One-Line Summary: The agent loop is the observe-think-act cycle that drives all AI agent behavior — a repeated process where the agent perceives its environment, reasons about the next step, executes an action, and feeds the result back into the next iteration.
Prerequisites: what-is-an-ai-agent.md
What Is the Agent Loop?
Think of a chef preparing a complex meal without a rigid recipe. They taste the sauce (observe), decide it needs more salt (think), add salt and stir (act), then taste again (observe). This cycle repeats — sometimes dozens of times — until the dish meets their standard. The chef does not plan every micro-action in advance; they respond to feedback at each step. An AI agent operates identically: it loops through observe-think-act until the task is done.
The agent loop is the runtime mechanism that transforms a stateless LLM into a persistent, goal-directed system. In a single-shot interaction, you send the LLM a prompt and receive a response — one input, one output, done. In an agent loop, the LLM is called repeatedly. After each call, the system checks whether the LLM wants to take an action (call a tool), and if so, it executes that action, appends the result to the conversation, and calls the LLM again. This continues until the LLM produces a final response without requesting any action, or until an external termination condition is triggered.
The loop is conceptually simple but operationally nuanced. The quality of an agent depends not just on the LLM's reasoning ability but on how well the loop manages context, handles errors, enforces safety guardrails, and decides when to stop. A poorly designed loop can produce agents that spin endlessly, lose track of their goal, or burn through tokens without making progress.
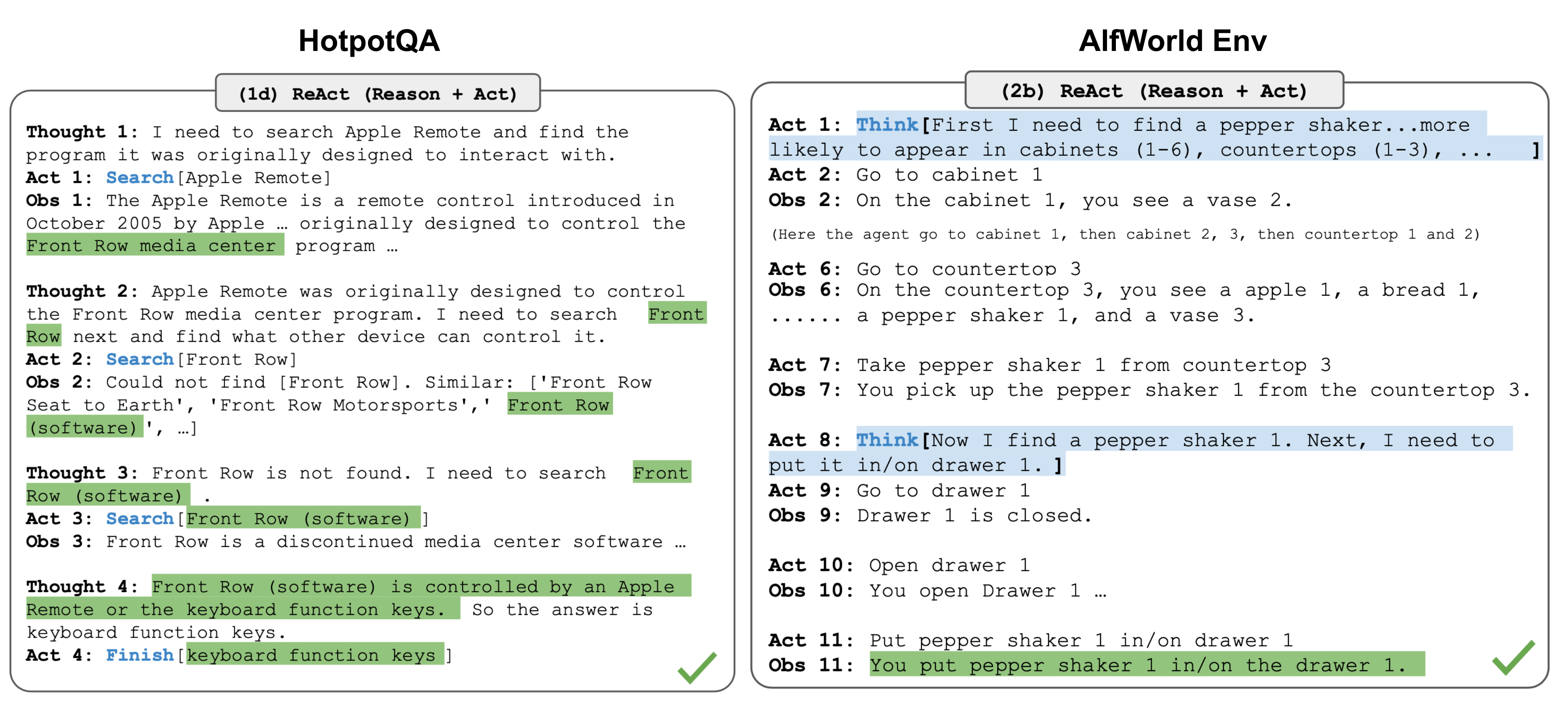 Source: Lilian Weng, "LLM Powered Autonomous Agents" (2023) — The ReAct loop illustrates the core observe-think-act cycle that underpins all agent loops.
