One-Line Summary: ReAct interleaves chain-of-thought reasoning with concrete actions, enabling agents to think about what to do, do it, observe the result, and adjust their reasoning accordingly.
Prerequisites: Chain-of-thought prompting, tool use basics, agent loop fundamentals
What Is ReAct?
Imagine a detective investigating a crime scene. They don't just blindly collect evidence (acting without thinking) or sit in an armchair theorizing (thinking without acting). Instead, they reason: "The window is broken from the outside, so the intruder likely entered here." Then they act: dust the windowsill for fingerprints. Then they observe: partial prints found, matching no one in the household. Then they reason again: "This suggests an outside intruder; I should check surveillance footage from neighboring buildings." This interleaving of reasoning and acting is exactly what ReAct does for AI agents.
ReAct (Reasoning + Acting) was introduced by Yao et al. in 2022 as a paradigm that combines the strengths of chain-of-thought reasoning with action-taking in an interleaved manner. Before ReAct, agents either reasoned in isolation (like chain-of-thought prompting for QA tasks) or acted without explicit reasoning traces (like traditional RL agents). ReAct unified these into a single loop where the language model generates both reasoning traces and actions in an alternating sequence.
The key insight is that reasoning helps the agent plan, track progress, and handle exceptions, while actions let the agent gather new information from external sources (search engines, APIs, databases) or affect the environment. Neither alone is sufficient for complex tasks: pure reasoning hallucinates facts, and pure acting lacks strategic direction.
 Source: Lilian Weng, "LLM Powered Autonomous Agents" (2023) — ReAct interleaves reasoning traces with actions, unlike act-only or reason-only approaches.
Source: Lilian Weng, "LLM Powered Autonomous Agents" (2023) — ReAct interleaves reasoning traces with actions, unlike act-only or reason-only approaches.
How It Works
The Thought-Action-Observation Loop
The core structure of ReAct is a repeating three-part cycle:
- Thought: The agent generates an internal reasoning trace. This is not sent to any external tool; it is the agent's private deliberation. Example: "I need to find the population of France as of 2023. Let me search for this."
- Action: The agent selects and invokes a tool with specific parameters. Example:
Search("population of France 2023") - Observation: The environment returns the result of the action. Example: "According to INSEE, the population of France was approximately 68.4 million in 2023."
