One-Line Summary: Metacognitive prompting asks the model to reflect on its own knowledge, confidence, and reasoning quality, producing better-calibrated outputs that distinguish what the model knows from what it does not.
Prerequisites: 03-reasoning-elicitation/chain-of-thought-prompting.md, 01-foundations/how-llms-process-prompts.md
What Is Metacognitive Prompting?
Think of a student preparing for an exam. The most effective students are not necessarily those who know the most, but those who know what they do not know. They can accurately assess which topics they have mastered and which ones need more study. This self-awareness -- knowing what you know and knowing what you don't know -- is metacognition. Metacognitive prompting applies this principle to LLMs: instead of simply asking the model for an answer, you ask it to reflect on its confidence, identify gaps in its knowledge, and flag uncertainty before (or alongside) generating a response.
LLMs have a well-documented calibration problem. They generate text with uniform confidence regardless of whether the content is well-supported by training data or is a confabulation. A model will state a hallucinated fact with the same fluent, authoritative tone as a well-established one. Metacognitive prompting partially addresses this by explicitly asking the model to evaluate its own epistemic state. While LLMs cannot truly introspect on their neural computations, they can generate useful signals about the likely reliability of their outputs by drawing on patterns from their training data about which types of questions are typically uncertain.
The practical value is substantial: in production systems, knowing when the model is uncertain is often as valuable as the answer itself. An uncertain answer can be routed to a human reviewer, flagged for additional verification, or supplemented with retrieval. A confidently wrong answer is the most dangerous output; metacognitive prompting reduces its frequency.
flowchart TD
T1["known-unknown matrix 2x2 grid"]
subgraph ROW2[" "]
Q4["known-unknown matrix"]
Q5["Known"]
end
subgraph ROW3[" "]
Q6["Unknown"]
Q7["..."]
end
T1 --- ROW2
T1 --- ROW3Source: Adapted from the Rumsfeld matrix, applied to LLM epistemic states as described in Kadavath et al., "Language Models (Mostly) Know What They Know," Anthropic, 2022.
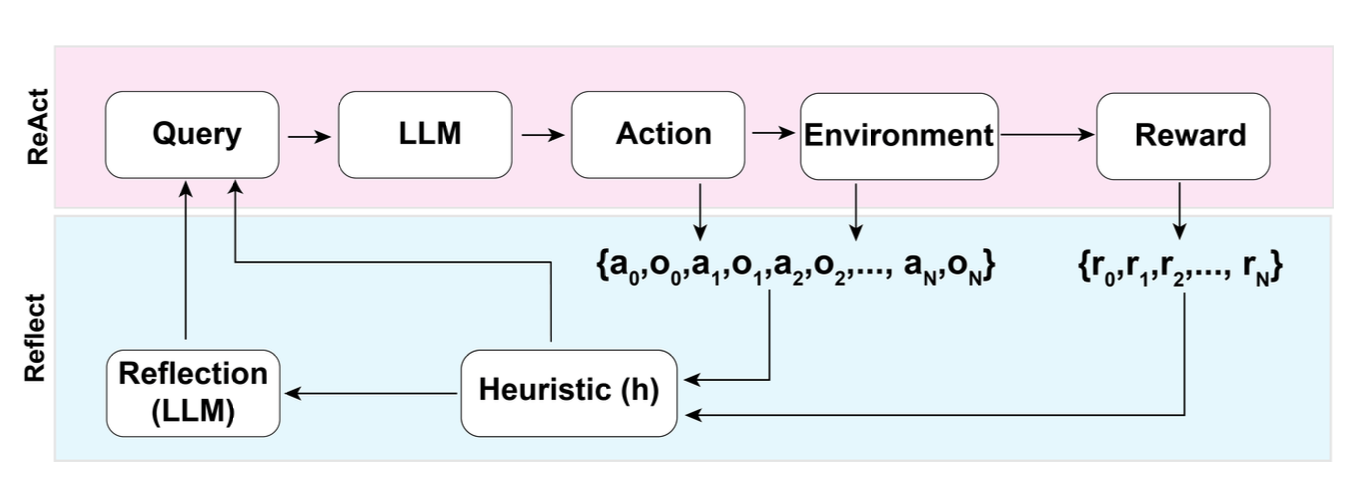 Source: Lilian Weng, "LLM Powered Autonomous Agents," lilianweng.github.io, 2023. The reflexion pattern demonstrates metacognitive self-evaluation where the model assesses its own performance and adjusts accordingly.
