One-Line Summary: Understanding the four-stage pipeline — tokenization, embedding, attention, and generation — reveals why word choice, ordering, and structure mechanically alter LLM outputs.
Prerequisites: what-is-a-prompt.md.
What Is Prompt Processing?
Imagine a translator reading a document written in a foreign language. They do not process the text letter by letter. Instead, they chunk the text into meaningful phrases (tokenization), map those phrases to concepts they know (embedding), consider how each phrase relates to every other phrase and the broader context (attention), and then produce their translation one word at a time, each word influenced by everything they have read and written so far (generation). If you rearrange the paragraphs of the source document, the translator's interpretation shifts — even if the raw information is identical.
An LLM processes your prompt through a similar pipeline, but with mathematical precision. Your text is broken into tokens (subword units), each token is converted into a high-dimensional vector (embedding), these vectors interact through layers of self-attention (the model's "reading" mechanism), and the output is generated one token at a time using probability distributions. Every prompt engineering technique — from few-shot examples to chain-of-thought — works by manipulating what happens at one or more of these stages.
This is not academic trivia. When you understand that the model literally cannot "see" your prompt as a human would — that it processes tokens through attention patterns with specific biases and limitations — you make better decisions about how to structure your inputs.
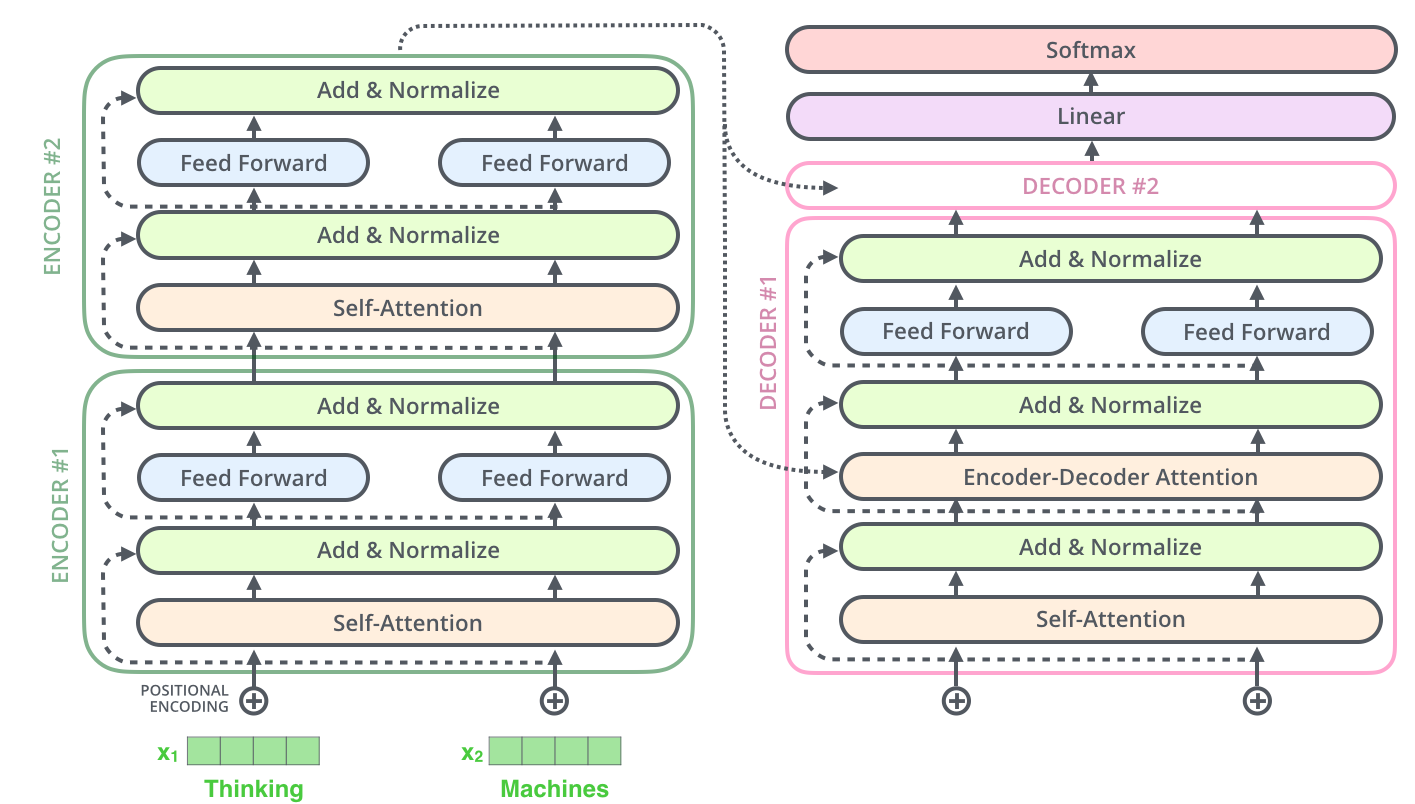 Source: Jay Alammar, "The Illustrated Transformer," jalammar.github.io, 2018.
