One-Line Summary: Self-ask prompting teaches the model to break complex questions into smaller sub-questions, answer each independently, and synthesize the results into a final answer.
Prerequisites: 03-reasoning-elicitation/chain-of-thought-prompting.md, 02-core-prompting-techniques/few-shot-prompting.md
What Is Self-Ask and Decomposition?
Imagine an investigator working a complex case. Instead of trying to solve the whole mystery at once, they break it into smaller leads: Who was at the scene? What was the motive? What does the forensic evidence show? Each lead is investigated independently, and the answers are synthesized into a coherent theory. Self-ask prompting works the same way: the model is trained (through few-shot examples) to generate explicit intermediate questions, answer each one, and then combine the sub-answers into a final response.
Introduced by Press et al. (2022), self-ask was designed to improve performance on multi-hop question answering -- questions that require chaining together multiple facts. For example, "What country is the birthplace of the director of the film Jaws?" requires three hops: (1) Who directed Jaws? Steven Spielberg. (2) Where was Steven Spielberg born? Cincinnati, Ohio. (3) What country is Cincinnati in? The United States. Standard prompting often fails on such questions because the model must perform all hops implicitly. Self-ask makes each hop explicit, allowing the model to focus on one retrieval or reasoning step at a time.
The technique is particularly powerful because it produces an auditable reasoning trace. Each sub-question and sub-answer is visible, making it easy to identify where reasoning went wrong. This transparency is valuable for debugging, for building trust in production systems, and for combining with external tools (such as search engines that can answer factual sub-questions).
flowchart LR
S1["Follow-up: Who directed Jaws?"]
S2["Intermediate answer: Steven Spielberg"]
S3["Follow-up: Where was Spielberg born?"]
S4["Intermediate answer: Cincinnati, Ohio"]
S5["Follow-up: What country is Cincinnati in?"]
S6["Final answer: United States"]
S1 --> S2
S2 --> S3
S3 --> S4
S4 --> S5
S5 --> S6Source: Adapted from Press et al., "Measuring and Narrowing the Compositionality Gap in Language Models," EMNLP Findings 2023.
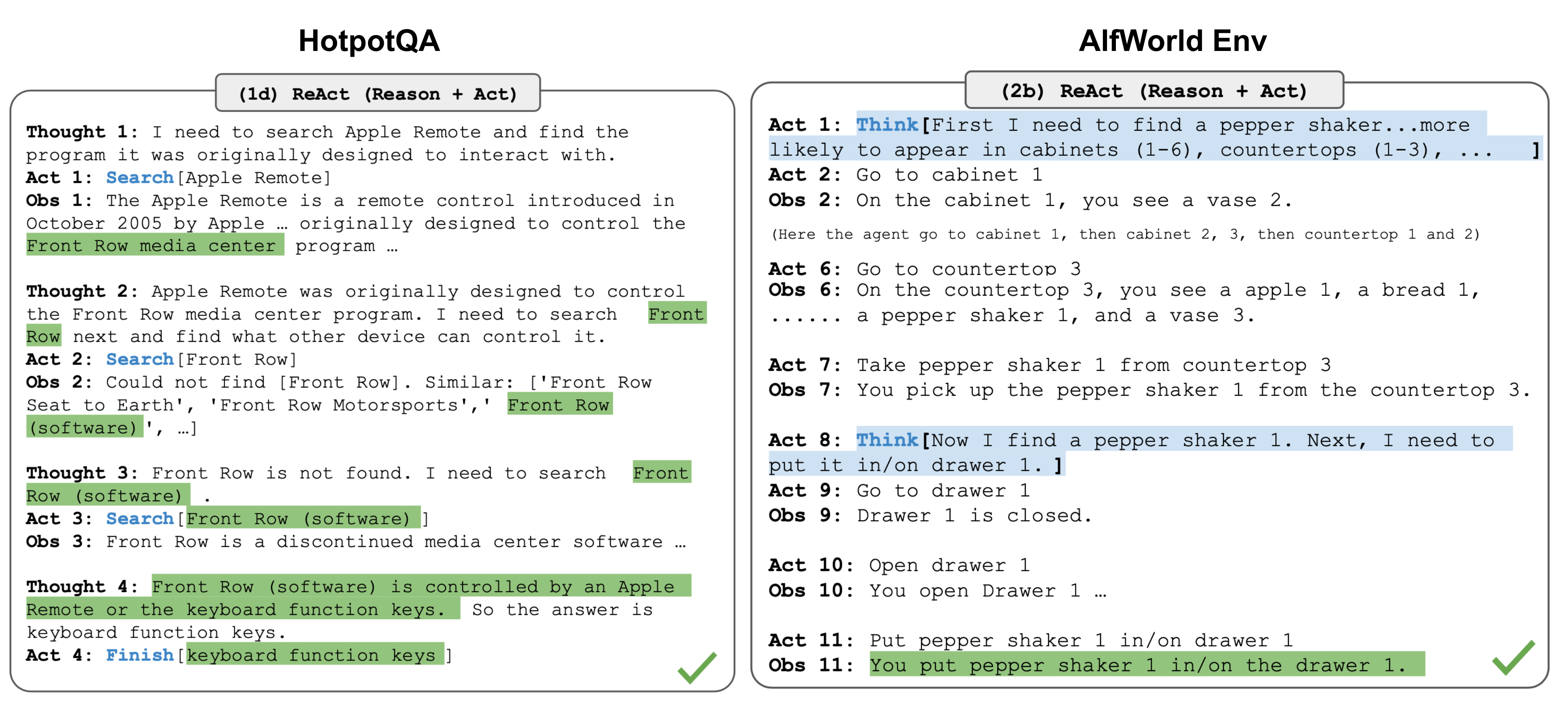 Source: Lilian Weng, "LLM Powered Autonomous Agents," lilianweng.github.io, 2023. The self-ask decomposition pattern parallels the ReAct approach of interleaving reasoning with information retrieval.