Source: Lilian Weng, "LLM Powered Autonomous Agents," lilianweng.github.io, 2023. The reflexion pattern demonstrates metacognitive self-evaluation where the model assesses its own performance and adjusts accordingly.
How It Works
Confidence Elicitation
The simplest metacognitive technique is to ask the model to rate its confidence. This can be done with a direct prompt: "Answer the following question. Then rate your confidence from 1 to 10, where 1 means you are guessing and 10 means you are certain."
Research shows that LLMs produce moderately calibrated confidence scores -- they are not perfectly calibrated, but their self-reported confidence does correlate with actual accuracy. High-confidence answers (8-10) are correct more often than low-confidence answers (1-3).
The correlation is imperfect (typical Brier scores of 0.15-0.25 for frontier models), but useful for triage and routing decisions in production systems.
The Known-Unknown Matrix
A more structured approach prompts the model to categorize its knowledge state explicitly:
- Known knowns: "What do I know for certain about this topic?"
- Known unknowns: "What aspects of this question am I uncertain about?"
- Unknown unknowns: "What might I be missing that I haven't considered?"
This framework forces the model to articulate the boundaries of its knowledge before answering. The "known unknowns" category is particularly valuable because it surfaces specific gaps that can be addressed through retrieval, clarification, or routing to a domain expert.
The "unknown unknowns" category is the hardest for the model to populate but the most valuable when it succeeds, as it surfaces blind spots that would otherwise remain invisible.
Epistemic Hedging Instructions
Rather than asking for a confidence score, you can instruct the model to embed uncertainty directly into its responses: "When you are uncertain, use phrases like 'I believe,' 'based on my training data,' or 'this is likely but I am not certain.' When you are confident, state facts directly." This produces more nuanced outputs than binary certain/uncertain labels. It also trains users to attend to hedging language as a signal of reliability.
Pre-Answer Reflection
A more advanced technique asks the model to reflect before answering: "Before answering, consider: (1) What information would you need to be completely sure of your answer? (2) What are the most likely ways your answer could be wrong? (3) Are there any assumptions you are making?"
This pre-answer reflection often improves answer quality because the model surfaces potential error modes and either avoids them or flags them explicitly.
Pre-answer reflection is particularly effective for questions where the model might conflate similar entities, confuse time periods, or apply a generally true rule to an exceptional case. The reflection step gives the model an opportunity to catch these errors before committing to an answer.
Why It Matters
Reducing Confident Hallucination
The most dangerous LLM failure mode is confident hallucination -- generating false information with no signals of uncertainty. Metacognitive prompting reduces this risk by creating a structured opportunity for the model to express doubt. While it does not eliminate hallucination, it shifts the distribution: more hallucinations are accompanied by uncertainty signals, making them catchable by downstream systems or human reviewers.
Enabling Reliability-Aware Systems
In production, metacognitive signals enable routing and escalation. A customer service system can route low-confidence answers to human agents. A research assistant can flag uncertain claims for source verification. A medical information system can require higher confidence thresholds for safety-critical questions. Without metacognitive signals, all outputs look equally reliable, and the system cannot make these discriminations.
Improving Calibration at Scale
Across many queries, metacognitive prompting improves aggregate calibration: the correlation between stated confidence and actual accuracy. This allows organizations to set meaningful confidence thresholds (e.g., "auto-approve responses with confidence >= 8, queue for review below 8") and track calibration metrics over time as models and prompts evolve.
User Trust Building
When an LLM appropriately hedges uncertain answers and confidently states well-grounded ones, users develop a more accurate mental model of the system's capabilities. This calibrated trust is healthier than either blind trust (leading to unverified acceptance of hallucinations) or excessive skepticism (leading to underutilization). Metacognitive prompting is a key enabler of appropriate human-AI trust calibration.
Key Technical Details
- Calibration quality: Frontier models (GPT-4, Claude 3.5+) show moderate calibration when asked for confidence scores, with typical rank correlations (Spearman's rho) of 0.3-0.5 between self-reported confidence and actual accuracy.