Source: Jay Alammar, "The Illustrated Transformer," jalammar.github.io, 2018.
flowchart LR
S1["the sequential flow from raw text"]
S2["tokenization"]
S3["embedding"]
S4["multi-head attention"]
S5["autoregressive generation"]
S1 --> S2
S2 --> S3
S3 --> S4
S4 --> S5Source: Adapted from Vaswani et al., "Attention Is All You Need," 2017.
How It Works
Stage 1: Tokenization
The prompt string is split into tokens using a fixed vocabulary (typically 32K-100K+ tokens). The tokenizer is a deterministic algorithm, not a learned component — it runs before the neural network ever sees your input. GPT-4 uses cl100k_base (~100K vocab), Claude uses a similar BPE tokenizer. Common English words usually map to single tokens ("the" → 1 token), while uncommon terms get split ("tokenization" → "token" + "ization" = 2 tokens). This splitting affects everything downstream: the model's "understanding" operates on tokens, not words. A prompt that is 500 words might be 650-750 tokens in English, but the same content in Chinese could be 1,500-2,500 tokens due to character-level splitting.
Stage 2: Embedding
Each token ID is mapped to a dense vector (typically 4,096-12,288 dimensions in frontier models). These embeddings encode semantic meaning — tokens with similar meanings have vectors that are closer together in this high-dimensional space. Positional encodings are added so the model knows where each token sits in the sequence. This is why token position matters: "The cat sat on the mat" and "The mat sat on the cat" produce different embeddings despite containing identical tokens. The embedding layer is where the abstract concept of "word order matters" becomes concrete mathematics.
Stage 3: Attention
The embedded tokens pass through dozens to over a hundred transformer layers, each containing multi-head self-attention mechanisms. In each attention head, every token computes how much it should "attend to" every other token in the sequence. This is where the model builds its understanding of relationships, context, and meaning. A 128K context window means the attention mechanism must handle 128K x 128K potential pairwise interactions — which is why inference costs scale quadratically with context length (though optimizations like FlashAttention and KV-caching reduce practical costs). The key insight for prompt engineers: tokens at certain positions receive more attention than others, creating the primacy and recency biases documented in attention-and-position-effects.md.
Stage 4: Generation (Autoregressive Decoding)
The model generates output one token at a time. At each step, it produces a probability distribution over the entire vocabulary, and a sampling strategy (temperature, top-p, top-k) selects the next token. That token is appended to the sequence, and the entire attention computation incorporates it for the next step. This autoregressive nature means early output tokens influence later ones — if the model starts a response with "I'm not sure, but..." it is statistically more likely to hedge throughout. This is why assistant prefill (forcing the first few output tokens) is so effective: it sets the trajectory for the entire generation.
The Two Phases of Inference: Prefill and Decode
Understanding the processing pipeline also means understanding that inference happens in two distinct phases with different performance characteristics. During the prefill phase, all input tokens are processed in parallel through the transformer layers — this is fast because it can fully utilize GPU parallelism. The result is a populated KV-cache containing the attention states for every input token. During the decode phase, the model generates output tokens one at a time, each requiring a forward pass that reads the entire KV-cache. This is slower because it is memory-bandwidth-bound rather than compute-bound.
The practical consequence for prompt engineers: input tokens are cheap in latency (processed in parallel), but output tokens are expensive (generated sequentially). A 10,000-token prompt with a 100-token output may take less total time than a 1,000-token prompt with a 1,000-token output. This asymmetry means that providing detailed context in the prompt (to reduce required output length) can actually decrease overall latency — the opposite of the naive assumption that shorter prompts are always faster.
This two-phase split also explains why prompt caching (offered by Anthropic and OpenAI) is so effective. If the first 5,000 tokens of your prompt are identical across requests (a common system prompt), the provider can reuse the cached KV-cache from the prefill phase, skipping the most expensive computation. Prompt engineers who design stable prompt prefixes — placing variable content at the end — can reduce latency by 50-80% and cost by up to 90% on cached portions.
Why It Matters
Word Choice Has Mechanical Consequences
Because the model operates on tokens, not semantic meaning, the specific words you choose affect processing. "Utilize" and "use" may be near-synonyms to humans, but they produce different token embeddings that activate different attention patterns. More importantly, uncommon or technical terms may be split into multiple tokens, potentially diluting their semantic signal. Prompt engineers should prefer clear, common vocabulary unless domain-specific terms are necessary for precision.
Structure Shapes Attention Flow
The attention mechanism does not weight all parts of the prompt equally. Structured prompts — with clear section headers, delimiters, and logical ordering — create stronger attention signals between related pieces of information. An unstructured wall of text forces the model to discover structure through attention alone, which is less reliable. This is why XML tags, markdown headers, and numbered lists measurably improve task performance by 10-20%.
The multi-head architecture of self-attention is particularly relevant here. Different attention heads specialize in different relationship types — some track syntactic dependencies, others track semantic similarity, and some focus on positional proximity. When a prompt uses clear structural markers (like XML tags or numbered steps), these markers create unambiguous signals that multiple attention heads can latch onto, strengthening the connection between instructions and the content they reference. Without such markers, the model must infer structural relationships from semantic cues alone, which is inherently less reliable.
