One-Line Summary: Reflection enables agents to evaluate their own outputs and actions after the fact, learn from mistakes through verbal self-critique, and improve performance on subsequent attempts without weight updates.
Prerequisites: ReAct pattern, episodic memory basics, chain-of-thought prompting
What Is Reflection and Self-Critique?
Imagine a student who takes a practice exam, gets several questions wrong, and then sits down to analyze their mistakes: "I got question 5 wrong because I confused velocity with acceleration. Next time, I need to pay attention to whether the question asks about rate of change or rate of rate of change." The student does not need to re-read the entire textbook; they just need to identify specific failure modes and store those lessons for future reference. This self-analysis, conducted after an attempt, is reflection.
For AI agents, reflection is the process of evaluating completed actions or task attempts, identifying what went wrong (or what went right), and generating explicit verbal lessons that are stored in memory to improve future attempts. The Reflexion architecture, introduced by Shinn et al. in 2023, formalized this into a loop: the agent attempts a task, an evaluator scores the attempt, the agent reflects on the score to produce a natural language critique, and this critique is stored and provided as context for the next attempt.
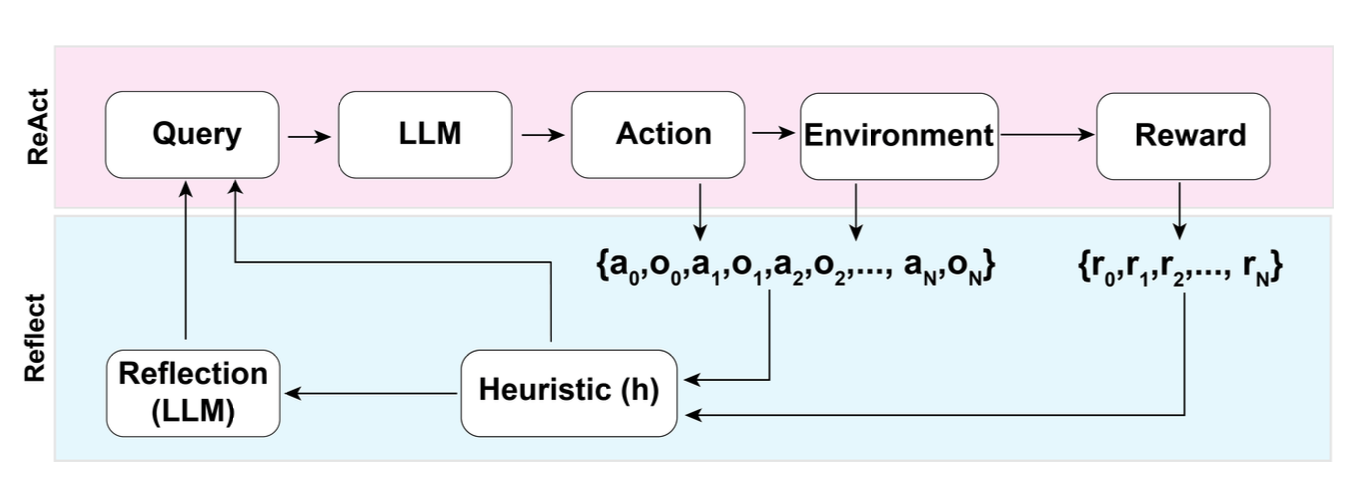 Source: Lilian Weng, "LLM Powered Autonomous Agents" (2023) — The Reflexion loop: the actor attempts a task, the evaluator scores it, self-reflection generates lessons, and memory stores them for the next attempt.
Source: Lilian Weng, "LLM Powered Autonomous Agents" (2023) — The Reflexion loop: the actor attempts a task, the evaluator scores it, self-reflection generates lessons, and memory stores them for the next attempt.
The power of reflection is that it enables learning within a single conversation or task session without any gradient updates or fine-tuning. The "learning" happens through natural language: the agent writes down what it learned, and this text biases future behavior. This is verbal reinforcement learning: rewards and punishments are expressed as words rather than scalar signals.
How It Works
The Reflexion Architecture
Shinn et al. (2023) defined four components:
- Actor: The agent that takes actions in the environment (typically a ReAct-style agent). It receives the task description plus any prior reflections as input.
- Evaluator: A function that scores the Actor's trajectory. This can be an exact-match checker, a unit test suite, an LLM judge, or any signal that indicates success or failure.
- Self-Reflection: When the Evaluator indicates failure, the Self-Reflection module generates a natural language analysis of what went wrong and what to do differently. This is typically a separate LLM call with a prompt like: "The previous attempt failed. Here is the trajectory: [trajectory]. Analyze what went wrong and provide specific advice for the next attempt."
- Memory: The reflection text is stored in a memory buffer and provided to the Actor on subsequent attempts. This allows the Actor to avoid repeating mistakes.
The Reflection Loop
Attempt 1:
Actor executes task -> Evaluator scores (fail)
Self-Reflection: "I searched for the wrong entity. The question asks about
the author of the book, not the book itself. Next time, extract the author
name first."
Store reflection in memory.
Attempt 2:
Actor receives: task + reflection from attempt 1
Actor executes task (adjusting based on reflection) -> Evaluator scores (fail)
Self-Reflection: "I found the correct author but searched for their birth
year instead of their death year. Next time, read the question more carefully."
Store reflection in memory.