Source: Lilian Weng, "LLM Powered Autonomous Agents" (2023) — The ReAct loop illustrates the core observe-think-act cycle that underpins all agent loops.
How It Works
The Core Cycle
The agent loop can be expressed in pseudocode:
messages = [system_prompt, user_message]
for step in range(max_steps):
response = llm.generate(messages)
if response.has_tool_calls():
for tool_call in response.tool_calls:
result = execute_tool(tool_call)
messages.append(tool_call)
messages.append(tool_result(result))
else:
return response.text # Final answer, loop ends
raise MaxStepsExceededEach iteration involves: (1) sending the accumulated message history to the LLM, (2) parsing the response for tool calls, (3) executing any requested tools, (4) appending results to the history, and (5) repeating. The loop terminates when the LLM responds with text only (no tool calls), signaling it considers the task complete.
Termination Conditions
Knowing when to stop is as important as knowing what to do. Agent loops use multiple termination conditions:
- Goal achieved: The LLM generates a final response without tool calls, indicating it believes the task is complete. This is the normal exit path.
- Max steps: A hard limit (e.g., 50-200 iterations) prevents runaway loops. Production systems like Claude Code enforce turn limits to prevent infinite loops and unbounded cost.
- Max tokens: A budget cap on total tokens consumed (input + output across all turns). This prevents a single task from consuming excessive API costs.
- Error threshold: If the agent encounters N consecutive errors (e.g., 3-5 failed tool calls), it may halt and report the issue rather than continuing to fail.
- Human intervention: The user can interrupt the loop at any point to redirect, correct, or cancel the agent's work.
- Safety guardrails: Certain actions (deleting critical files, accessing unauthorized systems) may trigger automatic halts.
Context Accumulation and Management
With each loop iteration, the message history grows. A tool call adds the LLM's reasoning, the tool call itself, and the tool's result — often 500-3,000 tokens per iteration. Over 30 iterations, the context can grow by 15,000-90,000 tokens. This creates pressure on the context window.
Strategies for managing context growth include:
- Truncation: Removing or summarizing old tool results that are no longer relevant.
- Sliding window: Keeping only the most recent N turns in full detail.
- Summarization: Periodically asking the LLM to summarize progress so far, then replacing detailed history with the summary.
- Selective inclusion: Only including tool results that are directly relevant to the current reasoning step.
Error Recovery Within the Loop
Agents encounter errors frequently — a file does not exist, a command returns an error, a search yields no results. The loop structure naturally supports recovery: the error becomes an observation, the LLM reasons about it, and it tries a different approach. This is one of the key advantages of the loop architecture over single-shot prompting.
A well-designed agent will:
- Interpret the error message to understand what went wrong.
- Consider alternative approaches (different tool, different parameters, different strategy).
- Retry with the adjusted approach.
- Escalate to the user if multiple retries fail.
Empirically, agents recover from first-attempt errors roughly 60-80% of the time through this natural retry mechanism.
Why It Matters
Emergent Problem-Solving
The loop structure enables a form of trial-and-error problem-solving that no single LLM call can achieve. When an agent encounters unexpected data, a broken API, or a file in an unexpected format, it can adapt in real time. This adaptability is what makes agents useful for real-world tasks where conditions are rarely exactly as expected.
