One-Line Summary: GPT-2 (Radford et al., 2019) scaled the GPT-1 architecture to 1.5 billion parameters, demonstrated zero-shot task performance without any fine-tuning, sparked the first major AI safety debate with its "too dangerous to release" rollout, and established the scaling hypothesis that larger models develop qualitatively new capabilities.
Prerequisites: 02-gpt-1.md, 03-bert.md
What Is GPT-2?
Imagine a student who has read so much — millions of web pages, thousands of books, endless articles — that when you give them a test on a subject they've never explicitly studied, they can still produce reasonable answers just by drawing on everything they've absorbed. You don't need to teach them the specific format of the test; their broad knowledge is sufficient to figure out what's being asked and how to respond. GPT-2 was this student — a language model so extensively trained that it could perform tasks it was never specifically trained on, simply by being given a prompt.
In February 2019, OpenAI published "Language Models are Unsupervised Multitask Learners," introducing GPT-2 — a scaled-up version of 02-gpt-1.md with 10x more parameters and 10x more training data. The paper's central claim was provocative: a sufficiently large language model, trained only to predict the next word, implicitly learns to perform many tasks — translation, summarization, question answering — without ever being explicitly trained on them. This zero-shot capability was not hand-coded or fine-tuned; it emerged from scale.
But GPT-2 is remembered for more than its technical contributions. OpenAI initially withheld the full model, citing concerns about potential misuse for generating disinformation. This staged release — from the smallest (124M) to the largest (1.5B) model over nine months — was the first major public debate about responsible AI release and set precedents that the field still grapples with.
How It Works
GPT-2: Scaling Unlocks Zero-Shot Capabilities
GPT-1 (117M) GPT-2 (1.5B)
┌────────────┐ ┌────────────────────┐
│ Pre-train │ │ Pre-train │
│ + Fine-tune│ │ (NO fine-tuning!) │
│ per task │ │ │
└────────────┘ └────────────────────┘
│ │
▼ ▼
One task at a time Zero-shot task performance via prompts:
"TL;DR:" ──▶ summarization
"Q: ... A:" ──▶ question answering
"English: ... French:" ──▶ translation
Scale Progression:
┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
│ Small │ │ Medium │ │ Large │ │ XL │
│ 117M │ │ 345M │ │ 774M │ │ 1.5B │
│ 12 layers│ │ 24 layers│ │ 36 layers│ │ 48 layers│
└──────────┘ └──────────┘ └──────────┘ └──────────┘
│ │ │ │
weak zero-shot improving better yet genuine zero-shot
capabilitiesFigure: GPT-2 demonstrated that scaling the same architecture 10x unlocked zero-shot task performance through prompt formatting, without any task-specific fine-tuning.
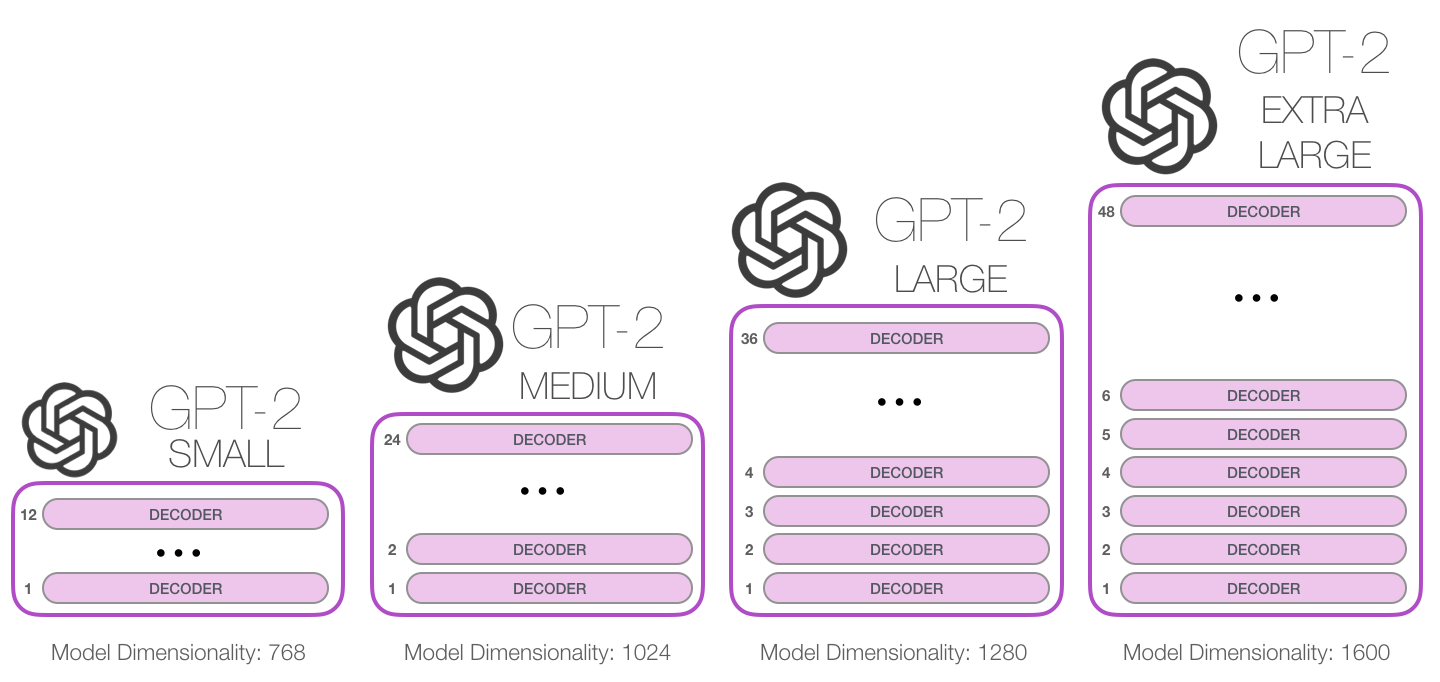 Figure: GPT-2's four model sizes with their respective hyperparameters. (Source: Jay Alammar, "The Illustrated GPT-2")
Figure: GPT-2's four model sizes with their respective hyperparameters. (Source: Jay Alammar, "The Illustrated GPT-2")
Architecture: Scaled GPT-1
