One-Line Summary: Tree search explores multiple solution paths simultaneously, allowing agents to consider alternative actions like a chess player evaluating candidate moves, backtracking from dead ends, and selecting the most promising path forward.
Prerequisites: Task decomposition, chain-of-thought prompting, basic search algorithms (BFS, DFS, beam search)
What Is Tree Search and Branching?
Consider a chess player analyzing a position. They do not commit to the first move that looks reasonable. Instead, they mentally explore several candidate moves, think through the opponent's likely responses to each, evaluate the resulting positions, and only then choose the move that leads to the best projected outcome. If a line of play leads to a losing position, they backtrack and explore a different branch. This systematic exploration of possibilities is tree search.
For AI agents, tree search means generating multiple candidate actions at each decision point, evaluating the consequences of each, and selecting the best path rather than committing to the first plausible action. This is fundamentally different from the linear Thought-Action-Observation loop of ReAct, where the agent takes one path and hopes it works. Tree search acknowledges that the first idea is not always the best idea, and that exploring alternatives leads to better outcomes, especially for tasks with high error costs.
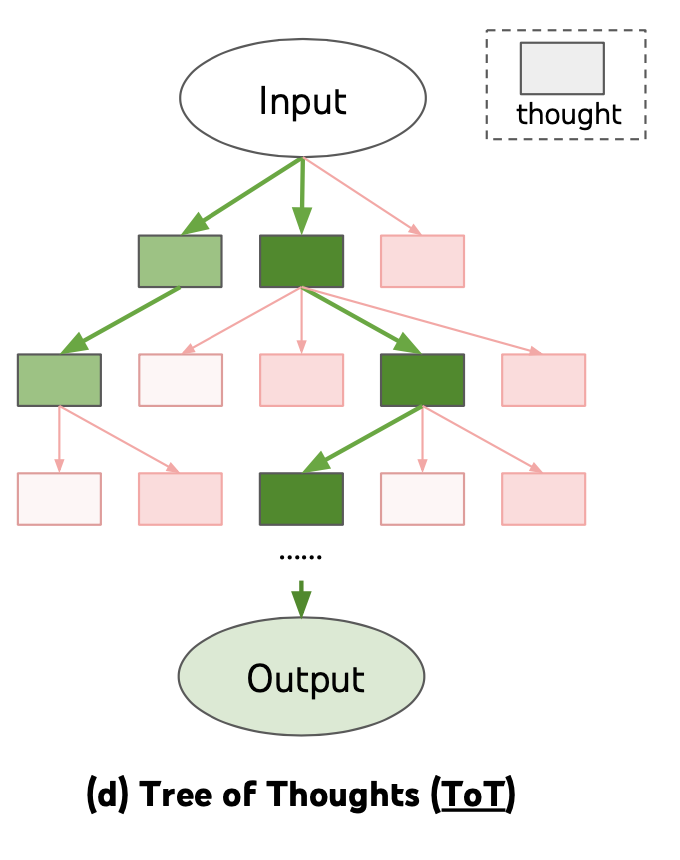 Source: Lilian Weng, "Prompt Engineering" (2023) — Tree of Thoughts explores multiple reasoning branches, evaluating each to find the optimal solution path.
Source: Lilian Weng, "Prompt Engineering" (2023) — Tree of Thoughts explores multiple reasoning branches, evaluating each to find the optimal solution path.
The Tree-of-Thought (ToT) framework, introduced by Yao et al. in 2023, formalized this approach for LLM-based reasoning. ToT structures the reasoning process as a tree where each node is a partial solution (a "thought"), and the agent uses search algorithms (BFS, DFS) to explore the tree, using the LLM itself as both the generator of candidate thoughts and the evaluator of their promise.
How It Works
Tree Structure
The tree is defined by three components:
- Nodes: Each node represents a partial solution state. For a writing task, a node might be a paragraph outline. For a math problem, a node might be an intermediate equation. For an agent task, a node might be the state of the environment after a sequence of actions.
- Branching: At each node, the agent generates k candidate next steps (typically k=3-5). Each candidate becomes a child node.
- Evaluation: Each node is scored by a value function (often the LLM itself, prompted to evaluate "how promising is this partial solution on a scale of 1-10?"). Scores guide which branches to explore further.
Search Algorithms
Breadth-First Search (BFS): Explore all nodes at depth d before moving to depth d+1. At each level, generate k candidates per node, evaluate all of them, and keep the top-b (beam width) nodes. This is equivalent to beam search and is the most common approach.
Level 0: [Initial state]
Level 1: [Candidate A (score 8), Candidate B (score 6), Candidate C (score 9)]
Keep top-2: [A, C]
Level 2: [A1 (7), A2 (5), C1 (9), C2 (8)]
Keep top-2: [C1, C2]
Level 3: [C1a (10), C1b (6), C2a (8), C2b (7)]
Select: C1aDepth-First Search (DFS): Explore one branch fully before backtracking. Generate k candidates, evaluate them, and pursue the most promising one to completion. If the branch fails (score drops below threshold), backtrack to the last branching point and try the next-best candidate.