Composability of Simple Steps
Individual loop iterations are simple: read a file, run a search, edit a line. But composed across 20, 50, or 100 iterations, these simple steps accomplish complex objectives — refactoring a module, debugging a production issue, writing and testing a feature. The loop is the mechanism that converts simple capabilities into complex outcomes.
Feedback-Driven Refinement
Unlike a pipeline that executes a fixed sequence of steps, the agent loop allows the agent to check its own work. After making an edit, it can run tests. After running tests, it can read the failures. After reading failures, it can fix the code. This closed-loop feedback is essential for tasks where correctness must be verified.
Key Technical Details
- Typical loop iterations per task: Simple tasks complete in 3-8 iterations. Moderate tasks require 10-30. Complex tasks (multi-file refactoring, debugging) may require 50-150 iterations.
- Latency per iteration: Each iteration takes 1-10 seconds depending on LLM inference time (0.5-5s) plus tool execution time (0.1-5s). A 30-iteration task takes roughly 1-5 minutes wall-clock time.
- Token cost growth: Context grows roughly linearly with iterations. At ~2,000 tokens per iteration, a 50-iteration task consumes approximately 50 * 50,000 = 2.5M total tokens (summing each turn's full context), costing 25 at typical API rates.
- Parallel tool calls: Some frameworks support executing multiple tool calls within a single iteration, reducing total loop count. For example, reading 5 files in parallel rather than sequentially cuts 5 iterations to 1.
- Max step defaults: Claude Code uses dynamic limits based on subscription tier. Cursor defaults to around 25 tool calls per interaction. LangGraph allows custom configuration.
- Context window pressure: At 128K tokens, an agent has roughly 40-80 iterations before context management becomes necessary (assuming 1,500-3,000 tokens per iteration).
- Streaming within iterations: Modern agent runtimes stream the LLM's reasoning tokens to the user in real time, providing visibility into the agent's thought process before the tool call is executed.
Common Misconceptions
"The agent plans all steps upfront and then executes them." Most agents do not create a complete plan and then execute it sequentially. They plan one or a few steps ahead, execute, observe results, and replan. Some architectures (like plan-then-execute) do create upfront plans, but even these typically replan when execution diverges from expectations.
"More loop iterations always means better results." There is a clear point of diminishing returns. After roughly 50-100 iterations on a single task, agents tend to start looping unproductively — revisiting the same approaches, making contradictory changes, or losing coherence. Effective agents solve most tasks in under 30 iterations.
"The loop runs until the LLM says 'I'm done.'" While the LLM's decision to stop calling tools is one termination condition, it is not the only one and not always the most important. Max-step limits, token budgets, error thresholds, and human interrupts all serve as essential safety nets. Relying solely on the LLM to know when to stop is risky.
"Each iteration is independent." Each iteration depends on the full accumulated context from all previous iterations. The LLM does not have memory between calls — it relies entirely on the message history passed to it. This makes context management a first-class concern in loop design.
Connections to Other Concepts
what-is-an-ai-agent.md— The agent loop is the operational mechanism that makes an AI agent an agent rather than a chatbot.agent-state-management.md— State management determines what information persists across loop iterations and how context is structured.determinism-vs-stochasticity.md— The loop amplifies stochasticity: small variations in one iteration can compound across subsequent iterations.environment-and-observations.md— The "observe" phase of the loop involves processing environmental inputs, which is covered in depth there.action-space-design.md— The "act" phase is constrained by the available action space (tools) designed for the agent.
Further Reading
- Yao et al., "ReAct: Synergizing Reasoning and Acting in Language Models" (2023) — Formalizes the interleaved reasoning-and-acting loop pattern that underlies most modern agents.
- Anthropic, "Building Effective Agents" (2024) — Practical guidance on loop design, including when to use simple loops vs. more complex orchestration patterns.
- Significant Gravitas, "AutoGPT: An Autonomous GPT-4 Experiment" (2023) — One of the earliest open-source implementations of a fully autonomous agent loop, illustrating both the power and the failure modes of unconstrained loops.
- Xi et al., "The Rise and Potential of Large Language Model Based Agents: A Survey" (2023) — Comprehensive survey covering loop architectures, planning methods, and evaluation of agent systems.