Attempt 3:
Actor receives: task + reflections from attempts 1 and 2
Actor executes task -> Evaluator scores (pass)Types of Self-Critique
Outcome-based critique: "The final answer was wrong. The correct answer was X, but I said Y." Simple but only available when ground truth is known.
Process-based critique: "In step 3, I assumed the API would return results sorted by date, but it returned them sorted by relevance. This caused me to use the wrong data point in step 5." More informative because it identifies the specific failure point.
Strategy-based critique: "My overall approach of searching then synthesizing was fine, but I should have verified the source before using it. Next time, cross-reference any factual claim with a second source." Most general and applicable across tasks.
Inline Reflection (Without Full Retry)
Not all reflection requires restarting the entire task. Agents can reflect mid-task:
- After each action: "Did that action achieve what I intended?"
- At checkpoints: "Am I on track to complete the overall goal?"
- When stuck: "Why am I not making progress? What should I try differently?"
This lightweight reflection prevents errors from compounding without the cost of restarting.
Why It Matters
Dramatically Improves Multi-Attempt Success
Reflexion improved success rates on HumanEval (code generation) from 80% to 91% over multiple attempts. On HotpotQA, it improved from 57% to 77%. The gains come specifically from avoiding repeated mistakes: the reflection memory acts as a per-task learning signal.
Enables Learning Without Fine-Tuning
Traditional ML requires gradient updates to learn from mistakes. Reflection achieves a form of learning through in-context conditioning: the agent "learns" by reading its own prior analyses. This is faster, cheaper, and does not require access to model weights.
Makes Agent Behavior Self-Correcting
In production systems, reflection creates a feedback loop where agents improve over the course of a session. If an agent encounters an unusual API error, its reflection ("this API returns 429 when rate-limited; wait 30 seconds before retrying") can inform all subsequent interactions within the session.
Key Technical Details
- Reflexion paper results: 91% pass@1 on HumanEval (vs 80% baseline), 77% on HotpotQA (vs 57% baseline), 75% on AlfWorld (vs 22% baseline) over 3-5 attempts
- Maximum useful attempts: Performance typically plateaus after 3-5 attempts; beyond that, reflections become repetitive or contradictory
- Reflection prompt template: "You are an expert analyst. The previous attempt at [task] failed. Trajectory: [trajectory]. Score: [score]. Analyze what went wrong and provide 2-3 specific, actionable suggestions for the next attempt."
- Memory management: Store only the most recent 3-5 reflections to avoid context window overflow; older reflections can be summarized
- Cost of reflection: Each reflection adds ~300-800 tokens to context; each retry costs the full execution cost. Total cost for 3 attempts is roughly 3x single attempt + reflection overhead
- Evaluator quality matters: Reflection is only as good as the evaluator's signal. A binary pass/fail evaluator produces less useful reflections than a detailed rubric-based evaluator
- Reflection can be wrong: The agent may misdiagnose the failure cause. Incorrect reflections can degrade subsequent attempts. Mitigate by keeping reflections tentative ("I think the issue was...") rather than absolute
Common Misconceptions
-
"Reflection is the same as chain-of-thought." CoT happens before or during action, guiding the current step. Reflection happens after action, evaluating what already occurred. They serve different purposes: CoT is prospective reasoning, reflection is retrospective analysis.
-
"More reflection is always better." Excessive reflection wastes tokens and can lead to overthinking, where the agent becomes so cautious from prior reflections that it fails to act decisively. 2-3 specific reflections are more useful than 10 vague ones.
-
"Reflection requires ground-truth feedback." While exact-match evaluators are ideal, reflection also works with LLM-based evaluation, heuristic scoring, or even self-evaluation. The quality degrades with noisier evaluators, but the pattern still provides value.
-
"Reflection replaces planning." Reflection is backward-looking (learning from past mistakes), while planning is forward-looking (deciding future actions). They are complementary: plan before acting, reflect after acting.
Connections to Other Concepts
react-pattern.md— The Actor in Reflexion typically uses a ReAct-style loop; reflection wraps around the entire ReAct execution to enable multi-attempt improvementepisodic-memory.md— Reflections are a form of episodic memory: "In a previous attempt at this type of task, I learned that..." Stored reflections inform future behaviorerror-detection-and-recovery.md— Reflection is a sophisticated form of error recovery that goes beyond simple retry by analyzing why the error occurredmetacognition.md— Reflection is a specific form of metacognition: thinking about one's own thinking process to identify and correct failure modeschain-of-thought-in-agents.md— CoT within the agent loop provides the raw reasoning traces that reflection later analyzes for errors and improvements
Further Reading
- Shinn, N., Cassano, F., Gopinath, A., et al. (2023). "Reflexion: Language Agents with Verbal Reinforcement Learning." NeurIPS 2023. The foundational paper on the Reflexion architecture.
- Madaan, A., Tandon, N., Gupta, P., et al. (2023). "Self-Refine: Iterative Refinement with Self-Feedback." Demonstrates iterative self-improvement without external evaluators.
- Kim, G., Baldi, P., McAleer, S. (2023). "Language Models can Solve Computer Tasks." Uses reflection-like mechanisms for GUI agents that learn from failed interactions.
- Paul, D., Ismayilzada, M., Peyrard, M., et al. (2023). "REFINER: Reasoning Feedback on Intermediate Representations." Provides fine-grained feedback on intermediate reasoning steps rather than only final outcomes.