Source: Lilian Weng, "LLM Powered Autonomous Agents," lilianweng.github.io, 2023. The self-ask decomposition pattern parallels the ReAct approach of interleaving reasoning with information retrieval.
How It Works
The Self-Ask Pattern
In a self-ask prompt, the model generates text in a structured format:
- "Are follow-up questions needed here: Yes."
- "Follow-up: [sub-question 1]"
- "Intermediate answer: [answer to sub-question 1]"
- "Follow-up: [sub-question 2]"
- "Intermediate answer: [answer to sub-question 2]"
- "So the final answer is: [synthesized answer]"
This format is established through few-shot examples that demonstrate the full decomposition-and-synthesis pattern. The model learns to generate the "Follow-up:" prefix, which triggers sub-question generation, and the "Intermediate answer:" prefix, which triggers focused answering.
Single-Prompt vs. Multi-Call Decomposition
Self-ask can be implemented in two ways.
In the single-prompt version, the model generates all sub-questions and sub-answers within a single generation, as described above. This is simpler to implement but relies entirely on the model's own knowledge for sub-answers.
In the multi-call (agent) version, each sub-question is sent as a separate query -- potentially to a search engine, database, or different model -- and the sub-answer is injected back into the context before generating the next sub-question. The multi-call version is more accurate because it can ground sub-answers in external knowledge, reducing hallucination on factual sub-questions.
Decomposition Strategies
Not all decompositions are equally effective. Good decompositions have several properties: each sub-question should be independently answerable (no circular dependencies), the sub-questions should collectively cover all information needed for the final answer, and the sub-questions should be ordered so that earlier answers can inform later questions when dependencies exist. Poor decompositions break the problem into pieces that are too small (wasting tokens on trivial steps) or too large (not actually simplifying the problem). The few-shot examples play a critical role in teaching the model the appropriate granularity of decomposition.
Compositionality and Synthesis
The synthesis step -- combining sub-answers into a final answer -- is often the weakest link. The model must correctly identify how the sub-answers relate to the original question and combine them logically.
For simple multi-hop QA, synthesis is straightforward (the last sub-answer is often the final answer). For more complex questions requiring comparison, aggregation, or conditional logic, the synthesis step requires its own careful reasoning.
Including synthesis examples in the few-shot demonstrations is important for training the model to handle this step. The examples should show not just correct sub-question generation but also correct combination of sub-answers into a coherent final response.
Why It Matters
Multi-Hop Reasoning Improvement
Multi-hop QA is a common real-world pattern: "What are the environmental regulations in the country where our largest supplier is headquartered?" requires multiple retrieval and reasoning steps. Self-ask provides a structured framework for handling these queries reliably. Press et al. showed improvements of 10-15% on multi-hop benchmarks (Bamboogle, Musique) compared to standard chain-of-thought.
Debuggability and Transparency
Because each sub-question and sub-answer is explicitly generated, self-ask produces reasoning traces that are easy to audit. If the final answer is wrong, you can inspect each intermediate step to find the error. This is significantly more actionable than inspecting a dense chain-of-thought trace where reasoning steps may be implicit or interleaved.
Integration with External Tools
The self-ask decomposition pattern is a natural interface for tool-augmented LLMs. Each sub-question can be routed to the most appropriate tool: factual questions to a search engine, mathematical questions to a calculator, database questions to a SQL engine. This makes self-ask a foundational pattern for retrieval-augmented generation (RAG) and agent architectures.
