One-Line Summary: Structured reasoning formats provide explicit templates -- such as OTA, Given-Find-Solution, and Claim-Evidence-Reasoning -- that guide the model's reasoning into a predictable, task-appropriate structure.
Prerequisites: 03-reasoning-elicitation/chain-of-thought-prompting.md, 02-core-prompting-techniques/few-shot-prompting.md
What Is Structured Reasoning?
Imagine you need to fill out a form. A tax return asks for very different information in a very different structure than a job application. Each form is designed for a specific purpose: the structure itself guides you to provide the right information in the right order. Structured reasoning formats work the same way for LLMs: instead of the open-ended instruction "think step by step," you provide a specific template that matches the type of reasoning the task requires. The template constrains the model's generation to follow a productive path, reducing the chance of irrelevant tangents, missing steps, or disorganized reasoning.
While chain-of-thought prompting lets the model choose its own reasoning structure, structured reasoning formats impose a specific structure chosen by the prompt designer. This trade-off -- less flexibility, more reliability -- is often worthwhile in production systems where consistency and predictability matter. Different formats suit different task types: OTA (Observation-Thought-Action) is ideal for interactive decision-making, Given-Find-Solution works for well-defined problem-solving, Claim-Evidence-Reasoning suits analytical arguments, and STAR (Situation-Task-Action-Result) fits retrospective analysis and case studies.
The key insight is that reasoning format is a design choice, not a one-size-fits-all decision. Selecting the right format for the task can improve both the quality of reasoning and the usability of the output.
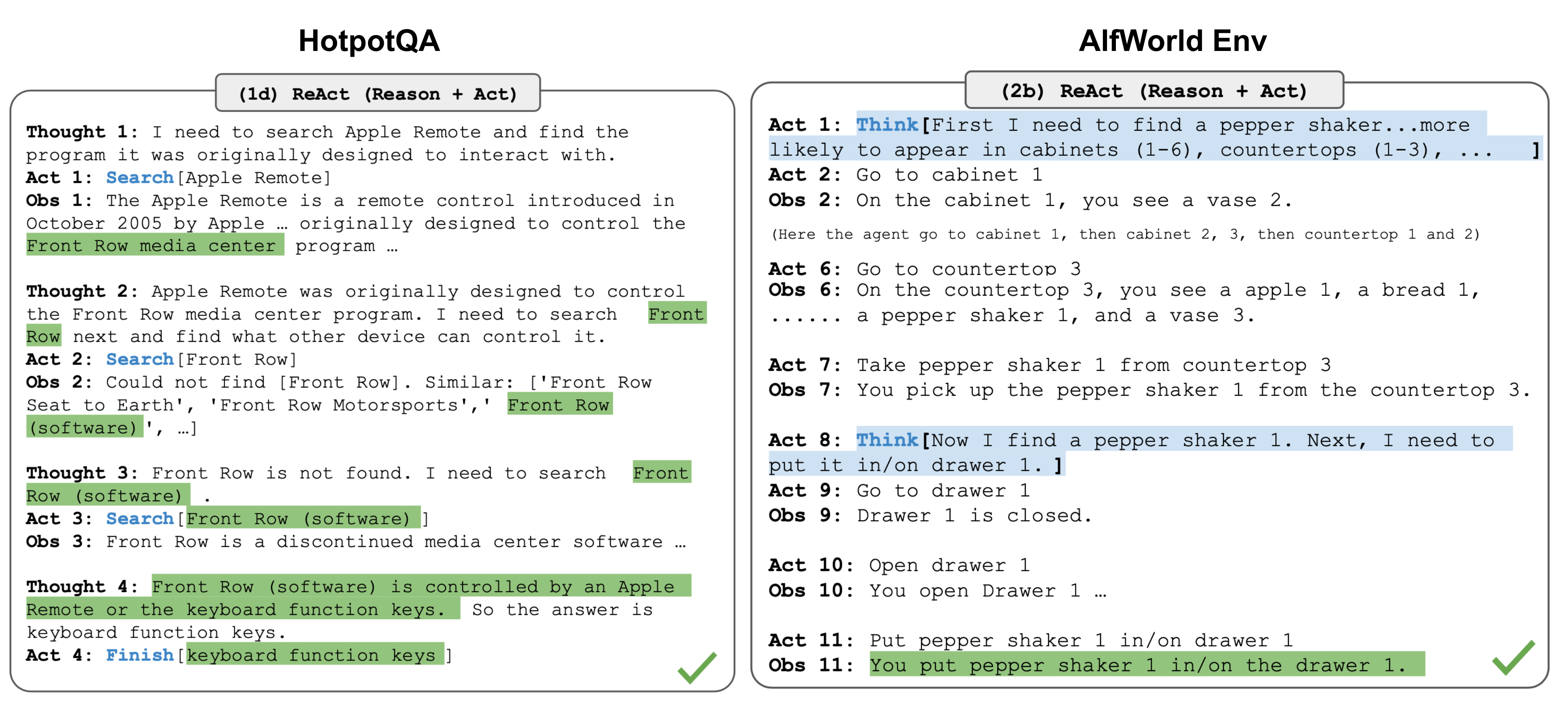 Source: Lilian Weng, "LLM Powered Autonomous Agents," lilianweng.github.io, 2023. The OTA/ReAct format is the dominant structured reasoning pattern for agent systems.
