional encodings must be added externally.
- In training, the full attention matrix is computed. Flash Attention and similar techniques compute it in tiles to reduce memory usage without changing the mathematical result.
Common Misconceptions
- "Self-attention is the same as attention." In the original Transformer, there are two kinds of attention: self-attention (within encoder or within decoder) and cross-attention (decoder attending to encoder). Self-attention is specifically when Q, K, and V all derive from the same sequence.
- "Higher attention weight means the model thinks the word is more important." Attention weights show information flow, not importance in the human sense. A token might attend heavily to a function word like "the" for syntactic reasons, not because "the" is semantically important.
- "Self-attention captures word meaning." Self-attention captures relationships between words. The meaning of individual words comes from the embeddings and the feed-forward layers. Attention is about routing and mixing information.
- "The attention matrix is interpretable." While attention visualization can be informative, research has shown that attention weights do not reliably correspond to human notions of "explanation." The model's computation is distributed across many heads and layers.
Connections to Other Concepts
multi-head-attention.md: In practice, self-attention is always used in multi-head form to capture diverse relationship types (seemulti-head-attention.md).causal-attention.md: A variant where a mask prevents attending to future tokens, used in decoder models (seecausal-attention.md).transformer-architecture.md: Self-attention is the central mechanism inside each Transformer layer (seetransformer-architecture.md).residual-connections.md: The output of self-attention is added to the input via a skip connection (seeresidual-connections.md).positional-encoding.md: Necessary because self-attention itself is position-agnostic.kv-cache.md: In autoregressive generation, the keys and values from previous tokens are cached to avoid recomputation (seeautoregressive-generation.md).
Further Reading
- "Attention Is All You Need" -- Vaswani et al., 2017 (the paper that introduced scaled dot-product attention in the Transformer)
- "A Mathematical Framework for Transformer Circuits" -- Elhage et al., Anthropic, 2021 (deep dive into how attention heads compose)
- "Efficient Transformers: A Survey" -- Tay et al., 2022 (comprehensive review of attention efficiency techniques)