Compositionality Gap Diagnosis
Press et al. identified the "compositionality gap" -- the phenomenon where a model can answer each sub-question correctly in isolation but fails to compose the sub-answers into a correct final answer. Self-ask makes this gap visible and addressable. By decomposing multi-hop questions, practitioners can diagnose whether failures are due to individual fact retrieval or to the composition step, enabling targeted fixes for each failure mode.
Key Technical Details
- Benchmark results: 10-15% improvement on multi-hop QA benchmarks (Bamboogle, Musique) compared to standard CoT with PaLM and GPT-3.
- Few-shot examples: 3-5 examples demonstrating the full decomposition-synthesis pattern typically suffice to establish the self-ask format.
- Sub-question count: Most multi-hop questions decompose into 2-4 sub-questions; generating more than 5-6 sub-questions often indicates over-decomposition.
- Token overhead: Self-ask generates 2-4x more tokens than direct answering due to the explicit sub-questions and intermediate answers.
- Tool integration: The multi-call version with search engine grounding improves factual accuracy by 15-25% compared to the single-prompt version on knowledge-intensive questions.
- Format sensitivity: The specific format markers ("Follow-up:", "Intermediate answer:") are important; the model adheres to the decomposition pattern more reliably with these structured markers.
- Failure modes: The most common failure is generating sub-questions that do not actually help answer the original question (irrelevant decomposition) or hallucinating intermediate answers to factual sub-questions.
- Compositionality gap: Even when all sub-answers are correct, the model may fail to synthesize them correctly. Press et al. measured a compositionality gap of 20-40% on multi-hop QA, meaning models answered sub-questions correctly but composed incorrectly that fraction of the time.
Common Misconceptions
-
"Self-ask is the same as chain-of-thought." CoT generates a linear reasoning narrative. Self-ask generates explicit questions and answers in a structured format. The distinction matters: self-ask's sub-questions can be independently verified or routed to external tools, while CoT's reasoning steps are embedded in prose.
-
"The model always decomposes correctly." The model can generate irrelevant sub-questions, miss critical sub-questions, or decompose at the wrong granularity. The quality of few-shot examples is the primary lever for improving decomposition quality.
-
"Self-ask only works for factual multi-hop questions." While it was designed for multi-hop QA, the decomposition pattern applies broadly: complex analysis tasks, planning problems, and multi-criteria evaluation tasks all benefit from explicit sub-question generation.
-
"More sub-questions means better accuracy." Over-decomposition wastes tokens, introduces unnecessary intermediate steps where errors can occur, and can cause the model to lose track of the original question. The ideal decomposition matches the actual complexity of the problem.
Connections to Other Concepts
03-reasoning-elicitation/chain-of-thought-prompting.md-- CoT generates linear reasoning traces; self-ask generates structured question-answer pairs. Self-ask can be seen as a more structured variant of CoT for decomposable problems.03-reasoning-elicitation/tree-of-thought-prompting.md-- ToT explores multiple reasoning branches; self-ask decomposes into sequential sub-questions. The two techniques address different problem structures (exploration vs. decomposition).03-reasoning-elicitation/step-back-prompting.md-- Step-back asks for principles before solving; self-ask asks for sub-questions before answering. Both are "think before solving" strategies but operate on different axes.03-reasoning-elicitation/metacognitive-prompting.md-- Self-ask demonstrates a form of metacognition: the model reflects on what it needs to know before attempting to answer.03-reasoning-elicitation/structured-reasoning-formats.md-- Self-ask's question-answer format is a specific instance of structured reasoning; other formats (OTA, Given-Find-Solution) provide alternative structures.
Further Reading
- Press, O., Zhang, M., Min, S., et al. (2022). "Measuring and Narrowing the Compositionality Gap in Language Models." EMNLP Findings 2023. The foundational paper introducing self-ask and the compositionality gap concept.
- Khot, T., Trivedi, H., Finlayson, M., et al. (2023). "Decomposed Prompting: A Modular Approach for Solving Complex Tasks." ICLR 2023. Extends decomposition beyond QA to general task solving with modular sub-task handlers.
- Dua, D., Gupta, S., Singh, S., & Gardner, M. (2022). "Successive Prompting for Decomposing Complex Questions." ACL 2022. An alternative decomposition approach that iteratively prompts for the next sub-question.
- Trivedi, H., Balasubramanian, N., Khot, T., & Sabharwal, A. (2023). "Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions." Combines self-ask-style decomposition with retrieval at each step.