One-Line Summary: Agent debate uses multiple agents in adversarial or collaborative verification roles — one proposes, another critiques — to catch errors, reduce hallucination, and improve output quality through structured disagreement.
Prerequisites: Multi-agent architectures, prompt engineering, hallucination awareness, critical reasoning
What Is Agent Debate and Verification?
Consider the peer review system in academic publishing. A researcher submits a paper, then independent reviewers — who did not write it and have no incentive to agree — evaluate the methodology, challenge the conclusions, and identify weaknesses. The paper improves through this adversarial process because the reviewers catch things the author missed, whether due to blind spots, wishful thinking, or honest mistakes. The final published paper is stronger because it survived scrutiny.
Agent debate applies this same principle to AI outputs. Instead of trusting a single agent's answer, the system routes the output through one or more critic agents whose job is to find problems. This can take many forms: a proposer-critic pair (one generates, one reviews), a red team/blue team setup (one attacks, one defends), a panel of judges (multiple agents evaluate independently), or a structured debate (agents argue opposing positions before a judge). The core insight is that agents are better at finding errors in others' work than in their own — a property that emerges from how LLMs process different prompting contexts.
This approach directly addresses one of the most persistent problems with LLM-based agents: hallucination and overconfidence. A single agent asked "Are you sure?" will almost always confirm its original answer. But a separate agent, given the answer and asked to find problems, will frequently identify genuine issues — factual errors, logical gaps, unsupported claims, and edge cases the first agent missed. The disagreement between agents is the signal; it points to where the output needs improvement.
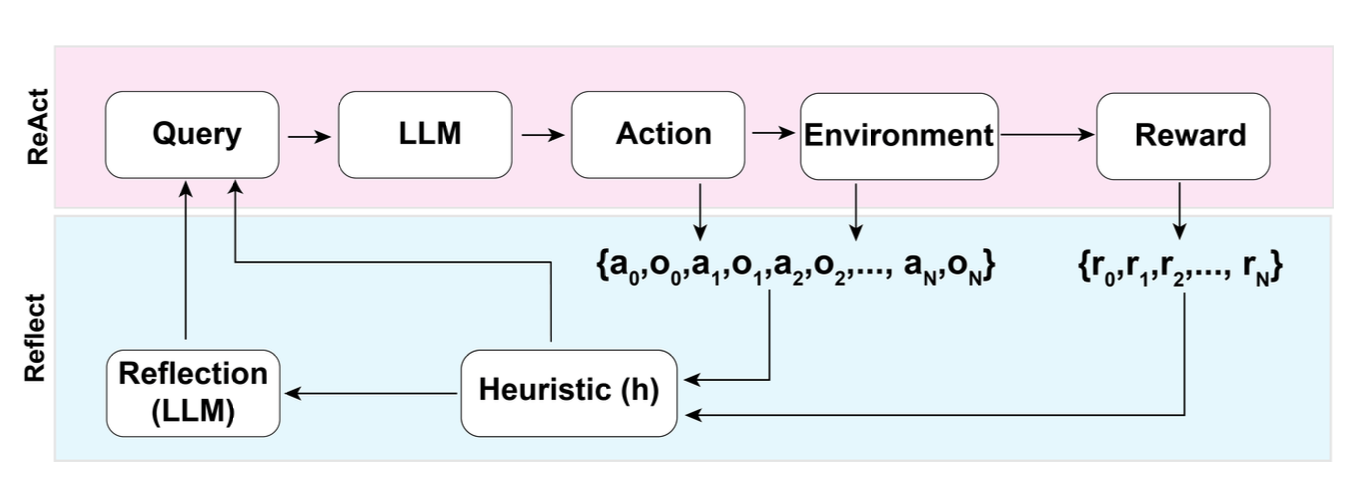 Source: Lilian Weng, "LLM Powered Autonomous Agents" (2023) — The Reflexion architecture illustrates the proposer-critic pattern: an actor generates output, an evaluator critiques it, and self-reflection produces lessons that improve the next attempt.
Source: Lilian Weng, "LLM Powered Autonomous Agents" (2023) — The Reflexion architecture illustrates the proposer-critic pattern: an actor generates output, an evaluator critiques it, and self-reflection produces lessons that improve the next attempt.
How It Works
Proposer-Critic Architecture
The simplest debate pattern:
- Proposer agent generates an initial answer, plan, or code solution.
- Critic agent receives the proposer's output (and optionally the original task) and generates a detailed critique — identifying errors, weaknesses, missing elements, and potential improvements.
- Proposer agent receives the critique and produces a revised output.
- This loop repeats for 1-3 rounds until the critic finds no significant issues or a maximum iteration count is reached.
The key to effectiveness is that the critic agent has a different system prompt that explicitly encourages skepticism and error-finding. Prompts like "Your job is to find every error, no matter how small. Be ruthless but constructive." produce more thorough critiques than "Review this output."
Red Team / Blue Team
Adapted from cybersecurity and military strategy:
- Blue team agent: Produces the output (code, plan, analysis) representing the best solution.
- Red team agent: Actively tries to break, exploit, or disprove the blue team's output. For code, this means finding bugs, security vulnerabilities, and edge cases. For analysis, this means finding logical fallacies, missing evidence, and alternative explanations.
This adversarial setup is particularly effective for security-sensitive outputs, where the red team agent is explicitly prompted to think like an attacker.
Multi-Agent Panel
Multiple agents independently evaluate the same question or output, then their responses are compared:
- N agents (typically 3-5) each produce an answer independently.