The agent then generates another Thought based on the Observation, decides on the next Action, and continues until it reaches a final answer or a stopping condition.
Prompt Structure
A typical ReAct prompt includes few-shot examples that demonstrate the interleaved format:
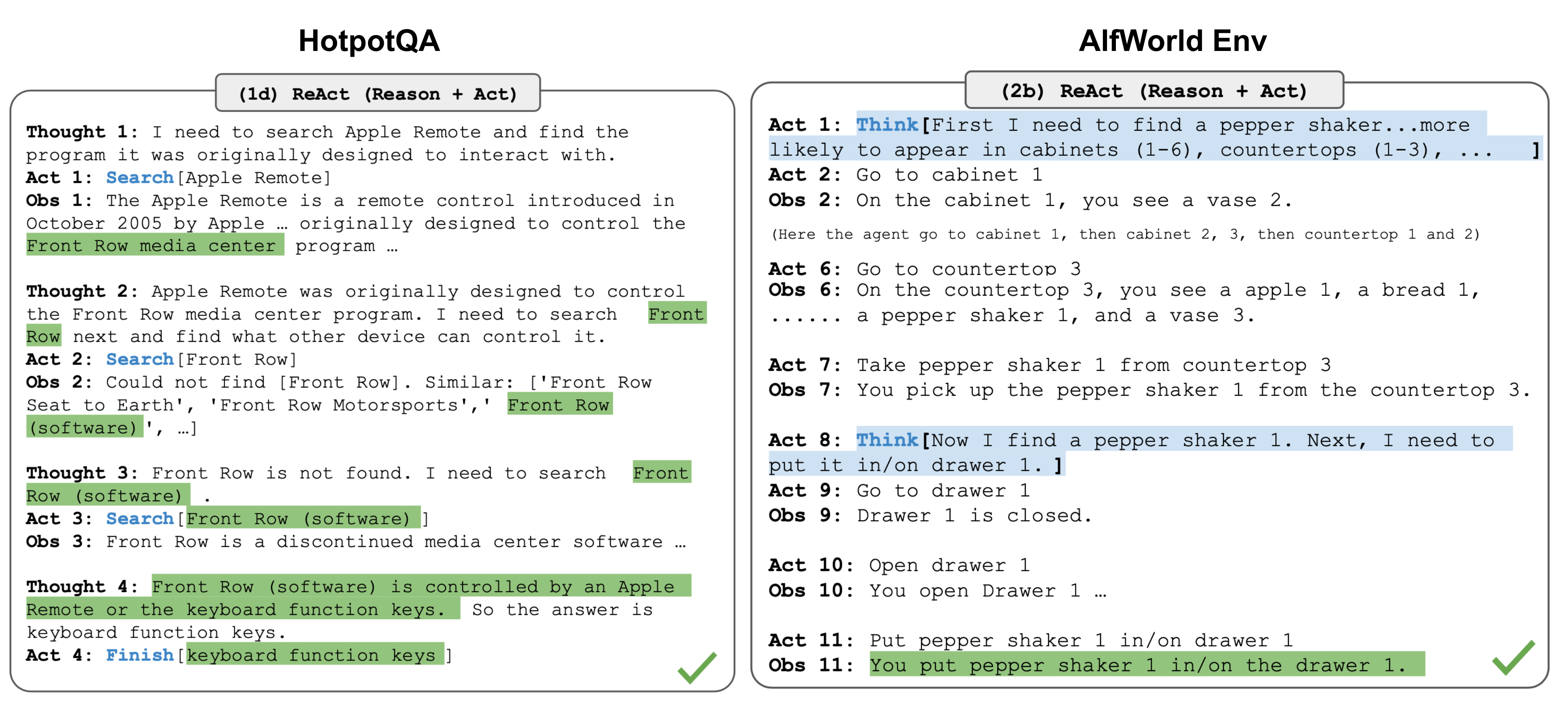
Question: What is the elevation range for the area that the eastern sector of the Colorado orogeny extends into?
Thought 1: I need to search Colorado orogeny, find the area that the eastern sector extends into, then find the elevation range of that area.
Action 1: Search[Colorado orogeny]
Observation 1: The Colorado orogeny was an episode of mountain building...the eastern sector extends into the High Plains.
Thought 2: The eastern sector extends into the High Plains. I need to search High Plains and find its elevation range.
Action 2: Search[High Plains]
Observation 2: High Plains refers to one of the two distinct land regions...elevation from around 1,800 to 7,000 ft.
Thought 3: High Plains rise in elevation from around 1,800 to 7,000 ft, so the answer is 1,800 to 7,000 ft.
Action 3: Finish[1,800 to 7,000 ft]When to Use ReAct vs Other Patterns
ReAct is best suited for tasks that require grounded reasoning with external information retrieval: multi-hop question answering, fact-checking, interactive decision-making. Use ReAct when:
- The task requires combining information from multiple sources
- The agent needs to adaptively decide what to look up based on prior findings
- Reasoning without evidence is likely to produce hallucinations
Prefer Plan-and-Execute over ReAct when the full plan can be specified upfront and steps are relatively independent. Prefer pure chain-of-thought when the task is purely analytical and requires no external data. Prefer Tree-of-Thought when exploring multiple solution paths is more important than sequential grounding.
Implementation Details
In practice, ReAct is implemented by formatting the agent's output into parseable segments. The framework (LangChain, LlamaIndex, or custom code) parses the agent's text output to extract the action name and parameters, executes the action, and appends the observation back into the context. The cycle continues until the agent emits a terminal action (e.g., Finish[answer]) or a maximum iteration count is reached.
Modern implementations often use structured output (JSON mode) rather than free-text parsing to make action extraction more reliable. The Thought step may also be implemented as a system-level "thinking" block that is not visible to the user.