GPT-2 used the same decoder-only Transformer architecture as 02-gpt-1.md, with several refinements:
| Model | Layers | d_model | Heads | Parameters |
|---|---|---|---|---|
| GPT-2 Small | 12 | 768 | 12 | 117M |
| GPT-2 Medium | 24 | 1024 | 16 | 345M |
| GPT-2 Large | 36 | 1280 | 20 | 774M |
| GPT-2 XL | 48 | 1600 | 25 | 1.5B |
Architectural changes from GPT-1: layer normalization was moved to the input of each sub-layer (pre-norm, rather than post-norm), an additional layer normalization was added after the final self-attention block, residual layer weights were scaled by 1/sqrt(N) where N is the number of layers, vocabulary expanded to 50,257 tokens, and the context window doubled from 512 to 1024 tokens.
WebText: A New Training Corpus
GPT-1 trained on BookCorpus (~5GB). GPT-2 trained on WebText — a new dataset of 40GB of text from 8 million web pages. The curation process was simple but effective: scrape all outbound links from Reddit posts with at least 3 karma (upvotes), as a proxy for human content quality filtering. Wikipedia was excluded to prevent contamination of evaluation benchmarks. The resulting dataset was significantly more diverse and current than BookCorpus, covering news, blogs, fiction, forums, and more.
The tokenizer used byte-level BPE (Byte Pair Encoding) — a modification that operates on raw bytes rather than Unicode characters. This eliminated the need for any pre-processing, handled any language or character set, and reduced the vocabulary to 50,257 tokens while maintaining good compression.
Zero-Shot Task Performance
The paper's central contribution was demonstrating that GPT-2 could perform tasks without any task-specific training data or fine-tuning. The model was evaluated by formatting tasks as natural language prompts:
- Translation: Prefix the prompt with example pairs like "natural language sentence = translated sentence" and the model would continue the pattern.
- Summarization: Append "TL;DR:" after an article and the model would generate a summary.
- Question answering: Include a passage followed by a question, and the model would produce an answer.
- Reading comprehension: Achieved 55 F1 on CoQA (conversational QA) in zero-shot — competitive with several supervised baselines.
Performance scaled consistently with model size: each larger variant performed better on zero-shot tasks. The 1.5B model achieved 63.24 perplexity on WikiText-103 — state of the art — and improved over GPT-1's fine-tuned results on several tasks despite never being fine-tuned.
The "Emergent" Capabilities
GPT-2 could generate remarkably coherent multi-paragraph text. Given a prompt about a discovered herd of unicorns in the Andes, the model produced a plausible news article with quotes, names, and narrative structure. This long-form coherence, absent in GPT-1, seemed to emerge from scale — the same architecture, just larger. This observation seeded the idea that scaling language models could yield qualitatively new behaviors, an idea that would crystalize into the scaling hypothesis and eventually the study of emergent abilities in llm-concepts/scaling-laws.md.