- A judge agent (or automated comparison) identifies areas of agreement and disagreement.
- Disagreements trigger deeper investigation — the judge may ask dissenting agents to explain their reasoning.
- The final answer synthesizes the majority view, adjusted for the quality of dissenting arguments.
Structured Debate
Two agents explicitly argue opposing positions (for and against) before a judge:
- Agent A argues for a conclusion; Agent B argues against.
- Each gets 2-3 rounds to present evidence, rebut the other, and refine their position.
- A judge agent evaluates both sides and renders a decision with reasoning.
This is particularly useful for questions with no clear right answer, where exploring both sides leads to more nuanced and balanced conclusions.
Why It Matters
Hallucination Reduction
Single agents hallucinate because they have no mechanism to check their own outputs against ground truth. A critic agent provides that mechanism — not by accessing ground truth directly, but by applying independent reasoning that often catches inconsistencies, implausible claims, and logical errors. Studies show that debate reduces factual errors by 20-40% compared to single-agent generation.
High-Stakes Decision Support
For applications where errors have significant consequences — medical analysis, legal review, financial planning, code security — single-agent outputs are insufficiently reliable. Debate architectures provide a structured way to increase confidence in outputs before they are acted upon, similar to how critical decisions in organizations require multiple sign-offs.
Calibrated Confidence
When multiple agents agree, confidence is justified. When they disagree, the system (and the user) can be appropriately uncertain. This calibration of confidence is valuable — knowing when to trust the output and when to involve a human is as important as the output itself.
Key Technical Details
- Same model, different prompts: Debate is effective even when all agents use the same underlying model. The different system prompts (proposer vs. critic, for vs. against) create sufficiently different reasoning contexts. Using different models (e.g., Claude and GPT-4) can further diversify perspectives.
- Critic specificity: Vague critiques ("this could be better") are unhelpful. The critic prompt should request specific, actionable feedback: "Identify factual errors with corrections. Point out unsupported claims. List missing considerations."
- Convergence criteria: Without explicit stopping conditions, debate can loop indefinitely. Common criteria: maximum rounds (2-3), critic finds no issues rated above a severity threshold, or diminishing changes between revisions.
- Cost multiplier: Debate multiplies token cost by the number of agents and rounds. A 3-round proposer-critic debate costs roughly 4-6x a single generation. This is justified for high-stakes outputs but excessive for routine tasks.
- Sycophancy in critics: LLMs have a tendency toward agreement (sycophancy). Critic prompts must explicitly counteract this: "You will be evaluated on the errors you find, not on being agreeable. Assume there are errors and find them."
- Debate on reasoning chains: Applying debate to chain-of-thought reasoning (one agent proposes a reasoning chain, another critiques each step) is more effective than debating only the final answer, as it catches errors at the step where they occur.
- Asymmetric effort: The critic agent's task (finding flaws) is typically easier than the proposer's task (generating correct output). This asymmetry means the critic can often use a smaller, faster model without sacrificing quality.
Common Misconceptions
- "Debate catches all errors": When both agents share the same training data and biases, they may agree on incorrect information. Debate is effective for logical errors and inconsistencies but less effective for shared knowledge gaps (e.g., both agents might confidently state an incorrect "fact" from their training data).
- "More debate rounds always improve quality": Quality typically plateaus after 2-3 rounds. Additional rounds often produce nitpicking on style rather than substance, or agents start introducing new errors while fixing old ones.
- "Agent debate is the same as self-consistency": Self-consistency (sampling multiple answers from the same model with high temperature and taking the majority vote) is a single-agent technique. Debate involves structurally different roles (proposer vs. critic) with different prompts, producing more diverse and critical perspectives.
- "The critic is always right": Critics can make errors too — raising false concerns, misunderstanding the task, or being overly pedantic. The proposer or a judge agent must evaluate critique quality, not blindly accept all feedback.
- "Debate eliminates the need for human review": Debate improves but does not guarantee quality. For truly high-stakes outputs, debate reduces the human reviewer's burden by catching obvious issues but does not replace human judgment.
Connections to Other Concepts
multi-agent-architectures.md— Debate is one of the five core multi-agent architecture patterns, alongside pipeline, hierarchy, swarm, and blackboard.consensus-and-voting.md— Multi-agent panel evaluation is closely related to consensus mechanisms; both use multiple agents to improve reliability.role-based-specialization.md— The proposer and critic are role-specialized agents, each configured with distinct prompts and evaluation criteria.agent-delegation.md— A manager agent may delegate verification to a critic agent as part of a quality assurance workflow.inter-agent-communication.md— Debate requires structured communication protocols: the format for critiques, the rules for rebuttals, and the criteria for judgment.
Further Reading
- Du et al., "Improving Factuality and Reasoning in Language Models through Multiagent Debate" (2023) — Seminal paper demonstrating that multi-agent debate improves factual accuracy and mathematical reasoning over single-agent generation.
- Liang et al., "Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate" (2023) — Shows that debate produces more diverse and creative solutions by forcing agents to consider alternative perspectives.
- Khan et al., "Debating with More Persuasive LLMs Leads to More Truthful Answers" (2024) — Investigates how debate dynamics and agent capabilities affect the truthfulness of final outputs.
- Cohen et al., "LM vs LM: Detecting Factual Errors via Cross Examination" (2023) — Proposes cross-examination between models as a mechanism for detecting factual errors without access to ground truth.
- Irving et al., "AI Safety via Debate" (2018) — Foundational theoretical paper arguing that debate between AI systems can help align AI behavior with human values, even for superhuman AI.