Source: Lilian Weng, "LLM Powered Autonomous Agents," lilianweng.github.io, 2023. The OTA/ReAct format is the dominant structured reasoning pattern for agent systems.
flowchart TD
R1["format selection decision tree"]
C2["Interactive/tool use?"]
R1 --> C2
C3["Well-defined problem with clear inputs?"]
R1 --> C3
C4["Analytical argument or evaluation?"]
R1 --> C4
C5["Retrospective analysis or case study?"]
R1 --> C5Source: Adapted from Yao et al., "ReAct: Synergizing Reasoning and Acting in Language Models," ICLR 2023, and Madaan et al., "Self-Refine," NeurIPS 2023.
How It Works
OTA: Observation-Thought-Action
The OTA (also called ReAct) format structures reasoning as a cycle of three phases. The model first states its Observation (what it sees, what information is available), then articulates a Thought (interpretation, analysis, planning), and finally declares an Action (what to do next, what to output, or what tool to call).
This cycle can repeat multiple times, creating an iterative loop of observe-think-act that mirrors how humans interact with complex environments. OTA is ideal for tasks involving interaction with environments, tool use, or iterative problem-solving.
It was popularized by the ReAct framework (Yao et al., 2023) and is the dominant format for LLM agent systems. Example applications: web browsing agents, code debugging, multi-step data analysis.
Given-Find-Solution
This format, drawn from physics and engineering education, structures reasoning into three explicit phases: Given (list all known information and constraints), Find (state what needs to be determined), and Solution (work through the steps to get from given to find).
This format is particularly effective for well-defined problems with clear inputs and outputs. It forces the model to explicitly inventory available information before attempting to solve, reducing errors from overlooked constraints or misunderstood problem statements.
Best suited for: math word problems, physics problems, engineering calculations, financial analysis, and any task where the inputs and desired outputs are clearly specifiable.
Claim-Evidence-Reasoning (CER)
CER structures analytical output into three components: Claim (the assertion or conclusion), Evidence (specific data, quotes, or facts supporting the claim), and Reasoning (the logical connection between evidence and claim).
This format is valuable for analytical tasks, argument evaluation, and research synthesis. It forces the model to separate its conclusions from its supporting evidence, making outputs more auditable and reducing unsupported assertions.
Best suited for: research analysis, policy evaluation, literature review, debate preparation, and any task where the distinction between claims and their supporting evidence matters.
STAR: Situation-Task-Action-Result
STAR organizes retrospective analysis into four phases: Situation (context and background), Task (specific challenge or objective), Action (what was done), and Result (outcome and impact).
Originally developed for behavioral interview responses, STAR works well for case studies, post-mortem analyses, project summaries, and experience documentation.
It ensures that context, intention, execution, and outcome are all addressed, which is particularly valuable when any one of these tends to be omitted in unstructured narratives. The Result section is especially important because models (and humans) frequently describe what they did without reporting whether it worked.
Why It Matters
Consistency in Production
Unstructured chain-of-thought produces highly variable output formats. One response may start with the conclusion, another with background, a third with a tangent. Structured formats guarantee a predictable output structure, which simplifies downstream parsing, reduces the need for output reformatting, and makes quality assurance more systematic.
Task-Appropriate Reasoning
Different tasks have different reasoning requirements. Using OTA for a math problem is awkward; using Given-Find-Solution for an agent task is inappropriate. Matching the format to the task ensures the model allocates its reasoning tokens to the right cognitive operations. Format selection is a form of reasoning architecture design.
Reduced Omission Errors
Structured formats function as checklists. The Given-Find-Solution format ensures the model does not skip the step of inventorying known information. CER ensures that claims are accompanied by evidence. STAR ensures that outcomes are reported alongside actions. Without these structural guardrails, the model may omit critical reasoning steps, especially under context pressure or with complex inputs.