Why It Matters
The Scaling Hypothesis Takes Shape
GPT-2 was the first major evidence that simply making language models bigger — more parameters, more data — could produce qualitatively new capabilities. GPT-1 needed fine-tuning for each task; GPT-2 could often handle tasks zero-shot. The difference wasn't architectural — it was scale. This observation, extended by GPT-3 and formalized by Kaplan et al. (2020) in the scaling laws paper, became one of the most consequential ideas in modern AI.
The Birth of Prompt Engineering
Because GPT-2 performed tasks based on how the prompt was formatted, the way you asked the question mattered enormously. This was the beginning of prompt engineering — the art and science of crafting inputs to elicit desired model behavior. What seems obvious now was radical then: the interface between human and model was not a training pipeline but a text prompt. This paradigm would fully mature with GPT-3's in-context learning.
The AI Safety Debate
OpenAI's staged release was controversial in both directions. Critics argued it was a publicity stunt — the model wasn't actually dangerous. Supporters argued it set a responsible precedent for powerful AI systems. In practice, the feared flood of machine-generated disinformation didn't materialize after the full release, partly because 2019's models weren't yet good enough and partly because detection tools caught up. But the debate established norms around responsible release that influenced every subsequent model deployment.
Key Technical Details
- Paper: Radford et al., "Language Models are Unsupervised Multitask Learners" (Feb 2019, OpenAI technical report — never peer-reviewed)
- Largest model: 48 layers, 1600 hidden, 25 heads, 1.5B parameters
- Training data: WebText, ~40GB of text from 8M web pages (Reddit links with 3+ karma)
- Tokenizer: Byte-level BPE, 50,257 vocabulary
- Context window: 1024 tokens (doubled from GPT-1's 512)
- Zero-shot WikiText-103 perplexity: 63.24 (SOTA at the time)
- Zero-shot CoQA F1: 55.0 (competitive with several supervised baselines)
- Lambada accuracy: 63.24% zero-shot (the 1.5B model), demonstrating long-range comprehension
- Staged release: 124M (Feb 2019), 345M (May 2019), 774M (Aug 2019), 1.5B (Nov 2019)
- Training cost: Estimated ~250K in compute
Common Misconceptions
-
"GPT-2 was 'too dangerous to release.'" OpenAI's concern was about potential misuse, not that the model was sentient or uncontrollable. The staged release was a precautionary approach to gauge real-world impact. By the time the full model was released in November 2019, no significant misuse had been documented with the smaller models.
-
"GPT-2 could reliably perform any NLP task zero-shot." Zero-shot performance was impressive for the time but still far below fine-tuned models on most benchmarks. The significance was that zero-shot worked at all, not that it was competitive. GPT-3 (175B parameters) would be needed before zero-shot and few-shot performance genuinely rivaled fine-tuning.
-
"GPT-2 generates factually accurate text." GPT-2 generates plausible-sounding text, not accurate text. It confidently produces false statements, fabricated quotes, and invented statistics. The coherence of the output makes the inaccuracies more dangerous, not less — a challenge that persists with all modern LLMs (see
llm-concepts/hallucination.md). -
"The 1.5B parameter model was huge." By current standards, GPT-2 is tiny. GPT-3 was 175B (117x larger). PaLM was 540B. Modern open models like LLaMA 3 run to 405B. GPT-2's 1.5B parameters can now run on a smartphone. The significance was in demonstrating that scaling produces new capabilities, not in the absolute scale.
Connections to Other Concepts
- Direct sequel to
02-gpt-1.md, using the same architecture at 10x scale - Contrasted with
03-bert.md's fine-tuning approach by emphasizing zero-shot capabilities - The zero-shot paradigm influenced
05-t5-text-to-text-framework.md's text-to-text approach - The scaling hypothesis seeded by GPT-2 was formalized in the scaling laws — see
llm-concepts/scaling-laws.md - Prompt engineering pioneered here is now a core skill — see
llm-concepts/prompt-engineering.md - The encoder-vs-decoder debate is explored in
07-encoder-vs-decoder-vs-encoder-decoder.md - The AI safety concerns connect to
llm-concepts/alignment-and-safety.md
Further Reading
- Radford et al., "Language Models are Unsupervised Multitask Learners" (2019, OpenAI) — the GPT-2 paper
- Solaiman et al., "Release Strategies and the Social Impacts of Language Models" (2019, arXiv:1908.09203) — OpenAI's analysis of the staged release decision
- Kaplan et al., "Scaling Laws for Neural Language Models" (2020, arXiv:2001.08361) — formalized the scaling relationships GPT-2 suggested
- Zellers et al., "Defending Against Neural Fake News" (2019, arXiv:1905.12616) — Grover, a model trained to both generate and detect neural fake news
- Brown et al., "Language Models are Few-Shot Learners" (2020, arXiv:2005.14165) — GPT-3, the logical continuation of GPT-2's scaling experiment