Generation Is Path-Dependent
Because each output token conditions the next, the model's first few tokens of output have outsized influence on the final result. A model that begins with "Let me think step by step:" will produce a different (often better-reasoned) response than one that begins with "The answer is:". This path dependency is the mechanical reason chain-of-thought prompting works — it is not just a psychological trick, it literally alters the token-by-token generation trajectory.
Key Technical Details
- Frontier models use vocabularies of 32K-100K+ tokens; each token typically represents 3-4 characters in English.
- Embedding dimensions range from 4,096 (smaller models) to 12,288+ (frontier models like GPT-4).
- Transformer depth ranges from 32 layers (7B models) to 120+ layers (frontier models), each containing multi-head attention.
- Attention complexity is theoretically O(n^2) with sequence length n, though practical implementations use optimizations like FlashAttention to reduce memory overhead.
- The KV-cache stores previously computed attention states, making each new generated token require only O(n) computation rather than reprocessing the full sequence.
- Generation speed (tokens/second) is primarily bottlenecked by memory bandwidth, not compute — this is why output is slower than input processing.
- Positional encoding schemes (RoPE, ALiBi) determine how well the model handles different sequence lengths, directly affecting long-context performance.
- Prompt caching can reduce prefill latency by 50-80% and cost by up to 90% on cached token portions, making stable prompt prefixes a meaningful optimization lever.
- The prefill phase processes all input tokens in parallel (compute-bound), while the decode phase generates one token at a time (memory-bandwidth-bound). This asymmetry means input tokens are significantly cheaper in latency than output tokens.
- Batch inference allows multiple prompts to share GPU resources during the decode phase, improving throughput by 2-8x compared to sequential processing — but individual request latency remains unchanged.
- Speculative decoding uses a smaller "draft" model to propose multiple tokens that the larger model verifies in parallel, potentially doubling generation speed for predictable output patterns like structured JSON or repetitive text.
- Quantization (reducing weight precision from 16-bit to 8-bit or 4-bit) trades model quality for speed and memory efficiency. 8-bit quantization typically preserves 95-99% of quality while halving memory requirements, making it relevant for prompt engineers who need to understand why smaller or quantized deployments may respond differently to the same prompt.
Common Misconceptions
"LLMs understand language the way humans do." LLMs process token sequences through matrix multiplications and attention patterns. They have no sensory grounding, no persistent memory, and no understanding in the human sense. Effective prompt engineering works with the model's actual mechanism, not an anthropomorphized version of it.
"The model reads the entire prompt simultaneously." While input tokens are processed in parallel during the prefill phase, the model's attention mechanism creates sequential dependencies. And during generation, the model is strictly sequential — each output token depends on all previous tokens.
"Longer prompts always give the model more to work with." Additional tokens increase noise alongside signal. The attention mechanism must distribute its capacity across all tokens, so irrelevant content actively competes for attention with relevant content. Studies show diminishing — and sometimes negative — returns past optimal prompt lengths for specific tasks.
"The model processes words, not tokens." The fundamental unit is the token, not the word. "Unhappiness" might be split into "un" + "happiness" or "unhapp" + "iness" depending on the tokenizer. This splitting can affect the model's ability to reason about morphology, negation, and compound concepts.
"All models process prompts the same way internally." While all transformer-based LLMs share the same high-level pipeline, implementation details vary significantly. Different models use different tokenizers (cl100k_base vs. SentencePiece variants), different positional encoding schemes (RoPE vs. ALiBi vs. learned positions), different numbers of attention heads, and different layer normalization strategies. These differences mean that the same prompt can be processed through substantially different computational paths across models, which is one reason prompt transfer between models is unreliable.
"Longer context windows mean the model 'remembers' everything equally." Even with 128K or 1M token context windows, the attention mechanism does not distribute focus uniformly. Research consistently shows a "lost in the middle" effect where information placed in the middle of long contexts receives less attention than information at the beginning or end. Effective prompt engineering for long contexts places the most critical information at the boundaries — the start and end of the prompt — rather than relying on the model to find buried details.
Connections to Other Concepts
tokenization-for-prompt-engineers.md— Deep dive into the first stage of the processing pipeline and its cost/quality implications.attention-and-position-effects.md— Explores the attention stage's biases and their actionable consequences for prompt layout.temperature-and-sampling.md— Covers the generation stage's sampling strategies that determine how probability distributions become actual tokens.context-window-mechanics.md— The physical constraint that bounds the entire processing pipeline.prefilling-and-output-priming.md— Exploits the path-dependent nature of autoregressive generation.
Further Reading
- Vaswani et al., "Attention Is All You Need," 2017. The foundational transformer architecture paper that defines the processing pipeline.
- Dao et al., "FlashAttention: Fast and Memory-Efficient Exact Attention," 2022. Key optimization that makes long-context processing practical.
- Olsson et al., "In-context Learning and Induction Heads," 2022. Mechanistic interpretability of how attention enables in-context learning.
- Elhage et al., "A Mathematical Framework for Transformer Circuits," Anthropic 2021. Technical deep dive into how transformer layers compose to process prompts.