- Confidence scale: 1-10 numerical scales produce more granular signals than binary (certain/uncertain); 1-5 scales are a reasonable compromise between granularity and consistency.
- Pre-answer reflection: Asking the model to identify potential error modes before answering reduces hallucination rates by an estimated 10-20% on knowledge-intensive tasks.
- Verbalized uncertainty: Models that include hedging language in responses are rated as more trustworthy by users in human evaluation studies.
- Overconfidence bias: LLMs tend to be overconfident -- self-reported confidence is typically 10-20% higher than actual accuracy, meaning calibration corrections (e.g., treating a self-reported "8" as a "6.5") improve reliability.
- Task dependency: Metacognitive prompting is most useful for knowledge-intensive tasks (factual QA, analysis) and least useful for well-defined tasks (math, code) where the model either gets it right or clearly wrong.
- Prompt structure: Asking for confidence after the answer (post-hoc) produces different calibration than asking before or during reasoning. Post-hoc confidence benefits from the model having already processed the question.
- Calibration drift: Model confidence calibration can change with model updates, requiring periodic recalibration of thresholds and routing rules.
Common Misconceptions
-
"The model truly knows what it knows." LLMs do not have genuine self-awareness or introspective access to their parameters. When a model reports confidence, it is generating text that is likely given the prompt and its training data, not performing actual self-evaluation. The confidence signals are useful but should be treated as heuristic, not ground truth.
-
"Asking for confidence eliminates hallucination." A model can hallucinate and simultaneously report high confidence. Metacognitive prompting reduces the rate of confident hallucination but does not eliminate it. It is one layer of defense, not a complete solution.
-
"Low confidence means the answer is wrong." Low confidence means the model's generated text suggests uncertainty, which correlates with but does not determine incorrectness. Many low-confidence answers are correct; the model may express uncertainty about a fact that it actually has correct information about.
-
"Metacognitive prompting works equally across all domains." The quality of confidence signals varies by domain. The model tends to be better calibrated on domains well-represented in training data (common knowledge, popular topics) and poorly calibrated on niche or specialized domains.
-
"You should always ask for confidence scores." In applications where the output is creative or subjective (writing, brainstorming), confidence scores are meaningless. Metacognitive prompting is a tool for factual and analytical tasks, not for creative generation.
Connections to Other Concepts
03-reasoning-elicitation/chain-of-thought-prompting.md-- CoT makes reasoning visible; metacognitive prompting makes uncertainty visible. The two can be combined: "Think step by step, and note where you are uncertain."03-reasoning-elicitation/step-back-prompting.md-- Step-back prompting asks "what principle applies?" which is a form of metacognition about the problem structure. Metacognitive prompting goes further by asking about the model's own knowledge state.03-reasoning-elicitation/self-consistency.md-- Self-consistency provides a behavioral measure of uncertainty (how often do multiple samples agree?); metacognitive prompting provides a verbalized measure. The two can be compared and combined.03-reasoning-elicitation/self-ask-and-decomposition.md-- Self-ask can be augmented with metacognitive checks: "Do I have enough information to answer this sub-question, or should I flag it as uncertain?"04-system-prompts-and-instruction-design/behavioral-constraints-and-rules.md-- Metacognitive instructions ("admit when you don't know") are a form of behavioral constraint that shapes the model's output style.
Further Reading
- Kadavath, S., Conerly, T., Askell, A., et al. (2022). "Language Models (Mostly) Know What They Know." Anthropic. Demonstrates that LLMs have moderate self-knowledge about their own accuracy, providing the empirical foundation for metacognitive prompting.
- Lin, S., Hilton, J., & Evans, O. (2022). "Teaching Models to Express Their Uncertainty in Words." TMLR. Explores training and prompting methods for verbalized uncertainty, including calibration analysis.
- Xiong, M., Hu, Z., Lu, X., et al. (2024). "Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs." Large-scale evaluation of confidence elicitation methods and their calibration properties.
- Tian, K., Mitchell, E., Yao, H., et al. (2023). "Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models." Systematic study of prompting strategies for extracting well-calibrated confidence scores.