Teachability and Team Alignment
Structured formats create a shared vocabulary for prompt design across teams. When everyone uses OTA for agent tasks and CER for analytical outputs, prompt reviews become more efficient, quality standards are clearer, and new team members can learn the patterns faster. The format functions as both a reasoning aid and a communication protocol.
Key Technical Details
- Format compliance: Modern instruction-tuned models (GPT-4, Claude 3.5+) follow structured formats with 85-95% compliance when the format is clearly specified with headers and few-shot examples.
- Few-shot examples: 2-3 examples demonstrating the target format typically achieve high compliance; 1 example may be insufficient for complex formats like OTA.
- Token overhead: Structured formats increase output length by 20-50% compared to unstructured responses due to explicit section headers and comprehensive coverage, but the additional tokens carry more useful information.
- ReAct (OTA) performance: The original ReAct paper showed 5-10% improvement on HotpotQA and Fever benchmarks compared to chain-of-thought alone.
- Parsing reliability: Structured formats with clear section delimiters (### Given, ### Find, ### Solution) improve programmatic output parsing reliability from ~70% to ~95%.
- Format mixing: Formats can be composed -- e.g., OTA where each Thought phase uses CER internally, or Given-Find-Solution where the Solution phase uses step-by-step CoT.
- Diminishing returns: Over-specified formats with too many sections (7+) can reduce compliance and quality as the model struggles to fill each section meaningfully.
- Custom format design: The most effective formats are task-specific hybrids. For code review, an effective custom format might be: Issue-Location-Severity-Fix. For incident response: Timeline-Impact-Root Cause-Remediation.
- Format enforcement: Combining structured reasoning format instructions with output schema validation (e.g., JSON schema) ensures both reasoning quality and parsing reliability.
Common Misconceptions
-
"One reasoning format works for all tasks." Each format embodies assumptions about the task structure. OTA assumes iterative interaction, Given-Find-Solution assumes well-defined problems, CER assumes argumentative analysis. Using the wrong format for a task produces awkward, low-quality reasoning.
-
"Structured formats restrict the model's reasoning ability." Good formats channel reasoning into productive paths without eliminating flexibility within each section. The model can still reason freely within the "Thought" section of OTA or the "Solution" section of Given-Find-Solution.
-
"The model will automatically follow any format you describe." Complex or ambiguous format specifications often produce partial compliance. Clear section headers, explicit field descriptions, and 2-3 examples are usually necessary for reliable format adherence.
-
"More structure is always better." Over-structured formats with many required fields can lead to filler content where the model generates text to satisfy the format rather than to advance the reasoning. The optimal format has enough structure to guide reasoning but not so much that it becomes a bureaucratic exercise.
-
"Structured reasoning formats are only for output formatting." The format shapes the reasoning process itself, not just the output presentation. A model using Given-Find-Solution genuinely inventories information before solving; it does not just present a pre-computed answer in a structured wrapper.
Connections to Other Concepts
03-reasoning-elicitation/chain-of-thought-prompting.md-- CoT is the unstructured predecessor; structured formats impose specific organization on the reasoning trace that CoT leaves open-ended.03-reasoning-elicitation/zero-shot-chain-of-thought.md-- Zero-shot-CoT's "think step by step" can be replaced with format-specific instructions like "Use the Given-Find-Solution format" for more structured zero-shot reasoning.03-reasoning-elicitation/self-ask-and-decomposition.md-- Self-ask is itself a structured format (Follow-up / Intermediate Answer). The formats in this document provide alternative structures for different task types.04-system-prompts-and-instruction-design/system-prompt-anatomy.md-- Structured reasoning formats are typically specified in the system prompt as part of the output format component.03-reasoning-elicitation/step-back-prompting.md-- Given-Find-Solution naturally incorporates a step-back phase (the "Given" section) where the model surveys the problem before solving.
Further Reading
- Yao, S., Zhao, J., Yu, D., et al. (2023). "ReAct: Synergizing Reasoning and Acting in Language Models." ICLR 2023. Introduced the OTA/ReAct format for interleaving reasoning with tool use, demonstrating improved performance on QA and interactive tasks.
- Madaan, A., Tandon, N., Gupta, P., et al. (2023). "Self-Refine: Iterative Refinement with Self-Feedback." NeurIPS 2023. Explores structured iterative improvement formats where the model generates, critiques, and refines its own output.
- Shinn, N., Cassano, F., Gopinath, A., et al. (2023). "Reflexion: Language Agents with Verbal Reinforcement Learning." NeurIPS 2023. Uses a structured Observation-Reflection-Action format that extends OTA with explicit self-reflection.
- Wang, L., Xu, W., Lan, Y., et al. (2023). "Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models." Demonstrates that structured planning formats improve zero-shot reasoning across multiple benchmarks.