Monte Carlo Tree Search (MCTS): Combines tree search with random rollouts. At each node, simulate several random completions, use the average outcome to estimate the node's value, and use UCB (Upper Confidence Bound) to balance exploration vs exploitation. More computationally expensive but better at finding globally optimal paths.
Beam Search Over Action Sequences
For agents that take actions in an environment, beam search maintains b parallel "beams" — each beam is a complete action history from the start. At each step:
- For each beam, generate k candidate next actions
- Execute each candidate action (or simulate it using a world model)
- Score the resulting states
- Keep the top-b beams across all candidates
- Continue until a beam reaches the goal or max depth is reached
This is expensive (b * k action evaluations per step) but dramatically improves success rates on tasks where the first action attempt often fails.
Backtracking
Backtracking is the mechanism that makes tree search resilient. When the agent detects that the current path is failing (tool returns an error, intermediate result is clearly wrong, evaluation score drops), it abandons the current branch and returns to the last decision point with remaining unexplored alternatives. This requires maintaining a stack of decision points and their unexplored children.
Why It Matters
Overcomes Greedy Failures
Linear agents (ReAct, basic Plan-and-Execute) are greedy: they commit to each action without considering alternatives. This works when the action space is forgiving, but fails catastrophically when early mistakes compound. Tree search lets the agent recover from suboptimal early decisions by maintaining alternatives.
Enables Systematic Problem Solving
For tasks like mathematical reasoning, code generation, and strategic planning, the optimal solution often requires non-obvious intermediate steps. Tree search enables the agent to discover these steps by systematically exploring the solution space rather than relying on the model's greedy sampling.
Provides Confidence Through Comparison
When multiple branches converge on the same answer, confidence is higher. When branches disagree, the agent knows the task is ambiguous and can request clarification. This self-consistency check is a natural byproduct of tree search.
Key Technical Details
- Branching factor (k): Typically 3-5 candidates per node; higher k increases coverage but multiplies computational cost
- Beam width (b): Typically 2-5 parallel paths; b=1 degenerates to greedy search, b>5 rarely provides additional benefit
- Evaluation methods: LLM self-evaluation ("rate this solution 1-10"), majority voting across branches, or task-specific heuristics
- Cost multiplier: Tree search costs roughly b * k * d times more than linear execution, where d is the search depth. A beam-3, branch-5, depth-4 search costs ~60x a single linear pass
- Tree-of-Thought results: On the Game of 24 task, ToT with BFS achieved 74% success vs 4% for standard prompting and 49% for CoT (Yao et al., 2023)
- Pruning strategies: Prune branches with evaluation scores below a threshold (absolute pruning) or below a percentage of the best branch (relative pruning) to reduce cost
- State representation: For environmental agents, each node must store the full environment state or a diff from the parent node to enable backtracking
Common Misconceptions
-
"Tree search is always better than linear reasoning." The computational cost of tree search is multiplicative. For straightforward tasks where the greedy path usually works, tree search wastes resources exploring unnecessary alternatives. Reserve it for tasks where errors are costly or the solution is non-obvious.
-
"The LLM evaluator is reliable." LLM self-evaluation is noisy and biased. The same model that generated a flawed solution may rate it highly. Using a different model for evaluation, or using task-specific criteria, improves evaluation quality.
-
"More branching always helps." Beyond a certain branching factor, candidates become redundant (minor variations of the same idea) and evaluation noise dominates. Diminishing returns typically set in around k=5.
-
"Tree search requires explicit tree data structures." In practice, many tree search implementations use implicit trees where the "tree" is just the set of parallel prompts with different prefixes. The search is managed through prompt engineering rather than explicit tree construction.
Connections to Other Concepts
chain-of-thought-in-agents.md— Each branch in the tree is a chain-of-thought; tree search explores multiple chains simultaneously and selects the bestreact-pattern.md— ReAct follows a single path through the action space; tree search extends ReAct by maintaining multiple parallel ReAct tracesreflection-and-self-critique.md— Reflection can serve as the evaluation function in tree search, with the agent critiquing each branch to determine which to pursueworld-models.md— A world model enables simulated evaluation of branches without actually executing actions, reducing the cost of tree searcherror-detection-and-recovery.md— Backtracking is a form of error recovery; when the current branch is detected as failing, the agent recovers by switching to an alternative branch
Further Reading
- Yao, S., Yu, D., Zhao, J., et al. (2023). "Tree of Thoughts: Deliberate Problem Solving with Large Language Models." The foundational paper on structured tree search for LLM reasoning.
- Hao, S., Gu, Y., Ma, H., et al. (2023). "Reasoning with Language Model is Planning with World Model." Connects LLM reasoning to classical planning through MCTS-style search.
- Xie, Y., Kawaguchi, K., Zhao, Y., et al. (2023). "Self-Evaluation Guided Beam Search for Reasoning." Demonstrates beam search with LLM self-evaluation for multi-step reasoning tasks.
- Browne, C., Powley, E., Whitehouse, D., et al. (2012). "A Survey of Monte Carlo Tree Search Methods." Comprehensive survey of MCTS algorithms that provides the theoretical foundation for tree search in agent systems.