Why It Matters
Grounding Reduces Hallucination
By forcing the agent to gather real evidence before drawing conclusions, ReAct dramatically reduces confabulation. In the original paper, ReAct outperformed chain-of-thought alone on knowledge-intensive tasks like HotpotQA because it retrieved actual facts rather than relying on parametric memory.
Interpretability and Debuggability
The explicit Thought traces make it possible to understand why an agent took a particular action. When an agent goes wrong, you can read the reasoning trace to identify where the logic broke down. This is invaluable for debugging and building trust in agent systems.
Foundation for Modern Agent Architectures
Nearly every major agent framework (LangChain, AutoGPT, Claude's tool use) has internalized the ReAct pattern as a default. Understanding ReAct is foundational to understanding how modern agents work, even when the framework abstracts away the explicit Thought-Action-Observation labels.
Key Technical Details
- Original paper: "ReAct: Synergizing Reasoning and Acting in Language Models" by Yao et al. (2022), published at ICLR 2023
- Typical iteration count: Most tasks resolve in 3-7 iterations; a hard cap of 10-15 is common to prevent infinite loops
- Action space: ReAct works with any discrete action space (search, lookup, calculate, code execution) but requires each action to return a text observation
- Token overhead: Each iteration adds ~200-500 tokens to the context (thought + action + observation), so context window management is critical for long traces
- Failure mode: "Reasoning ruts" where the agent repeats the same thought-action pattern without making progress; mitigated by reflection or iteration limits
- Performance on HotpotQA: ReAct achieved 35.6% exact match with PaLM-540B vs 29.4% for act-only and 33.0% for CoT-only
- Synergy with fine-tuning: ReAct traces can be used as training data to fine-tune smaller models to follow the pattern without few-shot prompting
Common Misconceptions
-
"ReAct is just chain-of-thought with tools." While related, the key difference is the interleaving. In CoT+tools, reasoning happens first and then a single tool call is made. In ReAct, reasoning and acting alternate repeatedly, allowing each reasoning step to be informed by the latest observation.
-
"The Thought step must be visible to the user." The Thought is an internal reasoning trace. Many production systems hide it from the end user and only expose the final answer. The Thought exists for the model's benefit, not the user's.
-
"ReAct always outperforms pure reasoning." On tasks that require no external information (e.g., mathematical proofs, logical puzzles), pure chain-of-thought can match or exceed ReAct because the action-observation overhead adds noise and token cost.
-
"More iterations always lead to better results." After a certain point, additional iterations degrade performance due to context window pollution, compounding errors, and the model losing track of the original goal.
Connections to Other Concepts
chain-of-thought-in-agents.md— ReAct extends CoT by adding the Action and Observation steps; CoT is the reasoning backbone within each Thought stepplan-and-execute.md— Plan-and-Execute separates planning from execution, while ReAct interleaves them; hybrid approaches plan first, then use ReAct for each stepreflection-and-self-critique.md— Reflexion builds on ReAct by adding an explicit self-evaluation step after task completion, storing reflections for future attemptserror-detection-and-recovery.md— When a ReAct observation indicates failure, the agent must detect this and adjust; error recovery patterns apply directly within the ReAct loopshort-term-context-memory.md— The growing trace of Thoughts, Actions, and Observations consumes context window space, making memory management critical for long ReAct chains
Further Reading
- Yao, S., Zhao, J., Yu, D., et al. (2022). "ReAct: Synergizing Reasoning and Acting in Language Models." ICLR 2023. The foundational paper introducing the interleaved reasoning-acting paradigm.
- Wei, J., Wang, X., Schuurmans, D., et al. (2022). "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models." NeurIPS 2022. The CoT paper that ReAct builds upon.
- Shinn, N., Cassano, F., Gopinath, A., et al. (2023). "Reflexion: Language Agents with Verbal Reinforcement Learning." NeurIPS 2023. Extends ReAct with self-reflection and episodic memory.
- Significant Gravitas. (2023). "AutoGPT." Open-source project that popularized ReAct-style loops in autonomous agent systems.